AI Didn’t Reduce Engineering Complexity. It Moved It
The pitch for AI in engineering was straightforward: automate the repetitive, accelerate the cognitive, and let engineers focus on higher-order problems. Less time writing boilerplate. Less time provisioning infrastructure. Faster feedback loops. Lower operational overhead.
Some of that happened. But something else happened too — something nobody put in the pitch deck.
The AI systems complexity didn’t disappear. It moved.
And most teams didn’t change how they look for it.

The Promise That Wasn’t Wrong — Just Incomplete
The productivity gains are real. Code generation, automated testing, intelligent routing, semantic search — these tools removed genuine friction from engineering workflows. The pitch was not dishonest.
But it was incomplete. Automating the repetitive parts of engineering does not eliminate complexity. It relocates it. The complexity that used to live in writing code now lives in reviewing model outputs for correctness. The complexity that used to live in provisioning infrastructure now lives in governing model behavior. The complexity that used to live in deterministic failures now lives in probabilistic degradation that produces no stack trace and fires no alert.
The work didn’t go away. It just moved somewhere harder to see.
What Actually Happened
When you add an AI system to your stack, you do not replace complexity with simplicity. You trade one kind for another — and the new kind is harder to detect and harder to attribute when something goes wrong.
The engineer who used to write deterministic business logic now reviews probabilistic model outputs. The team that used to provision infrastructure now governs model behavior. The on-call rotation that used to respond to server alerts now investigates why a system that reports healthy is quietly producing degraded results.
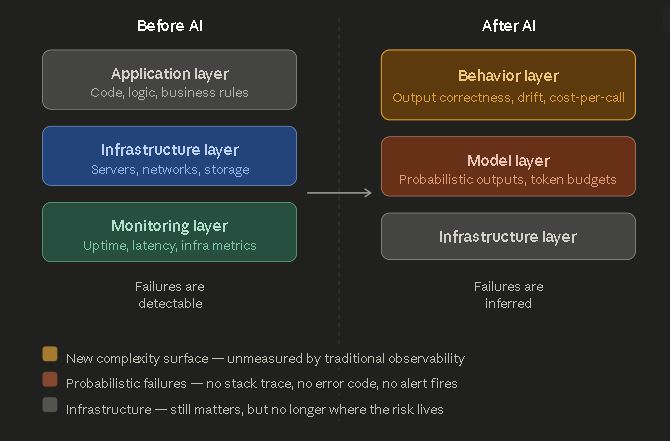
The Shift: Where AI Systems Complexity Lives Now
Traditional software systems fail in predictable ways. A service goes down. Latency spikes. An error rate crosses a threshold. Your monitoring fires. You find the stack trace. You fix the bug. The failure was detectable, locatable, and correctable.
AI systems fail differently. The infrastructure is healthy. The service is responding. The latency is nominal. And the system is producing outputs that are subtly wrong — off-brand, factually degraded, semantically drifted from what it was doing three weeks ago. No alert fires. No threshold is crossed. The failure is in the behavior layer — and your monitoring was never built to see it.
This is the core shift. Complexity moved from layers your tooling understands — uptime, latency, error rates — to a layer your tooling was never designed to instrument: behavior.
The Hidden Layer: Behavior Over Infrastructure
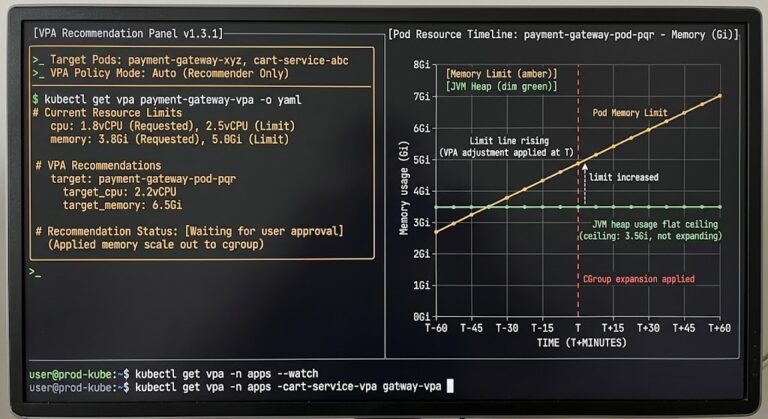
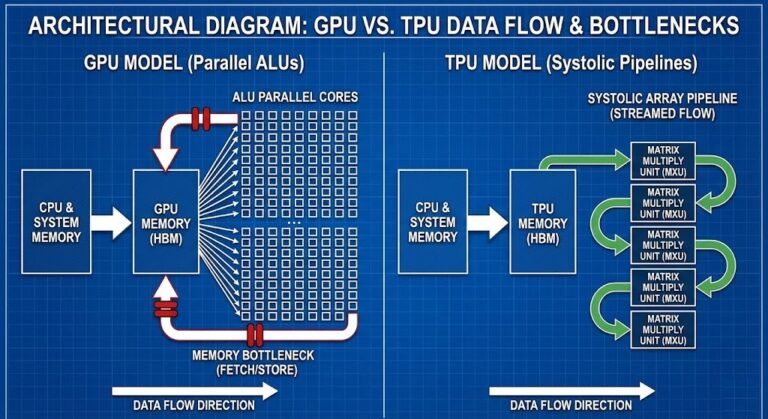
Infrastructure complexity has a known shape. You model it, monitor it, and respond to it with playbooks refined over two decades of distributed systems operations. The AI Inference Cost architecture is a good example of a cost model that looks familiar — until you realize cost is now driven by behavior, not provisioned capacity. A model that produces verbose outputs costs more than one that produces concise outputs, on identical infrastructure, with identical latency. The cost is in the tokens. The tokens are in the behavior.
