The Backup Rehydration Bottleneck: Why Your Deduplication Engine Is Killing Your RTO
Data protection is the only discipline in IT where you can do everything right and still fail spectacularly during a disaster. The backup rehydration bottleneck is a perfect example — you can check every box, follow every “best practice,” and still end up with nothing when things go sideways.
You hit your backup windows. You replicate offsite. You stash everything in those shiny, immutable vaults. And yet, when disaster actually hits, all that work can mean squat. Physics just doesn’t care about compliance checklists.
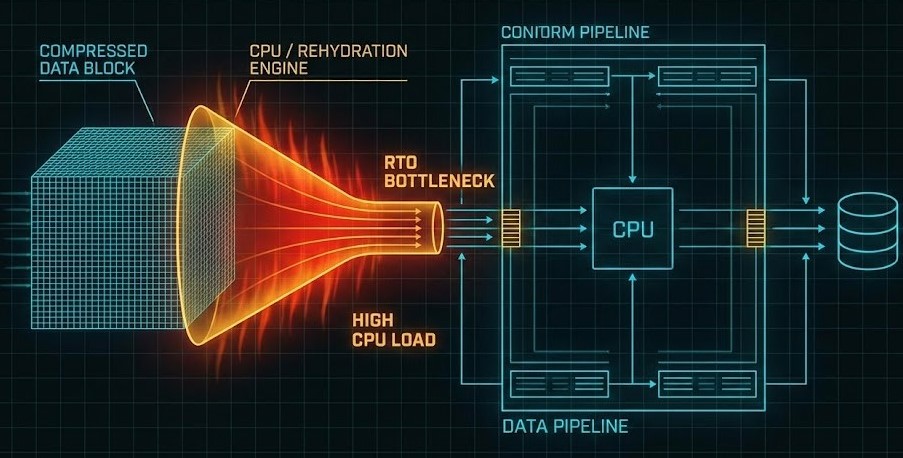
Hiding under all that storage efficiency is what I call a “rehydration tax.” It’s a hidden cost, a kind of computational debt that only shows up when you actually need your backups. Suddenly, your fast recovery plan is crawling. This is the backup rehydration bottleneck — and it’s why your RTO isn’t just optimistic, it’s flat-out lying to you.
The Capacity Trap: When Efficiency Bites Back
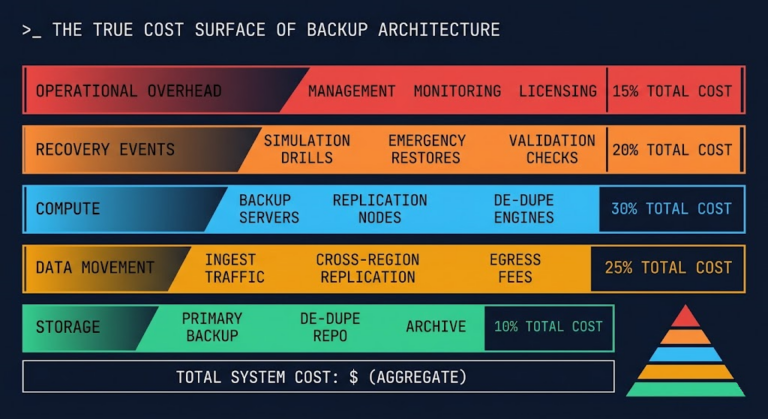
We’ve all seen the vendor slides. “Fit a petabyte on a couple high-density drives! Get a 20:1 reduction ratio!” Looks amazing on your CapEx report. You follow the 3-2-1-1-0 backup rule. You build those immutable silos. Everything looks perfect.
Then the real world shows up.
Maybe your whole site goes dark. Maybe ransomware detonates across everything you own. You smash the big red button. Disaster recovery time.
And now the curtain gets pulled back.
Your storage arrays? Doing nothing. Network pipes? Wide open. But your restores crawl along at 50 MB/s. Meanwhile, your backup server’s CPU is pegged at 100%, stuck doing math instead of getting your business back online.
This is the rehydration bottleneck. The moment your “efficient” storage engine turns into your biggest liability.
Here’s the hard truth: During an outage, restore speed is all that matters. Deduplication hides a ticking time bomb.
The Backup Rehydration Bottleneck: Why Deduplication Cripples Mass Restores
Deduplication is clever—until you need to restore a lot of data, all at once.
