GCP CLOUD ARCHITECTURE
THE SOFTWARE-DEFINED INFRASTRUCTURE MANUAL. DATA-NATIVE BY DESIGN.
AWS abstracts infrastructure into services. GCP abstracts infrastructure into systems.
That distinction is not marketing. It is the architectural consequence of GCP’s origin. Google Cloud Platform is not a general-purpose enterprise cloud built to capture market share. It is Google’s internal software-defined infrastructure — the same fabric that runs Search, Gmail, YouTube, and Maps — exposed externally and made available to architects who are willing to engage with it on its own terms.
Those terms are specific. GCP is optimized for distributed systems, data platforms, and Kubernetes-native workloads. Its global network is not a feature you configure — it is the foundation the entire platform runs on. Its data stack — BigQuery, Pub/Sub, Dataflow, Vertex AI — is not an assembly of acquired products bolted together. It is an integrated system where data flows between components without leaving the platform fabric. Its Kubernetes implementation is not a managed port of the open-source project. It is Kubernetes as Google runs it internally, with the operational intelligence of the team that built it baked in.
Organizations that treat GCP as a cheaper AWS alternative consistently underperform on every dimension. They miss the network advantage. They miss the data platform integration. They manage GKE like self-managed Kubernetes and wonder why the operational overhead doesn’t improve. The mental model is wrong, and the wrong mental model produces the wrong architecture.
This GCP cloud architecture guide covers how the platform actually works — the global network fabric, the resource hierarchy, the data platform integration, GKE as a reference implementation, and the cost physics that make GCP genuinely different from AWS in ways that matter for specific workload classes.
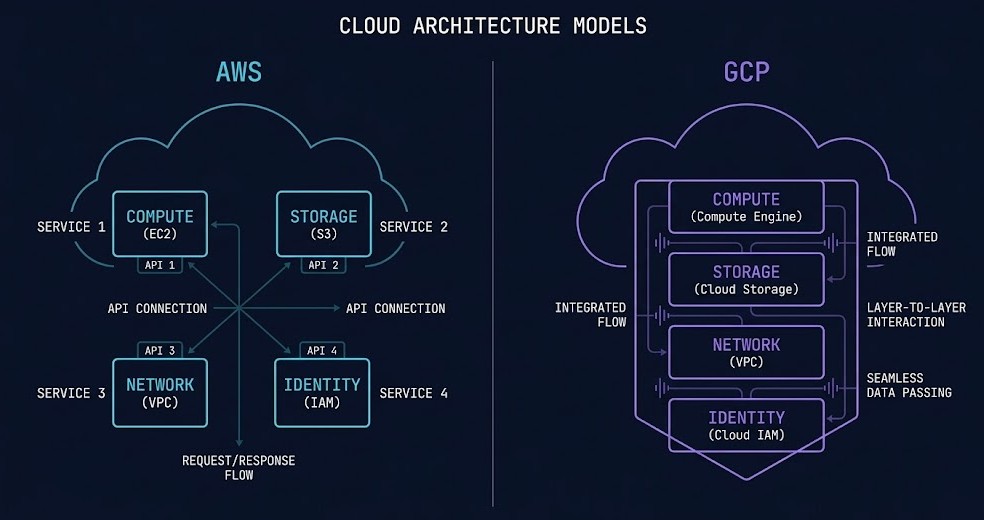
What GCP Architecture Actually Is
GCP’s architectural model is built on four primitives that differ meaningfully from AWS. Understanding these is the prerequisite for everything else on this page.
Projects are both the isolation boundary and the billing boundary. In AWS, the account is the isolation unit. In GCP, the project is lighter, faster to create, and directly tied to billing. Every GCP resource — a Compute Engine VM, a GKE cluster, a BigQuery dataset — belongs to exactly one project. Access to that resource is governed by IAM policies attached to the project. The project is where the architecture starts, not an afterthought.
APIs must be explicitly enabled. This is one of the most GCP-specific architectural concepts and one of the most consistently skipped in GCP guides. In GCP, if a service API is not enabled for a project, that service functionally does not exist in that project. Cloud Storage API, Compute Engine API, Kubernetes Engine API — all must be explicitly enabled before any resource of that type can be created. This is an architectural gating mechanism, not an administrative checkbox. It means that a project’s enabled APIs are a declarative surface of what that project is allowed to do. IaC modules that provision GCP environments must enable APIs as a first-class step, not an afterthought. Environments with disabled APIs that teams expect to be available are one of the most common sources of silent provisioning failures.
Quotas are part of the design. GCP enforces per-project, per-region quotas on almost every resource type — vCPU count, persistent disk size, IP address allocation, API request rate. Unlike AWS where limits are soft defaults you adjust reactively, GCP quotas require proactive planning. An architecture that fails to model quota requirements against project-level limits will hit capacity walls at the worst possible time — during a scale event, not during a planning review. Quota requests require Google approval and can take time to process. For large-scale deployments, quota planning belongs in the architecture document, not the runbook.
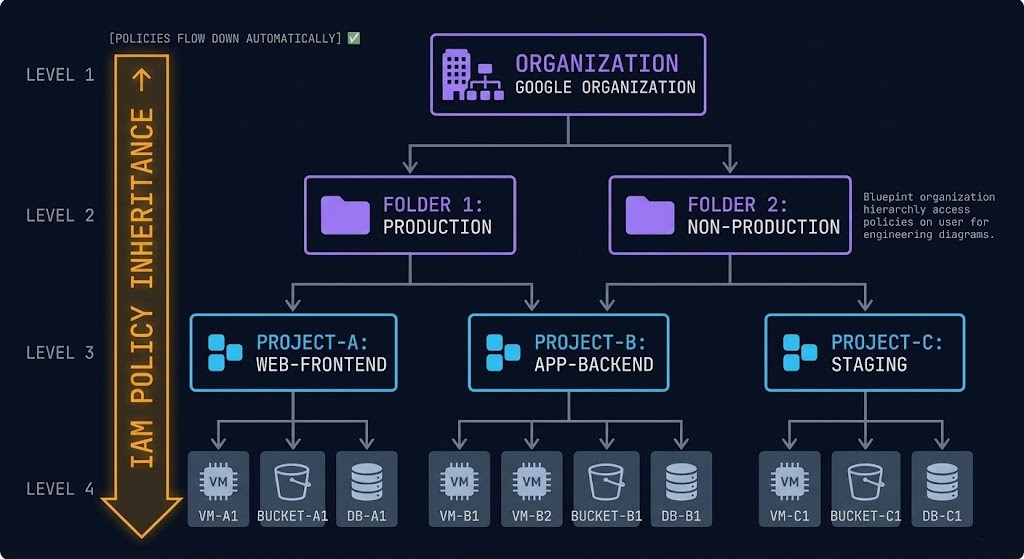
The resource hierarchy is GCP’s governance backbone. GCP organizes resources in a four-level hierarchy: Organization → Folder → Project → Resource. Policies set at the Organization level propagate down to every Folder, Project, and Resource beneath it. Policies set at the Folder level apply to every Project in that Folder. This inheritance model means that governance in GCP is significantly more centralized than in AWS, where account-level guardrails require explicit SCP configuration in Organizations. In GCP, an Organization Policy that prevents public IP assignment applies to every project in the organization without per-project configuration. The architectural implication: org-level design matters more in GCP than in AWS. Getting the Folder and Project structure right at the start is significantly easier than retrofitting governance onto a flat project landscape after the fact.