Drift is the purest expression of this shift. Autonomous systems don’t fail — they drift. Gradually. Silently. The model that was well-calibrated at deployment degrades incrementally as the distribution of real-world inputs diverges from its training distribution. Your infrastructure metrics show nothing. Your users notice before your monitoring does.
Behavior is now the primary risk surface. Infrastructure is just the substrate.
Why Teams Are Missing It
Most engineering teams are still measuring the wrong layer — and trusting those signals.
Not because they are unsophisticated. Because the tooling they inherited was built for a different problem. Prometheus was built for infrastructure metrics. Datadog was built for application performance. Distributed tracing was built to follow a request across services. None of these were built to answer the questions that matter in an AI system: Is this output correct? Is the model drifting? Is cost increasing because behavior changed? Is a degraded user experience hiding behind a healthy HTTP 200?
Three specific blind spots follow from measuring the wrong layer:
Assuming determinism. Traditional systems are deterministic — the same input produces the same output. Engineering intuitions, debugging patterns, and incident response playbooks are all built on this assumption. AI systems are probabilistic. The same input produces a distribution of outputs. A system that worked in testing can fail in production not because anything changed in the infrastructure, but because the input distribution shifted into a region the model handles poorly. No runbook was written for that failure mode — because the failure mode did not exist before.
Treating models like services. A microservice has a contract. It accepts defined inputs, produces defined outputs, and fails loudly when it cannot. A model has a behavior profile — a statistical tendency to produce outputs in a certain range under a certain input distribution. That profile is not a contract. It degrades without notice, drifts without alerting, and fails silently in ways that look like business problems before they look like engineering problems. The 200 OK is the new 500 documents exactly this failure mode: the system reports healthy while the outputs are quietly broken.
Cost attribution blindness. Infrastructure cost is straightforward to attribute — compute, memory, storage, egress. Behavior-driven cost is invisible to standard FinOps tooling. A prompt that consistently generates 2,000-token responses costs four times more than one that generates 500-token responses, on identical infrastructure, with identical latency. The AI Inference Cost series documents how teams discover this only when the bill arrives — because no alert was configured for token consumption per output, because that metric did not exist in their monitoring stack.
What Breaks in Production
These are not theoretical failure modes. They are documented production patterns of teams that shipped AI systems without updating their observability posture.
Cost explosions with no infrastructure anomaly. A change in prompt behavior — a slightly more verbose system prompt, a shift in user query patterns, a model update that produces longer completions — drives a 40% cost increase with zero corresponding change in infrastructure metrics. The standard cost runbook finds nothing. The behavior layer was never instrumented.
Silent semantic failures. A RAG system that was accurately retrieving relevant context begins hallucinating with increasing frequency as the vector index grows stale. Response latency is nominal. Error rates are zero. The failure is in output correctness — a dimension that requires semantic evaluation to measure, not threshold monitoring.
Degraded UX behind healthy systems. A recommendation system begins surfacing lower-quality results as the model drifts from its calibrated state. User engagement declines. Engineering sees nothing wrong in their dashboards. The Kubernetes Day-2 failure patterns document exactly this dynamic at the orchestration layer — the symptom is always somewhere other than the cause.
Drift that compounds over weeks. Small degradations accumulate silently until a threshold is crossed that cannot be incrementally recovered from. AI systems drift in the same pattern as autonomous infrastructure systems — but faster, less visibly, and with less obvious recovery paths.
The Real Problem: We’re Measuring the Wrong Things
Observability was built for the infrastructure era. The three pillars — metrics, logs, traces — answer: Is the system up? Is it fast? Where did the request go?
They do not answer: Is the output correct? Is the model drifting? Is cost increasing because behavior changed? Is user experience degrading without any infrastructure signal?
AI systems require a fourth observability layer the industry has barely begun to build:
Evaluation pipelines that assess semantic quality, factual accuracy, and task completion — not HTTP status codes. Correctness is not a metric your infrastructure emits.
Statistical comparison of current output distributions against calibrated baselines. Drift surfaces here weeks before it becomes user-visible — if you are watching this layer at all.
Token consumption attributed to specific output patterns, not aggregated across infrastructure resources. A prompt that generates 2,000-token responses costs four times more than one that generates 500 — on identical infrastructure, with identical latency.
Alerting on changes in output characteristics — length, confidence, topic distribution — that precede detectable quality degradation. The signal exists before the failure. Most teams are not collecting it.
The inference observability post covers what to instrument first. The gap between what most teams are measuring and what AI systems actually require is the gap where silent failures live.
What This Means for System Design
If complexity has moved, system design has to follow it.
AI systems cannot be treated as stateless services with better interfaces. They require a fundamentally different operational posture — one built around behavior, not infrastructure.
The Platform Engineering Architecture pillar covers how the internal developer platform layer needs to evolve to make these capabilities accessible to teams that cannot build them from scratch. The golden path for AI workloads looks different from the golden path for stateless services — and most internal platforms have not been updated to reflect that.
The architecture did not get simpler. The abstraction layer changed.
Architect’s Verdict
The industry adopted AI faster than it updated its operational model. The tooling, the runbooks, the on-call intuitions, the monitoring dashboards — all of it was built for deterministic systems that fail loudly. AI systems are probabilistic systems that fail quietly.
Complexity did not leave the stack. It moved to the one layer most teams are not watching.
AI didn’t make engineering simpler. It made failure quieter.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session