When you back up, your data gets chopped up, deduped, and mapped with pointers. Restoring it is a massive scavenger hunt. The system has to chase pointers all over the place, pull scattered blocks together, piece them back in memory, and decompress everything—just to make it usable.
Try that at scale and the pointer table turns into gridlock. Random I/O destroys your nice, fast throughput. Even with good disks and fat pipes, the CPU becomes the bottleneck.
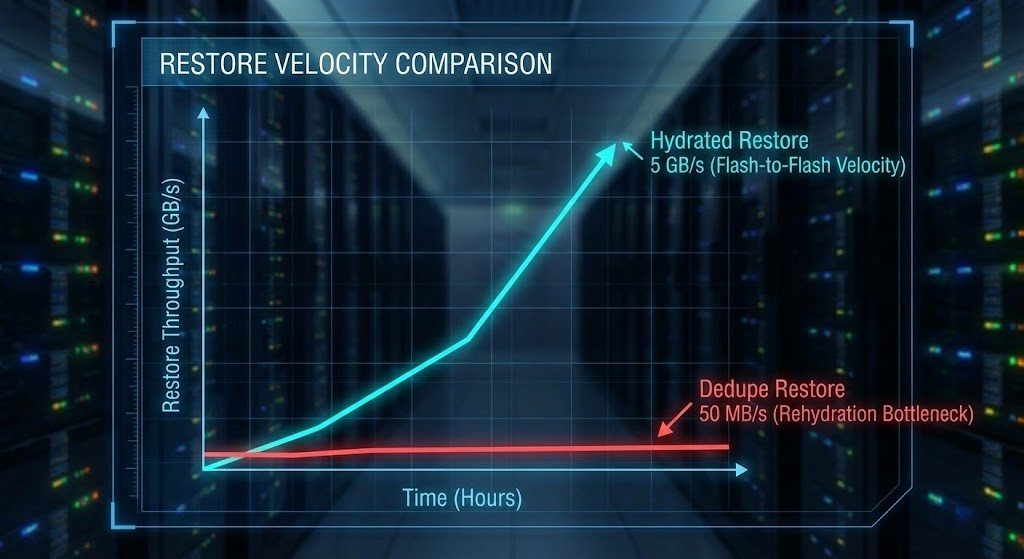
Look at the numbers:
| Restore Type | Data Size | Storage Tier | Deduped? | Avg CPU Load | Restore Throughput |
| Single VM | 1 TB | SSD | Yes | 40% | 400 MB/s |
| Mass Restore | 100 TB | SSD | Yes | 100% (Pinned) | 50 MB/s |
| Mass Restore | 100 TB | Flash Landing Zone | No (Hydrated) | 30% | 5 GB/s |
If your backup architecture strategy treats a 1 TB restore the same as a 100 TB restore, you’ve already lost. You just haven’t noticed yet.
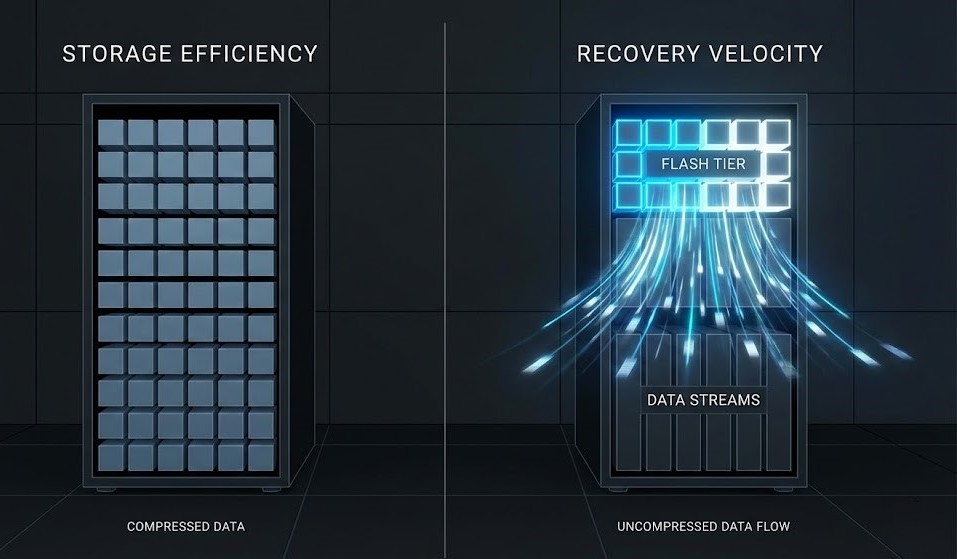
Real Solutions: Build Hydrated Landing Zones
You want to survive a real disaster? Stop optimizing for capacity. Start optimizing for physics.