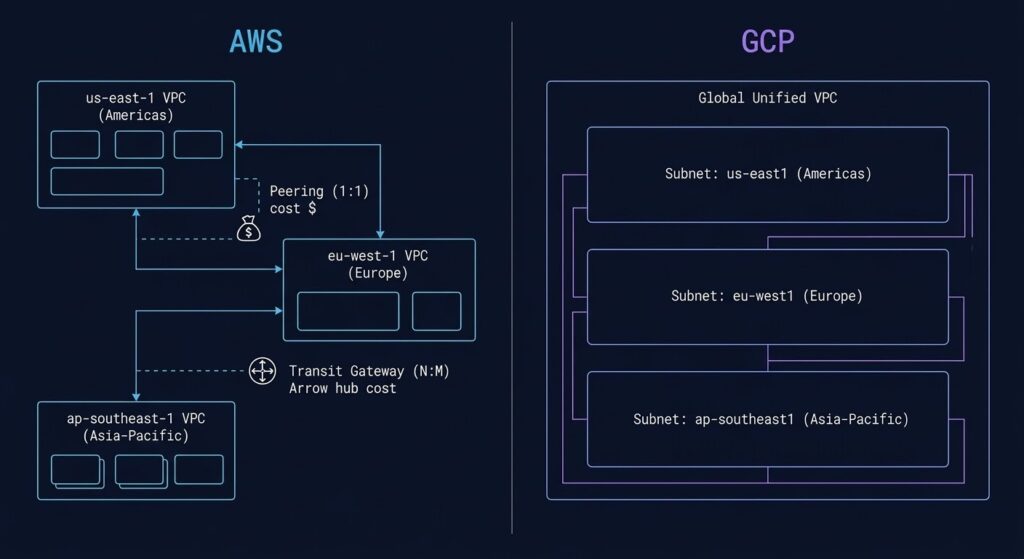
The Global Network Advantage
In GCP, the network is not a layer you build on top of. It is the platform.
Google operates one of the largest private network infrastructures on the planet. The Andromeda software-defined networking stack controls virtual network functions at scale. The Jupiter switching fabric connects Google’s data centers with petabit-scale bandwidth. Together they form the physical substrate that GCP’s global VPC runs on — and they are what makes GCP’s network claims architecturally substantive rather than marketing language.
The difference between GCP and AWS networking is not a matter of configuration complexity. It is a matter of architectural model.
| Dimension | AWS | GCP |
|---|---|---|
| VPC scope | Regional — one VPC per region, peering required for cross-region | Global — one VPC spans all regions natively |
| Cross-region routing | Explicit architecture required — Transit Gateway, peering, or public internet | Native — subnets in different regions share the same VPC routing table |
| Traffic path (default) | Hot potato — exits to public internet at nearest AWS edge | Premium Tier: cold potato — stays on Google backbone to destination |
| Routing management | Customer-defined routing tables, explicit configuration at each layer | Google-managed global routing with customer-controlled firewall rules |
| Cross-region cost trap | Cross-AZ and cross-region data transfer is metered at each hop | Global VPC eliminates many cross-zone cost traps present in AWS architectures |
Premium Tier vs Standard Tier — a decision with architectural consequences. GCP offers two network service tiers. Premium Tier routes traffic on Google’s private backbone from source to destination — cold potato routing that keeps packets off the public internet and delivers the latency and reliability of Google’s internal network. Standard Tier routes traffic on the public internet after the first Google edge — the same hot potato model every other cloud uses. Standard Tier is cheaper. It is also slower, less reliable, and eliminates the core network advantage that GCP’s architecture is built on. Organizations that choose Standard Tier to reduce costs are effectively paying GCP prices to get non-GCP network performance. For latency-sensitive workloads, global services, and data platform architectures where network performance directly affects pipeline throughput, Premium Tier is not optional — it is the correct architectural default. Standard Tier is appropriate for development environments and non-production workloads where latency and reliability are not design constraints.
GCP’s global VPC also eliminates many of the cross-zone and cross-region cost traps that compound in AWS architectures. In AWS, traffic between AZs within a region is metered at $0.01/GB in each direction — a cost that accumulates significantly in microservice architectures with high inter-service call volumes. In GCP, traffic between zones in the same region is significantly cheaper, and the global VPC model means that services in different regions can communicate without the Transit Gateway attachment fees and routing complexity that AWS multi-region architectures require.
Core Building Blocks
GCP’s service catalogue spans hundreds of managed services. Most production architectures run on a much smaller set of primitives. These are the six that every GCP architecture rests on.
IAM — Identity as the Authorization Fabric
GCP Identity and Access Management is the central authorization layer for every API call in the platform. Every action — creating a VM, reading a Cloud Storage object, querying a BigQuery dataset — is an IAM authorization decision. The IAM model in GCP has a critical distinction from AWS: roles are the unit of permission, not policies attached to resources. GCP provides three categories of roles. Primitive roles — Owner, Editor, Viewer — are the oldest and broadest. They grant sweeping permissions across all services in a project and should never be used in production environments. They exist for convenience in development contexts and as a migration path from early GCP implementations. Predefined roles are Google-managed, service-specific roles that grant the minimum permissions required for a specific function. Custom roles allow precise permission sets scoped to exactly the actions a service account or user requires.
