CONTAINER SECURITY ARCHITECTURE
IDENTITY IS THE PERIMETER. ENFORCEMENT IS THE ARCHITECTURE.
Container security is not image scanning. That is the most common and most dangerous misunderstanding in production container environments today.
Scanning detects known vulnerabilities at a point in time. It tells you what was in the image when you built it. It says nothing about what runs in production three weeks later after a base image drift, a misconfigured admission controller, or a ServiceAccount that was granted cluster-admin because nobody read the Helm chart defaults. The organizations that get compromised are not the ones who skipped scanning. They are the ones who scanned, felt secure, and stopped there.
Container security is a trust enforcement problem. It spans four distinct environments — the build pipeline, the container registry, the runtime, and the control plane — and it fails whenever any one of those environments is treated as someone else’s responsibility. The kernel is shared. The network is flat by default. Lateral movement from a compromised container to a compromised node to a compromised cluster is not a theoretical attack path. It is the documented reality of every major container security incident in the last three years.
The architecture that actually works does not start with tools. It starts with a mental model: identity is the real perimeter, not the container boundary. Containers share a kernel. NetworkPolicies are opt-in. RBAC is configured, not enforced by default. Every assumption of isolation that teams bring from the VM world needs to be re-examined from first principles. This page covers the five-layer security stack, where the architecture actually fails in production, the cost of getting it wrong, and the decision framework that determines how deep the controls need to go for your specific environment. This guide sits within the Cloud Native Architecture pillar under the broader Cloud Architecture Strategy hub — the framework that governs where container environments belong in your overall platform architecture.
What Container Security Actually Is
Most container security guides are organized around tools. This one is organized around control planes — because the tool you choose matters far less than understanding which control plane you are operating in and what it is actually responsible for.
Container security operates across three distinct control planes. Each one has a different threat surface, different failure modes, and different ownership boundaries. Treating them as a single problem is why most container security programs have gaps they cannot see.
Supply chain integrity. Image provenance. Vulnerability scanning before the image ever reaches a registry. This control plane is the cheapest place to stop a compromise — and the most commonly treated as a checkbox rather than an architecture.
Policy and admission control. The gate between what teams want to deploy and what the cluster will accept. Admission webhooks, OPA/Gatekeeper, Pod Security Standards — this is where policy is enforced, not where it is defined.
Behavior and containment. What the container actually does once it is running. Syscall filtering, network policy enforcement, behavioral anomaly detection. This is the hardest control plane to operate and the one most teams invest in last.
The Container Security Stack
Container security is not a single control. It is a layered architecture where each layer has distinct threat models, distinct tooling, and distinct failure modes. The five-layer model below is the organizing framework for everything that follows on this page.
Understanding which layer a control belongs to — and which failure modes that layer is responsible for preventing — is the prerequisite for building a security architecture that doesn’t have invisible gaps.
Who built the image, what is in it, and can the cluster verify it hasn’t been tampered with? Cosign/Sigstore for signing, SBOM generation for dependency visibility, distroless base images to minimize attack surface.
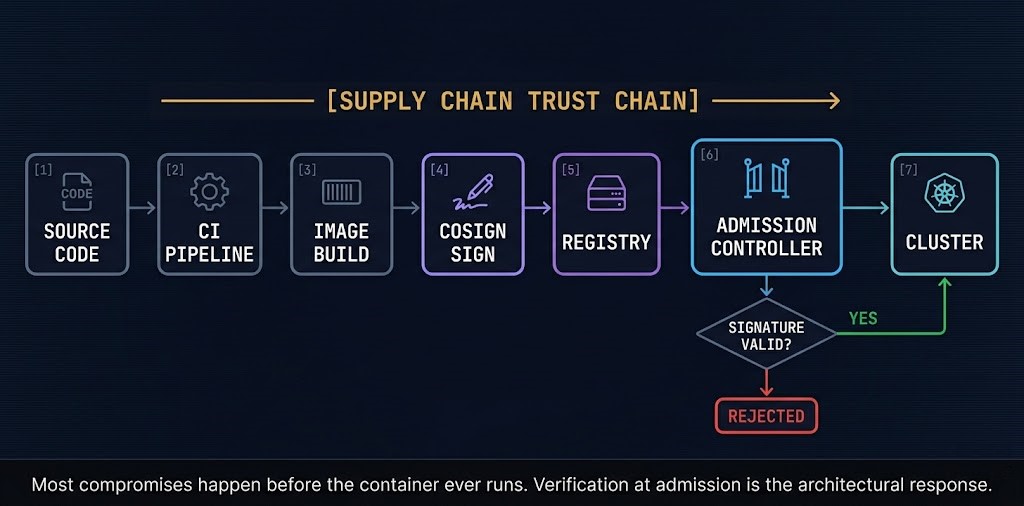
What can enter the registry, and what will the cluster accept at deploy time? Admission webhooks verify signatures and enforce policy before any workload reaches a node. OPA/Gatekeeper extends this with custom organizational policy. An image that passes the registry gate but fails admission never runs.
