-
-
Your Monitoring Didn’t Miss the Incident. It Was Never Designed to See It.
I’ve watched observability vs monitoring play out as a live incident more times than I can count. The dashboard was green. The on-call engineer was not paged. The monitoring system did exactly what it was designed to do — it watched for thresholds, waited for metrics to cross them, and stayed silent when they didn’t….
-
AI Didn’t Reduce Engineering Complexity. It Moved It
The pitch for AI in engineering was straightforward: automate the repetitive, accelerate the cognitive, and let engineers focus on higher-order problems. Less time writing boilerplate. Less time provisioning infrastructure. Faster feedback loops. Lower operational overhead. Some of that happened. But something else happened too — something nobody put in the pitch deck. The AI systems…
-
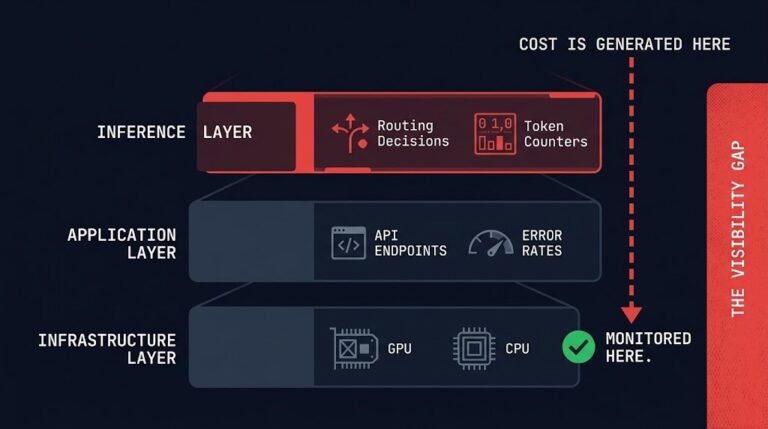
Inference Observability: Why You Don’t See the Cost Spike Until It’s Too Late
>_ AI Inference Cost — Series Part 1 — Cost Architecture AI Inference Is the New Egress: The Cost Layer Nobody Modeled Part 2 — Execution Budgets Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits. Part 3 — Model Routing Cost-Aware Model Routing in Production: Why Every Request Shouldn’t Hit…
-
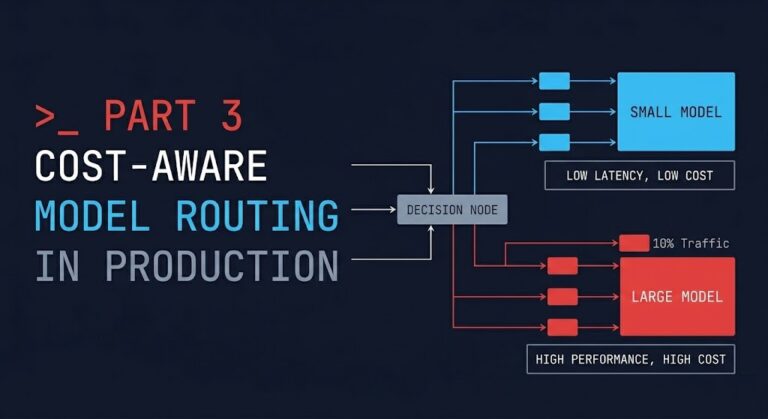
Cost-Aware Model Routing in Production: Why Every Request Shouldn’t Hit Your Best Model
>_ AI Inference Cost — Series Part 1 — Cost Architecture AI Inference Is the New Egress: The Cost Layer Nobody Modeled Part 2 — Execution Budgets Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits. ▶ Part 3 — Model Routing (You Are Here) Cost-Aware Model Routing in Production: Why…
-
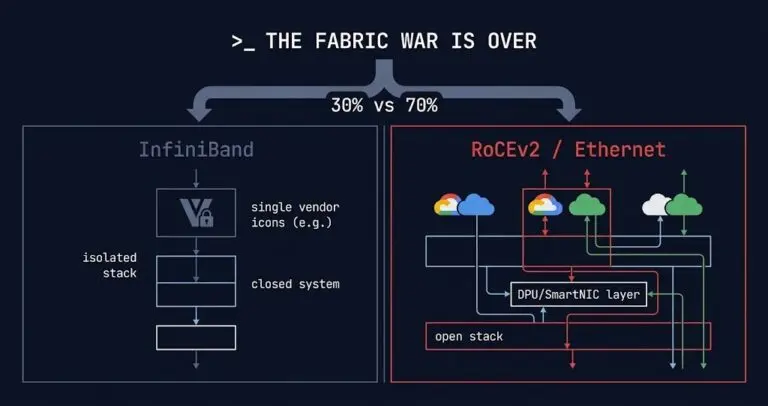
InfiniBand Is Losing the Fabric War. Here’s What That Changes for Your Architecture.