Service accounts are the identity mechanism for non-human workloads — VMs, GKE pods, Cloud Functions, and any automated process that needs to call GCP APIs. Service account key sprawl — the accumulation of downloaded JSON key files that are embedded in application code, stored in environment variables, or committed to source control — is the GCP equivalent of leaked AWS access keys, and often harder to detect. The correct architecture uses Workload Identity (for GKE workloads), the metadata server (for Compute Engine), or short-lived tokens rather than long-lived key files. Downloaded service account keys should be treated as a security incident waiting to happen, not a convenience.
Global VPC — One Network, All Regions
A GCP Virtual Private Cloud is a global construct. Unlike AWS VPCs which are regional and require explicit peering or Transit Gateway for cross-region communication, a single GCP VPC spans all regions. Subnets define regional IP ranges, but the routing table is unified. A VM in us-central1 and a VM in europe-west1 can communicate within the same VPC without any additional configuration. This is not a minor operational convenience — it is a fundamental architectural difference that eliminates an entire category of networking complexity that AWS architects spend significant time managing.
Firewall rules in GCP are applied at the network level, not the subnet level. They are stateful and evaluated against source and destination tags or service account identities rather than IP ranges. This identity-based firewall model means that security policies follow workloads as they scale, rather than requiring IP-range updates as environments grow.
Compute Engine — Live Migration as a Platform Feature
Compute Engine VMs run on Google’s custom hypervisor with one operationally significant differentiator: live migration. When Google needs to perform maintenance on the physical host running your VM — hardware repairs, security patches, system updates — Compute Engine migrates the VM to a different host transparently, without rebooting. This is not a customer-configured option. It is the default behavior for standard VM types. The operational consequence is that host maintenance events that cause VM reboots in other cloud environments are invisible on GCP. For workloads where availability during maintenance windows matters, this is a genuine reliability advantage built into the platform rather than an architecture you construct.
Custom machine types allow precise CPU and memory sizing rather than forcing workloads into predefined instance shapes. An application that needs 6 vCPUs and 20GB RAM does not need to overprovision to the nearest standard instance size. This reduces the waste that comes from fitting workloads to instance families rather than sizing instances to workloads.
Cloud Storage — Object Storage with Global Consistency
Cloud Storage is GCP’s foundational object storage service — strongly consistent, globally accessible, and designed around storage class optimization. Unlike S3 where storage class transitions require lifecycle policy configuration and retrieval costs vary by class, Cloud Storage’s Autoclass feature automatically transitions objects between storage classes based on access patterns without manual policy management. For datasets with mixed or unpredictable access patterns, Autoclass reduces storage costs without requiring the operational overhead of lifecycle policy design.
Multi-region and dual-region storage options provide geographic redundancy with automatic replication managed by Google. For data that needs to survive a regional failure without manual replication configuration, multi-region storage eliminates the cross-region replication architecture that S3-based systems require.
Pub/Sub — The Connective Tissue of the Data Platform
Cloud Pub/Sub is GCP’s global, fully managed event streaming service. It is the architectural connective tissue that connects data sources to processing pipelines to analytics systems. Every message published to a Pub/Sub topic is durably stored until acknowledged by all subscribers. Topics are global — a publisher in one region and a subscriber in another communicate through the same topic without regional routing configuration.
Pub/Sub is not simply a message queue. It is the foundation of GCP’s event-driven architecture model. Cloud Storage events, Compute Engine lifecycle events, BigQuery streaming inserts, and Dataflow pipeline inputs all flow through Pub/Sub. Understanding Pub/Sub as a platform primitive — rather than a standalone service — is prerequisite to understanding how GCP’s data platform integrates. Its role becomes clearer in the Data Platform section below.
GKE — Kubernetes as Google Runs It Internally
Google Kubernetes Engine is not managed Kubernetes in the sense of “we run the control plane so you don’t have to.” It is Kubernetes as Google runs it internally — with the operational intelligence, release management, and networking integration of the team that built the platform in the first place. The GKE section below covers this in the depth it deserves.
Data Platform Architecture
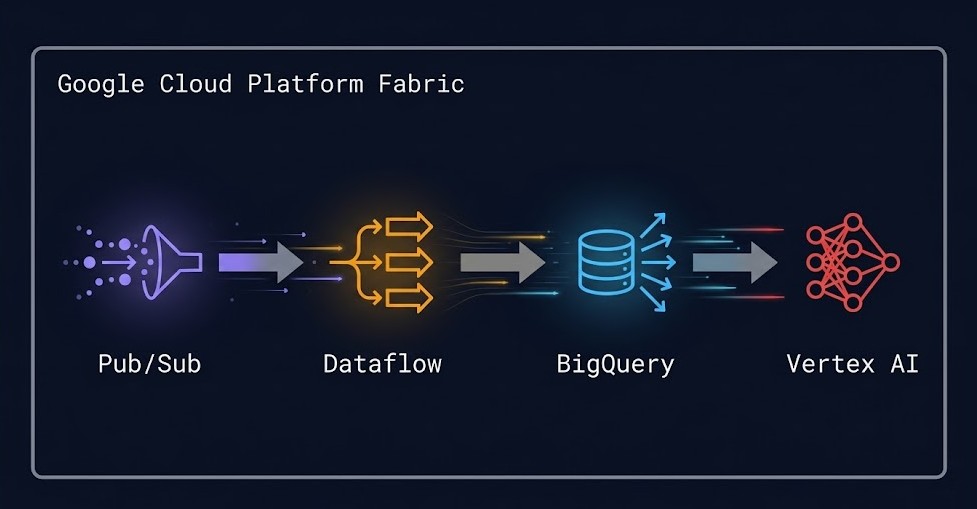
GCP is the only cloud where analytics, streaming, and machine learning form a native, integrated architecture — not a stitched-together stack of acquired products.
On AWS, the equivalent data platform is assembled from S3 for storage, Kinesis for streaming, Glue or EMR for processing, and SageMaker for ML. Each service has its own operational model, its own billing dimension, its own IAM configuration, and its own failure surface. Data moves between services across API boundaries. The integration works, but it is composed, not native.
On GCP, the data platform is a system. BigQuery, Pub/Sub, Dataflow, and Vertex AI are designed to work together. Data flows between them without leaving the platform fabric. The IAM model is consistent across all four. The network path between them stays on Google’s backbone. The operational model for each service integrates with the same resource hierarchy that governs every other GCP resource.
BigQuery — Serverless Analytics at Petabyte Scale
BigQuery is the most architecturally distinctive service in the GCP catalogue. It is a serverless analytics engine — there is no cluster to provision, no node count to configure, no capacity to reserve before running queries. You store data. You query it. Google handles the compute.