How isolated is the container from the host kernel and neighboring workloads? seccomp profiles restrict allowed syscalls. AppArmor/SELinux constrain file and network access. Sandbox runtimes (gVisor, Kata Containers) add a second kernel boundary for high-risk workloads. Rootless containers reduce the blast radius of a container escape.
Who can talk to what, and who can do what in the cluster? NetworkPolicy enforces east-west segmentation. RBAC defines what ServiceAccounts and users can interact with via the Kubernetes API. Workload identity (OIDC federation) binds pod identity to cloud IAM. mTLS at the service mesh layer provides identity-based communication policy beyond IP-based NetworkPolicy.
Where do credentials live and how do they reach workloads? Environment variables and ConfigMaps are not secrets management — they are secret exposure. External Secrets Operator, Vault Agent, and cloud-native KMS integrations inject short-lived credentials at runtime without storing them in etcd. Rotation policies ensure compromised credentials have a bounded validity window.

Supply Chain Security
Most compromises happen before the container ever runs. This is the core insight that separates a mature supply chain security posture from a scanning checkbox — and it changes everything about where you invest first.
A container image is not just your application code. It is your application code plus every dependency it was compiled with, plus the base image layers it was built on, plus the system libraries those layers include. When any one of those components has a known vulnerability, your image inherits it. When any one of those components is controlled by an attacker — a compromised package registry, a typosquatted dependency, a backdoored base image — your workload is compromised before it ever touches your cluster.
Image provenance answers the question build-time scanning cannot: who built this image, and can you verify it? Cosign (part of the Sigstore project) allows images to be cryptographically signed at build time and verified at admission time. An admission controller that rejects unsigned images means an attacker who injects a malicious image into your registry cannot get it to run — because it lacks a valid signature from your CI pipeline. This is not a theoretical control. It is one of the most effective supply chain protections available and one of the least deployed in production environments.
Software Bill of Materials (SBOM) generation gives you continuous visibility into what is in each image. An SBOM is a machine-readable inventory of every package, library, and dependency in an image at a specific build. When a new CVE is published, an SBOM-backed system can immediately identify which running workloads are affected — without re-scanning every image. Without SBOMs, vulnerability management is reactive and blind to the full exposure surface.
The CI/CD pipeline is an attack surface, not a trusted boundary. A compromised build environment, a malicious dependency injection, or a tampered base image produces a signed artifact that passes every downstream check. Supply chain security is not about trusting the pipeline — it is about verifying the output regardless of where it came from.
Provenance tracking, hermetic builds, and admission-time signature verification are the architectural response — not faster scanning cycles.
Base image hardening reduces the supply chain attack surface before any application code is added. Distroless images contain only the application runtime and its direct dependencies — no shell, no package manager, no utilities that an attacker could use for post-compromise lateral movement. An attacker who achieves code execution in a distroless container has no bash, no curl, no apt — the standard toolkit for container escape and lateral movement is simply absent. For production workloads where the attack surface of the running container matters, distroless is not a best practice suggestion. It is an architectural default.
Runtime Security and Isolation
Runtime is where every security assumption made at build time and deploy time gets tested against real-world execution. It is also the layer most teams invest in last — because it is the most operationally complex to configure correctly and the easiest to believe is someone else’s responsibility.