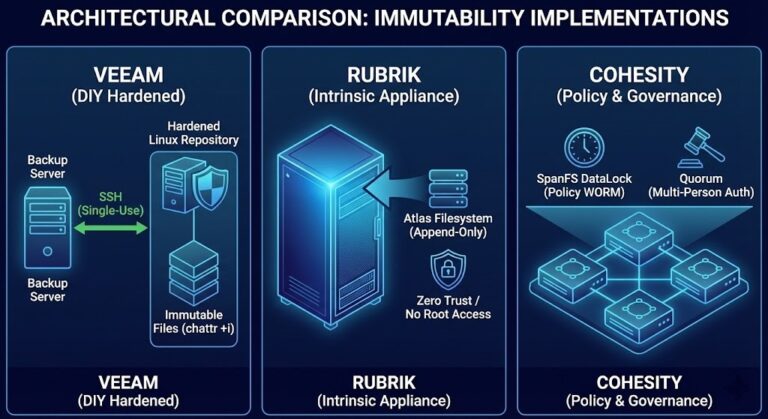
You need a Hydrated Landing Zone—basically, a tier of uncompressed, non-deduped flash storage where your critical workloads sit, ready to restore at full speed. Domain controllers, SQL clusters, ERP, identity systems, stuff that keeps the lights on. This is the difference between “we’re restoring” and “we’re back.”
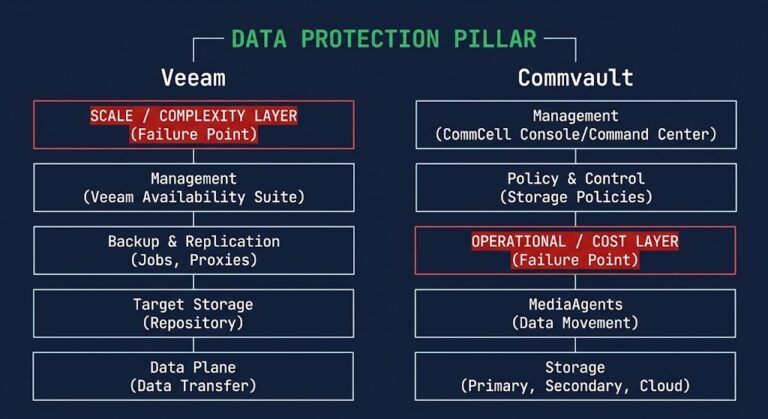
A modern data protection architecture balances speed, cost, and survivability with a Flash-to-Flash-to-Cloud (F2F2C) design. Your latest recovery points? Hydrated, on flash. Long-term backups? Deduped and compressed, in cheap storage. Immutable, offsite copies? Parked in the cloud. Deduplication isn’t gone; it’s just kept where time doesn’t matter.
Day 2: Making It Work When Things Break
Designing the architecture is just the first step. Making sure it holds up in a real disaster? That’s where it gets real.
- Sizing: Backup appliances must be sized for restore storms, not marketing demos. You need enough CPU and RAM to survive a rehydration storm.
- Fabric: The network between landing zones and primary storage has to be low-latency, high-throughput.
- Orchestration: Don’t wait for disaster—move critical data out of deduped storage and into landing zones ahead of time, with automation, not manual panic.
- Validation: Stop doing one-VM restore tests. Only full-scale, mass-recovery drills really show you whether rehydration is going to choke your recovery.
Architect’s Verdict: Respect the Physics
Storage efficiency looks great on slides, but it’s worthless if it kills your recovery.
Mission-critical workloads need to be hydrated, flash-first, and instantly restorable. Archive data? Fine, keep it deduped and compressed. But test restores under real pressure, because if your RTO hasn’t been proven at scale, it’s just a fantasy.
Build for reality: Hydrated Landing Zones, F2F2C, flash-first. If you’re not designing for real restores, you’re not an architect—you’re just selling cheap disks.
Your RTO isn’t up for debate. Deduplication is optional. Speed is mandatory.
Start the data protection resiliency learning path and check your own hydration risk. Don’t wait to find out the hard way.
Additional Resources
The concepts discussed here are grounded in established storage architecture principles and industry research. For deeper technical validation, review the following resources:
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session