The pricing model reflects this architecture: compute and storage are separated. You pay for storage at rest and for the bytes scanned by each query. A petabyte dataset sitting in BigQuery costs storage fees only — no idle cluster, no minimum reservation, no hourly charge for capacity you’re not using. The architectural consequence is significant: BigQuery changes how you think about data retention and analytics pipeline design. Data you would archive or delete in a traditional data warehouse because of storage-plus-compute costs can be retained in BigQuery because the cost of storing it without querying it is minimal. Historical analysis becomes cheaper than purge management.
Columnar storage, automatic partitioning, and clustering allow query costs to be reduced by orders of magnitude through schema design rather than infrastructure tuning. A query that scans a full petabyte table costs significantly more than the same query against a partitioned and clustered table that scans 50GB of relevant data. The architecture of the data itself determines the cost of operating it — a design consideration that has no equivalent in provisioned data warehouse models.
Dataflow — Unified Batch and Streaming
Dataflow is GCP’s fully managed data processing service built on Apache Beam. The architectural significance of the Beam model is the unification of batch and streaming under a single programming model. The same pipeline code that processes a day’s worth of historical data in batch mode can process real-time events in streaming mode without architectural changes. For organizations building data platforms that need to operate on both historical and real-time data, this eliminates the common pattern of maintaining two separate codebases and two separate infrastructure stacks for batch and streaming.
Dataflow integrates natively with Pub/Sub for stream ingestion, BigQuery for analytics output, and Cloud Storage for batch input and output. The data flow from ingestion to processing to analytics happens within the platform fabric, without the inter-service data movement costs and latency that cross-service pipelines on other clouds incur.
Vertex AI — ML Where the Data Lives
Vertex AI is GCP’s unified ML platform covering model training, experiment tracking, model serving, and ML pipeline orchestration. Its architectural position in the GCP data platform is specific: because the training data is already in BigQuery or Cloud Storage, and because the feature store integrates with both, model training in Vertex AI does not require moving data out of the platform to a separate ML environment. The data stays where it lives. The compute comes to the data.
For organizations where ML is a core business function rather than an experimental capability, this integration eliminates one of the most operationally expensive aspects of ML infrastructure — the data pipeline that moves training data from a data warehouse into an ML training environment. On GCP, that pipeline is a configuration, not an infrastructure project.
The Integration Advantage
The data platform integration creates a compounding architectural advantage that is difficult to replicate on other clouds. A streaming event arrives via Pub/Sub. Dataflow processes it and writes results to BigQuery. A Vertex AI model queries BigQuery for feature data and produces a prediction. The prediction triggers a Cloud Function that publishes the result back to Pub/Sub for downstream consumption. This entire pipeline runs within GCP’s platform fabric — on Google’s private backbone, under a consistent IAM model, within a single resource hierarchy. The operational surface area for this pipeline on GCP is significantly smaller than the equivalent architecture assembled from separate AWS services. That difference compounds as the pipeline grows in complexity and scale.
Shared Responsibility In GCP
Google manages the security of the cloud: physical data center infrastructure, the hardware lifecycle, the Andromeda and Jupiter network fabric, and the managed service software stack for services like GKE, BigQuery, and Cloud SQL. Customers manage security in the cloud: IAM configuration, service account governance, data encryption, network traffic controls, and application-level security.
The distribution of where GCP security incidents actually originate follows a consistent pattern that most GCP guides underemphasize.
Service account key sprawl deserves specific attention because it is both extremely common and extremely difficult to detect retroactively. A service account key downloaded as a JSON file and embedded in an application does not expire by default. It does not appear in Cloud Audit Logs unless it is used. It can be copied, committed to source control, included in a Docker image, or forwarded to a third party without any platform-level alert. Organizations that discover they have hundreds of active service account keys with no record of where they were distributed are not unusual — they are the norm in GCP environments that grew without a service account governance policy. The correct architecture eliminates downloaded keys entirely: Workload Identity for GKE, the metadata server for Compute Engine, and impersonation for service-to-service calls.
The Reference Implementation: Kubernetes GKE
GKE is not managed Kubernetes. It is Kubernetes as Google runs it internally — built by the team that created the project, operated at a scale that no other managed Kubernetes platform matches, and integrated with GCP’s network, identity, and data platform in ways that EKS and AKS approximate but do not replicate.
The architectural difference between GKE and EKS is not primarily about features. It is about operational defaults and the assumptions baked into the platform.
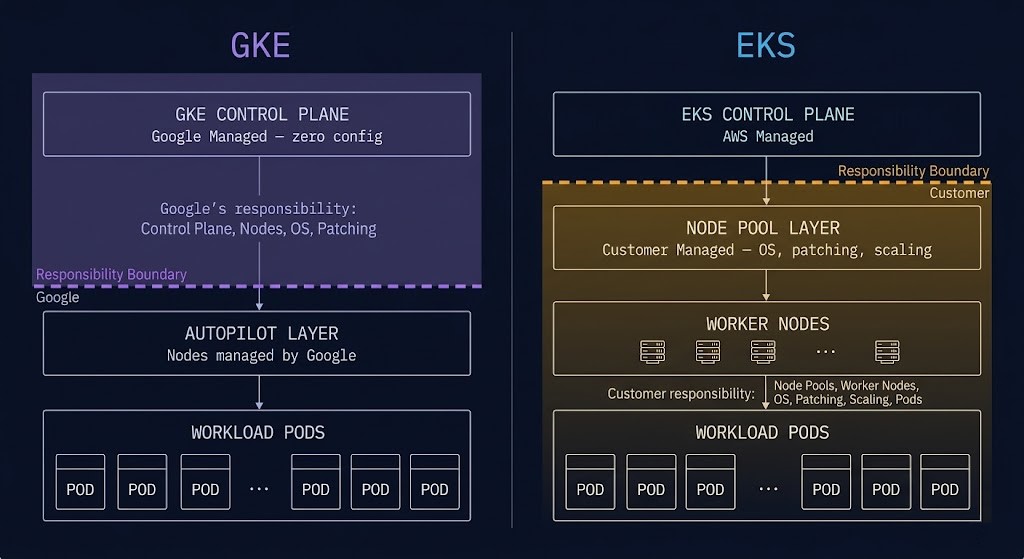
| Dimension | GKE | EKS |
|---|---|---|
| Control plane | Fully managed, zero configuration required | Managed control plane, worker nodes are customer responsibility |
| Networking | Dataplane V2 (Cilium-based) — eBPF networking native, integrated with VPC | CNI is customer choice — complexity and integration are customer responsibility |
| Node management | Autopilot — Google manages nodes, scaling, and bin-packing | Fargate approximation — less integrated, more configuration required |
| Version management | Release channels — Rapid / Regular / Stable — managed upgrade cadence | Manual version tracking and upgrade planning |
| Pod identity | Workload Identity — native IAM binding, no key files required | IRSA — works, but requires explicit configuration per service account |
| Opinionation | Opinionated — Google’s defaults reflect production-scale operational experience | Less opinionated — more flexibility, more customer-managed complexity |
GKE Autopilot — Node Management as a Solved Problem
GKE Autopilot removes node management from the operator’s responsibility entirely. You define workloads. Google manages the nodes that run them — provisioning, scaling, bin-packing, security patching, and node-level OS management. Autopilot billing is per-pod rather than per-node: you pay for the CPU, memory, and ephemeral storage your pods request, not for the underlying nodes those pods run on. For organizations where Kubernetes operational overhead is a constraint — teams that want to run containers without building a platform engineering function around node pool management — Autopilot is the correct default.