The InfiniBand vs RoCEv2 decision has been settled at the hyperscaler level — and the answer is Ethernet. Broadcom’s March 2026 earnings confirmed what most AI infrastructure architects had already suspected: roughly 70% of new AI infrastructure deployments are now choosing Ethernet-based fabrics over InfiniBand. That number is worth sitting with for a moment —…
-
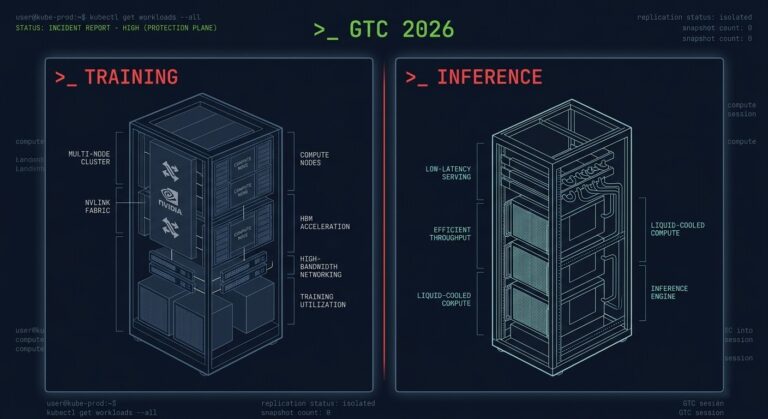
The Training/Inference Split Is Now Hardware — What GTC 2026 Actually Changed
The inference infrastructure decision most teams are ignoring isn’t the Vera Rubin GPU. It was not the $1 trillion demand forecast. It was not Jensen Huang calling NVIDIA “the inference king.” The announcement that matters is the Groq 3 LPX — a dedicated inference rack shipping alongside the GPU rack. For the first time, NVIDIA…
-
Autonomous Systems Don’t Fail. They Drift Until They Break.
Autonomous systems drift before they fail. Software fails loudly. A service crashes. An API returns 500. A pod restarts. The alert fires. You respond. Autonomous systems don’t work that way. They degrade quietly. They drift. They accumulate small deviations — a few extra tokens here, one more model call there, a retry loop that fires…
-
Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits.
>_ AI Inference Cost — Series Part 1 — Cost Architecture AI Inference Is the New Egress: The Cost Layer Nobody Modeled ▶ Part 2 — Execution Budgets (You Are Here) Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits. Part 3 — Model Routing Cost-Aware Model Routing in Production: Why…
-
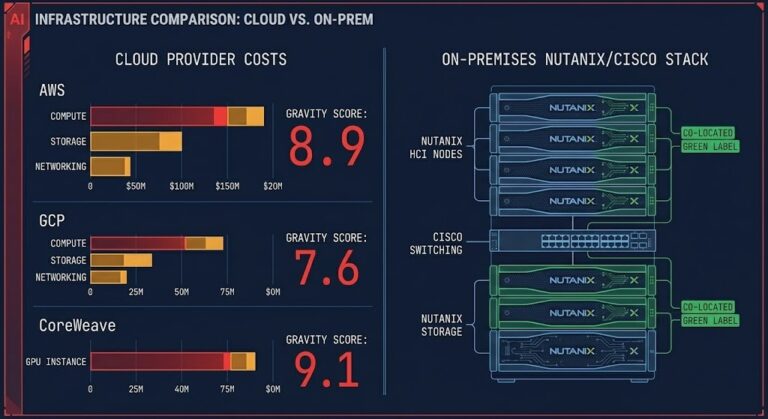
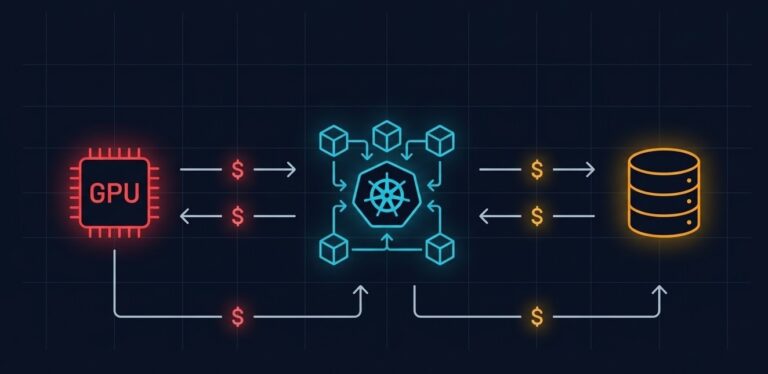
AI Inference Is the New Egress: The Cost Layer Nobody Modeled
>_ AI Inference Cost — Series ▶ Part 1 — Cost Architecture (You Are Here) AI Inference Is the New Egress: The Cost Layer Nobody Modeled Part 2 — Execution Budgets Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits. Part 3 — Model Routing Cost-Aware Model Routing in Production: Why…