GKE Standard remains the right choice for workloads with specific node requirements: GPU nodes, custom machine types, specific OS configurations, or workloads that require direct node access for DaemonSets or system-level tooling. The decision between Autopilot and Standard is a workload classification exercise, not a preference.
Release Channels — Upgrade Management Without Maintenance Windows
GKE’s release channel model is one of its most underappreciated operational features. By enrolling a cluster in a release channel — Rapid, Regular, or Stable — you delegate Kubernetes version management to Google. Google handles control plane upgrades on the channel’s release cadence. Node auto-upgrade keeps worker nodes current with the control plane version. The operational consequence is that GKE clusters enrolled in release channels do not require manual upgrade planning, version compatibility research, or dedicated maintenance windows for Kubernetes version updates. Teams running EKS are managing Kubernetes version lifecycle manually — tracking end-of-support dates, planning upgrade sequences, coordinating maintenance windows. That overhead is a solved problem on GKE.
GKE Dataplane V2 — eBPF Networking Native
GKE Dataplane V2 uses an eBPF-based networking model derived from Cilium, enabling kernel-level packet processing, Layer 7 network policy enforcement, and deep observability without sidecar proxies. For platform teams evaluating service mesh architectures, GKE Dataplane V2 provides a significant portion of service mesh functionality — identity-based policy, traffic visibility, network telemetry — at the kernel layer rather than the application layer. The Service Mesh vs eBPF analysis covers the architectural tradeoffs between Cilium-based networking and traditional sidecar-based service meshes in detail — GKE Dataplane V2 is referenced specifically as GKE’s implementation of this model.
GKE Networking — IP Management at Scale
GKE networking on GCP’s global VPC introduces specific failure modes that differ from self-managed Kubernetes. IP exhaustion is among the most common — and most operationally disruptive — issues that GKE clusters encounter at scale. GKE allocates IP addresses from the VPC subnet for both nodes and pods. Pods use a secondary IP range allocated per node, and at high pod density or with aggressive cluster autoscaling, IP exhaustion in the pod CIDR or node subnet can silently prevent pod scheduling without an obvious error surface. The GKE Pod IP Exhaustion triage guide (Part 1) and fix guide (Part 2) document this failure mode in full — including the debate with Tim Hockin, one of the original Kubernetes creators, on the platform’s behavior. IP range planning is not a Day-2 concern for GKE. It is a Day-0 architecture decision.
For Day-2 GKE operations more broadly, the Rack2Cloud K8s Day-2 Method covers the four diagnostic loops — identity, compute, network, and storage — that surface the most common production failure patterns across GKE and self-managed clusters alike.
Zero Trust & Governance
GCP’s security model assumes no trusted network boundary. Identity and context define access — not network position, not IP address, not VPC membership. This is the BeyondCorp model that Google has operated internally for over a decade, and it is what GCP’s Zero Trust architecture is built on.
The contrast with AWS is architectural: AWS is IAM-first — the primary security control is permission policy attached to identities and resources. GCP is identity plus context plus perimeter fusion — access decisions combine who is requesting (identity), what they are requesting from (device posture, location, time), and what perimeter controls exist around the target resource (VPC Service Controls).
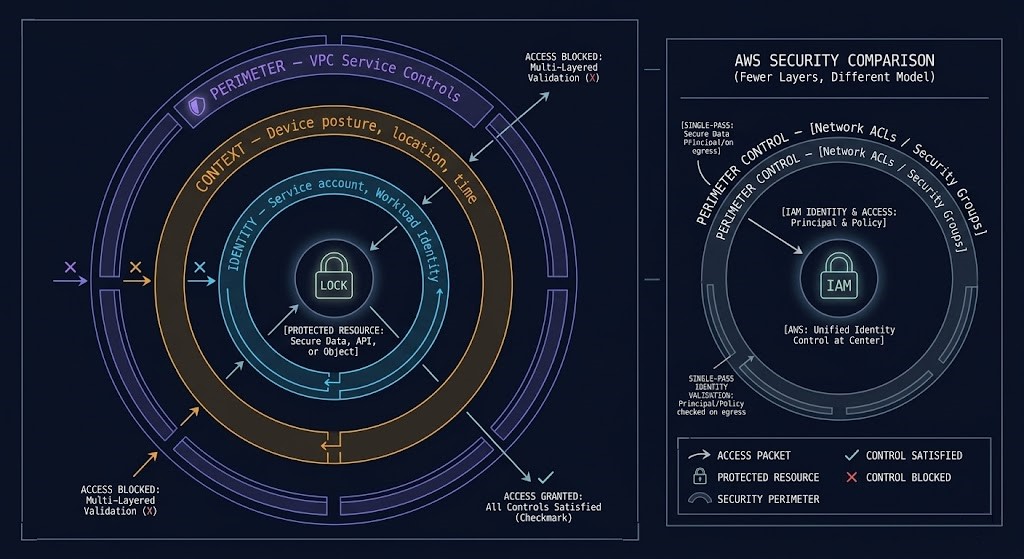
Organization Policies — Preventative Governance at Scale
Organization Policies define guardrails that apply across every project in the organization without per-project configuration. A policy that prevents VMs from having external IP addresses applies to every project in every folder under the organization. A policy that requires uniform bucket-level access on Cloud Storage applies everywhere. Unlike AWS SCPs which require explicit attachment to Organizational Units, GCP Organization Policies inherit down the resource hierarchy automatically from where they are set. For regulated environments where consistent policy enforcement across hundreds of projects is a compliance requirement, Organization Policies are not optional controls — they are the architecture.
VPC Service Controls — Data Exfiltration Perimeters
VPC Service Controls create security perimeters around GCP services — defining which identities and networks can access which services, and preventing data from being exfiltrated across perimeter boundaries. A VPC Service Control perimeter around BigQuery and Cloud Storage means that data in those services cannot be accessed from outside the perimeter, even by authenticated GCP identities that have the correct IAM permissions. The perimeter enforces an additional access constraint beyond IAM.
The distinction between VPC Service Controls and Private Service Connect is important and frequently confused. Private Service Connect is a connectivity mechanism — it allows private access to GCP services and third-party services without traversing the public internet. VPC Service Controls is a perimeter enforcement mechanism — it restricts what can be done with data in protected services regardless of how the connection was established. They are complementary controls, not alternatives. A complete data protection architecture for regulated workloads uses both: Private Service Connect for the connectivity path, VPC Service Controls for the data exfiltration perimeter.
Cloud Audit Logs — Immutable API Activity Record
Every API call in GCP — every resource creation, every IAM change, every data access event — is logged in Cloud Audit Logs. Admin Activity logs are always enabled and cannot be disabled. Data Access logs require explicit enablement but provide per-request visibility into who accessed which data, when, and from where. For incident response, compliance auditing, and forensic investigation, Cloud Audit Logs are the foundation. GCP environments without Data Access logs enabled on sensitive services are operating without the visibility required to detect or investigate data breaches.
Workload Identity Federation — Eliminating Static Credentials
Workload Identity Federation allows external identities — from AWS, Azure, on-premises systems, or CI/CD platforms — to impersonate GCP service accounts without requiring downloaded key files. An AWS Lambda function, a GitHub Actions workflow, or an on-premises Kubernetes pod can obtain short-lived GCP credentials by presenting a token from its native identity provider. The GCP IAM layer validates the token and issues temporary credentials scoped to the service account’s permissions. This eliminates the category of credential management problems that come with distributing static GCP service account keys to external systems.
Hybrid & Multi-Cloud Connectivity
| Model | Latency | Bandwidth | Use Case | Cost Model |
|---|---|---|---|---|
| HA VPN | Variable — public internet path | Up to 3 Gbps per tunnel pair | DR standby, low-volume hybrid, backup Interconnect path | Low — hourly + data transfer |
| Dedicated Interconnect | Deterministic — dedicated private fiber | 10 Gbps to 200 Gbps | Production hybrid, high-throughput data transfer, latency-sensitive workloads | High — port fee + data transfer |
| Partner Interconnect | Deterministic — via service provider | 50 Mbps to 50 Gbps | Dedicated Interconnect not available at colocation, lower bandwidth requirement | Medium — varies by provider |
| Cross-Cloud Interconnect | Deterministic — dedicated private link | 10 Gbps or 100 Gbps | Direct GCP-to-AWS or GCP-to-Azure private connectivity without public internet | High — dedicated circuit cost |
| Private Service Connect | Low — stays on Google backbone | VPC-native, no dedicated circuit | Private access to Google APIs and third-party services without public internet traversal | Low — endpoint + data transfer |
Private Service Connect deserves specific attention because it solves a problem that most hybrid connectivity guides focus on at the wrong layer. Cloud Interconnect and HA VPN address on-premises to GCP connectivity. Private Service Connect addresses service-to-service connectivity within GCP — allowing VMs, GKE pods, and other resources to access Google-managed services (Cloud Storage, BigQuery, Cloud SQL) and third-party services via private endpoints within the VPC, without traffic traversing the public internet. For regulated workloads where data must not leave the private network at any point, Private Service Connect is the mechanism that keeps GCP API traffic off the public internet. It is not a substitute for VPC Service Controls — PSC handles the connectivity path, VPC-SC handles the data perimeter. Both are required for a complete regulated workload architecture.
For GCP environments that extend to multiple clouds, the Crossplane portable control plane architecture provides the IaC model for managing GCP resources alongside AWS and Azure resources from a unified Kubernetes-native control plane — relevant for organizations adopting GCP as part of a deliberate multi-cloud strategy rather than an accumulated one.
Cost Physics
GCP cost is not a billing problem. It is an architecture problem — the same principle that applies to every cloud. But GCP has three cost mechanisms that differ from AWS in ways that change the design calculus.
Sustained Use Discounts — Automatic Optimization
GCP is the only major cloud where baseline compute cost optimization happens automatically. Sustained Use Discounts (SUDs) apply to Compute Engine VMs and GKE nodes that run for a significant portion of the billing month — no commitment required, no upfront payment, no reservation to manage. A VM that runs for more than 25% of the month begins receiving incremental discounts. A VM that runs continuously for the full month receives a discount of approximately 30% off the On-Demand price automatically. No action required.
This is architecturally significant because it removes the operational overhead of Reserved Instance management that AWS environments require. AWS teams maintain Reserved Instance portfolios, track expiration dates, evaluate Savings Plans coverage, and manage utilization targets. On GCP, steady-state workloads receive automatic cost reduction without a separate cost optimization practice. Committed Use Discounts (CUDs) provide deeper discounts — up to 57% for one-year commitments — for workloads with predictable, long-term resource requirements, and represent the GCP equivalent of AWS Reserved Instances for environments where predictability justifies the commitment.
Network Pricing Advantage
GCP’s global VPC eliminates many of the cross-zone and cross-region cost traps that compound in AWS architectures. Egress within a region between zones is cheaper than AWS inter-AZ transfer. Traffic between GCP services within the same region often carries no egress charge. For data platform architectures where Pub/Sub, Dataflow, BigQuery, and Vertex AI are exchanging data continuously, the absence of inter-service egress fees within a region changes the cost model significantly compared to the equivalent AWS assembly. The Physics of Data Egress analysis covers the specific egress economics across cloud providers — GCP’s near-zero intra-region and inter-service egress is called out directly as making it structurally superior for data gravity workloads.
BigQuery Pricing — Compute and Storage Separated
BigQuery’s separation of compute and storage costs is not just a pricing curiosity — it is an architectural pattern that changes how data retention decisions are made. In a provisioned data warehouse model (Redshift, Synapse), storage and compute are bundled: you pay for a cluster whether or not you’re running queries. In BigQuery, you pay for storage at rest and for the bytes each query scans. A petabyte dataset sitting unqueried costs storage fees only. The architectural consequence: data you would purge from a provisioned warehouse to avoid idle cluster costs can be retained in BigQuery because the retention cost is minimal and the query cost is incurred only when value is extracted. Historical analysis becomes economically viable at scales where provisioned systems price it out of reach.
Per-second billing on Compute Engine and GKE nodes eliminates the minimum hourly charge that makes short-lived workloads expensive on AWS. Batch jobs, CI/CD pipelines, and ephemeral environments that run for minutes rather than hours pay proportionally — the economics of short-lived compute work correctly on GCP without the architectural workarounds that AWS per-hour billing historically required.
Compute Decision Tree
| Workload Type | Right Abstraction | Why | Avoid |
|---|---|---|---|
| Legacy apps, full OS control | Compute Engine | Live migration handles host maintenance transparently; custom machine types eliminate overprovisioning | Standard machine types for workloads with precise CPU/memory requirements — use custom sizing |
| Microservices, containers | GKE (Autopilot for ops-light, Standard for platform teams) | Release channels, Workload Identity, Dataplane V2 — managed operational defaults reduce platform overhead | Self-managed Kubernetes on Compute Engine unless team has deep K8s operational capability |
| Event-driven, short execution | Cloud Functions / Cloud Run | Zero infrastructure management, scale to zero, per-invocation billing | Cloud Functions for long-running or stateful workloads — use Cloud Run for more complex containerized execution |
| Event-driven pipelines | Cloud Run + Pub/Sub | Native Pub/Sub trigger integration; stateless container execution with auto-scaling to zero between events | Polling-based architectures — Pub/Sub push eliminates the idle polling cost and latency |
| Data processing pipelines | Dataflow | Unified batch and streaming model; native BigQuery and Pub/Sub integration; no cluster management | Maintaining separate batch and streaming codebases — Dataflow’s Beam model unifies both |
| Analytics at scale | BigQuery | No cluster to provision; compute/storage separation; petabyte-scale query without infrastructure management | Provisioned data warehouse (Cloud SQL, AlloyDB) for analytics-primary workloads — BigQuery is the right tool |
| Fault-tolerant batch / HPC | GKE + Spot VMs | Spot VM discounts of 60–91% for preemptible workloads; GKE handles rescheduling on preemption | On-Demand VMs for stateless batch — the cost differential is too large to justify without hard statefulness requirements |
When GCP Is The Right Call
If Kubernetes is a strategic platform — not just a deployment target — GKE’s release channels, Autopilot, Workload Identity, and Dataplane V2 deliver a materially lower operational overhead than EKS or AKS. If your architecture starts with Kubernetes, GCP is often the simpler system.
Organizations where data analytics, real-time streaming, and ML are core business functions rather than bolt-on capabilities. The BigQuery + Pub/Sub + Dataflow + Vertex AI integration eliminates the stitching overhead that equivalent AWS architectures require.
Applications with global user bases where network latency is a product quality metric. GCP’s Premium Tier routing keeps traffic on Google’s backbone from source to destination — the same network that serves Google Search and YouTube at global scale.
Architectures built around event streams, real-time pipelines, and reactive services. Pub/Sub as a global event fabric, Cloud Run for stateless event processing, and Dataflow for stream analytics form an integrated event-driven platform with no equivalent assembly required.
When To Consider Alternatives
Organizations deeply invested in Microsoft Entra ID, Active Directory, and the Microsoft identity ecosystem. Azure’s native Entra integration removes the federation complexity that GCP requires when Microsoft identity is the organizational standard.
Workloads requiring the breadth of AWS’s 200+ service catalogue — niche managed services, specific compliance certifications only available on AWS, or ecosystems with deep AWS-specific tooling. GCP’s catalogue is deep where it focuses; it does not attempt to match AWS’s breadth.
Large portfolios of Windows Server, .NET, and SQL Server workloads. Azure’s licensing advantages and native Windows integration make it the more cost-effective and operationally simpler migration target for Microsoft-stack environments.
Workloads requiring jurisdictions where GCP’s Region footprint is thinner than AWS or Azure. For specific regulatory frameworks requiring in-country infrastructure in markets GCP has not yet fully built out, footprint geography constrains the choice regardless of platform preference.
Decision Framework
| Scenario | GCP Verdict | Why |
|---|---|---|
| Kubernetes-native platform, GKE as strategic runtime | Strong Fit | Reference implementation, release channels, Autopilot, Workload Identity — lowest operational overhead of any managed K8s |
| Real-time analytics + streaming + ML as core product | Strong Fit | BigQuery + Pub/Sub + Dataflow + Vertex AI as an integrated system — not an assembled stack |
| Global service, latency-sensitive, multi-region users | Strong Fit | Premium Tier keeps traffic on Google’s backbone globally — structural latency advantage over public internet routing |
| Event-driven architecture, Pub/Sub as platform backbone | Strong Fit | Global Pub/Sub, Cloud Run, and Dataflow form a native event-driven platform with consistent IAM and billing |
| Microsoft-first enterprise, Entra ID as identity standard | Evaluate Azure First | Native Entra integration removes federation complexity; GCP requires explicit SAML/OIDC configuration |
| Legacy app migration, AWS service dependency, broad catalogue requirement | Evaluate AWS First | AWS service depth and mature migration tooling are advantages for broad legacy portfolios without K8s or data platform focus |
| Multi-cloud IaC, portable control plane across providers | Strong Fit | GCP’s API-first model and Kubernetes-native tooling (Crossplane, Config Connector) support portable multi-cloud IaC patterns |
| Regulated workload, no public internet, strict perimeter | Strong Fit | VPC Service Controls + Private Service Connect + Organization Policies form a complete regulated architecture — BeyondCorp model is mature |
You’ve seen how GCP is architected. The pages below cover what sits beside it — competing platforms, hybrid connectivity, cost governance, and the infrastructure disciplines that determine where GCP belongs in your environment.
Architect’s Verdict
GCP is not trying to be everything. It is trying to be the best platform for distributed systems and data-native architectures — and for those workload classes, it succeeds in ways that other clouds do not replicate.
The global network is not a marketing claim. The Andromeda SDN and Jupiter switching fabric underpin a genuinely different network architecture — one where the VPC is global by design, routing is Google-managed, and Premium Tier traffic stays on Google’s backbone from source to destination. For latency-sensitive, globally distributed services, that is a structural advantage that AWS’s regional VPC model cannot match without significant additional configuration complexity.
The data platform integration is real. BigQuery, Pub/Sub, Dataflow, and Vertex AI form a coherent system — not an assembled stack. Organizations building data products where analytics, streaming, and ML are core functions will find GCP’s data platform reduces operational overhead in ways that become more pronounced as the platform scales.
GKE is genuinely different from other managed Kubernetes offerings. Release channels solve a real operational problem. Autopilot changes the economics of container orchestration for teams that don’t need to manage nodes. Workload Identity eliminates a category of credential management risk that EKS and AKS require explicit effort to address.
What GCP is not: a general-purpose enterprise cloud with the service depth of AWS or the Microsoft ecosystem integration of Azure. Organizations that need either of those things should evaluate those platforms first. GCP earns the architecture decision when Kubernetes is strategic, when data is the product, and when the network is a design constraint rather than a configuration problem.
Engage with it on its own terms. The architects who do consistently get more out of it than they expected.
You Understand the Platform.
Now Validate Your Implementation.
GCP’s resource hierarchy, global VPC model, and data platform integration reward architects who engage with it correctly — and punish those who don’t. The triage session validates whether your specific GCP architecture is extracting the platform’s structural advantages or leaving them on the table.
GCP Architecture Audit
Vendor-agnostic review of your GCP environment — resource hierarchy design, IAM and service account governance, VPC topology, GKE configuration, and data platform integration. Whether you’re early in adoption or operating at scale, the audit surfaces where the architecture is correct and where it isn’t.
- > Resource hierarchy and Organization Policy review
- > IAM and service account key sprawl audit
- > GKE configuration and Workload Identity validation
- > BigQuery cost model and data platform architecture
Architecture Playbooks. Every Week.
Field-tested blueprints from real GCP environments — GKE IP exhaustion failures, service account key sprawl incidents, BigQuery cost model traps, and the data platform patterns that separate GCP’s structural advantages from its operational pitfalls.
- > GKE Architecture & Day-2 Operations
- > GCP IAM & Resource Hierarchy Patterns
- > BigQuery & Data Platform Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What makes GCP cloud architecture different from AWS for enterprise workloads?
A: GCP’s differentiators are architectural, not feature-level. The global VPC eliminates the regional networking complexity that AWS requires for multi-region architectures. Sustained Use Discounts apply automatically without the reservation management overhead of AWS Reserved Instances. GKE is Kubernetes as Google runs it internally — release channels, Autopilot, and Workload Identity deliver operational defaults that EKS requires manual configuration to approximate. And the data platform integration — BigQuery, Pub/Sub, Dataflow, Vertex AI — forms a native system rather than an assembled stack. For organizations where Kubernetes is strategic or data is the product, these differences compound significantly at scale.
Q: How does GCP’s global VPC actually differ from AWS VPCs?
A: An AWS VPC is a regional construct — it exists in a single region, and cross-region communication requires explicit peering, Transit Gateway, or public internet routing. A GCP VPC is global — a single VPC spans all regions, and subnets in different regions share the same routing table. A VM in us-central1 and a VM in europe-west1 communicate within the same VPC without any additional configuration. This eliminates an entire category of networking complexity — the multi-region VPC mesh that AWS architects build and operate is not required in GCP.
Q: Is GKE Autopilot suitable for production workloads?
A: Yes, for the majority of containerized production workloads. Autopilot is Google’s recommended GKE mode for teams that want to run containers without managing node pools, OS patching, or bin-packing. Google manages the nodes — you manage the workloads. Autopilot enforces certain pod security standards and does not support DaemonSets or privileged containers, which excludes specific use cases. GKE Standard remains the right choice for workloads requiring node-level customization, GPU configurations, or specific DaemonSet requirements. For everything else — microservices, APIs, stateless applications, and most stateful workloads — Autopilot is production-ready and operationally simpler than Standard.
Q: What is the GCP equivalent of AWS Reserved Instances?
A: Committed Use Discounts (CUDs) — but with an important difference. AWS requires active management of Reserved Instance portfolios: purchasing, tracking utilization, evaluating Savings Plans coverage, and managing expiration. GCP Sustained Use Discounts apply automatically to VMs that run for more than 25% of the billing month, providing approximately 30% discount with no commitment required. CUDs provide deeper discounts — up to 57% — for one-year commitments on specific resource types. The operational difference is significant: GCP’s automatic baseline optimization removes the cost management overhead that AWS Reserved Instance management requires.
Q: How should GCP service account security be managed at scale?
A: The core principle is eliminating downloaded service account keys entirely. Downloaded JSON keys are long-lived credentials that do not expire by default, do not appear in audit logs unless used, and can be distributed without platform visibility. The correct architecture for GKE workloads is Workload Identity — binding Kubernetes service accounts to GCP service accounts through IAM, so pods obtain short-lived credentials from the metadata server rather than from a key file. For Compute Engine workloads, the metadata server provides credentials automatically for the attached service account. For external systems accessing GCP APIs, Workload Identity Federation allows external identities to impersonate service accounts without key distribution. Organization Policies can enforce constraints that prevent service account key creation entirely in projects that have adopted these patterns.
Q: When does GCP’s data platform justify choosing GCP over AWS for a net-new architecture?
A: When analytics, streaming, and ML are core functions rather than supporting capabilities. The BigQuery + Pub/Sub + Dataflow + Vertex AI integration eliminates the data movement, operational overhead, and billing complexity that the equivalent AWS assembly requires. If a net-new architecture needs to ingest real-time events, process them at scale, store results for analytics, and feed an ML model — and those requirements are central rather than peripheral — GCP’s data platform is architecturally simpler than assembling and operating the equivalent from S3, Kinesis, Glue, EMR, and SageMaker. The simplicity advantage is most pronounced at scale and compresses as data platform requirements become simpler or more peripheral to the product.
Q: How does GCP handle multi-cloud governance for organizations running GCP alongside AWS or Azure?
A: GCP’s resource hierarchy — Organization → Folder → Project — provides centralized governance that applies automatically across all resources. Organization Policies set at the org level propagate to every project without per-project configuration. For multi-cloud governance that spans GCP and other providers, Crossplane’s GCP provider enables Kubernetes-native management of GCP resources through the same control plane managing AWS and Azure resources — treating cloud infrastructure as Kubernetes custom resources with a consistent GitOps operational model. The Cloud Strategy Hub covers the multi-cloud architecture decision framework in full.