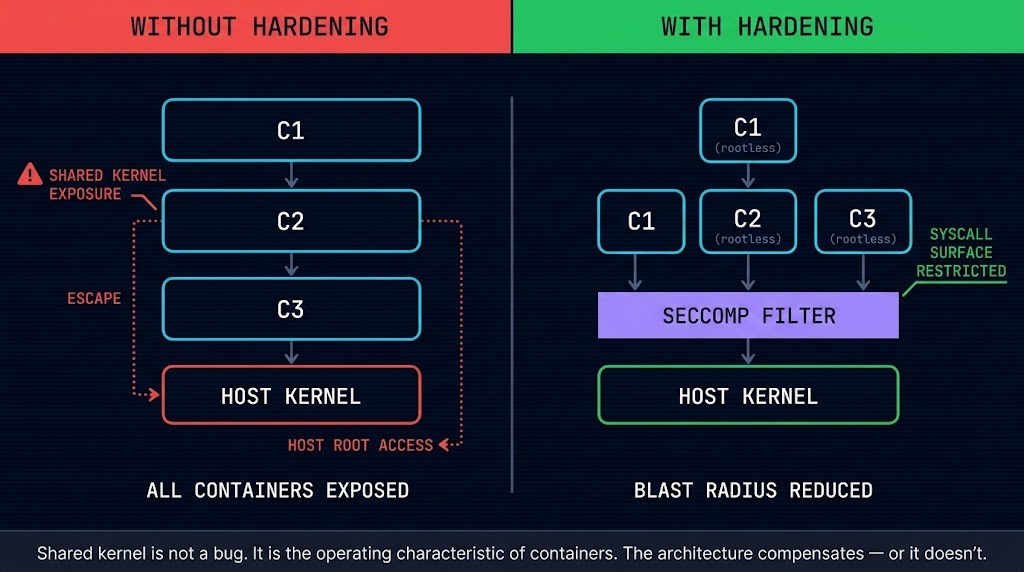
The foundational misunderstanding about container isolation is that containers are isolated by default. They are not. Containers share the host kernel. Two containers on the same node — different namespaces, different teams, different workloads — make syscalls to the same kernel. A vulnerability in the kernel is a vulnerability in every container on that node. A container escape that breaks out of the namespace boundary reaches the host. These are not edge cases. They are the operating characteristics of the container model, and the security architecture must be designed around them.
seccomp profiles define the set of syscalls a container is permitted to make to the host kernel. A container that does not need to open raw sockets, mount filesystems, or modify kernel parameters should not be allowed to attempt those operations. The default seccomp profile in Kubernetes provides a basic filter; a workload-specific profile reduces the permitted syscall surface to only what the application actually requires. The gap between “default profile” and “workload-specific profile” is the gap an attacker exploits to move from container to host.
AppArmor and SELinux extend mandatory access control to file system paths, network access, and process capabilities. Where seccomp restricts what syscalls can be made, AppArmor and SELinux restrict what those syscalls can act on. A container that can only write to its own directory, cannot bind to privileged ports, and cannot access host device files has a dramatically smaller blast radius if compromised.
Sandbox runtimes — gVisor and Kata Containers — address the fundamental shared-kernel problem by adding a second isolation boundary. gVisor runs a user-space kernel that intercepts syscalls before they reach the host kernel. Kata Containers runs each container in a lightweight VM with its own kernel. Both approaches impose a performance overhead that rules them out as universal defaults. For workloads processing untrusted input, running third-party code, or operating in regulated environments where kernel-level isolation is a compliance requirement, the overhead is justified by the isolation guarantee.
Runtime security tools often detect too late. Falco, Sysdig, and behavioral monitoring platforms observe syscall patterns and flag anomalies after they occur. Detection tells you a container escape attempt happened. Prevention stops it before the syscall completes.
seccomp profiles and AppArmor policies are prevention controls — they block the syscall. Runtime detection tools are response controls — they alert after the fact. A mature runtime security posture requires both: prevention to block, detection to catch what prevention misses.
Rootless containers run the container runtime and all container processes as a non-root user on the host. A container running as root inside the container namespace maps to root on the host if the container escape succeeds — giving the attacker full host privileges immediately. A rootless container maps to an unprivileged user on the host, significantly reducing the blast radius of a successful escape. For containerd-based runtimes in production, rootless mode is a supported configuration that eliminates the privilege escalation path that root-in-container represents. The operational tradeoff is real — some workloads require root capabilities that rootless mode cannot provide — but the default should be rootless unless the workload explicitly requires otherwise.
Identity, RBAC, and Workload Trust
Identity is the real perimeter in a Kubernetes environment. Not the container boundary. Not the namespace. Not the network segment. The question that determines the blast radius of any compromise is always the same: what is this workload’s identity, and what can that identity do?
A compromised container with a default ServiceAccount that has no cluster permissions is a dead end for an attacker. A compromised container with a ServiceAccount that has list/get/watch on all secrets, or create permissions on deployments, or cluster-admin rights granted by a Helm chart with overly broad RBAC defaults — that is a cluster-level incident waiting for a trigger.
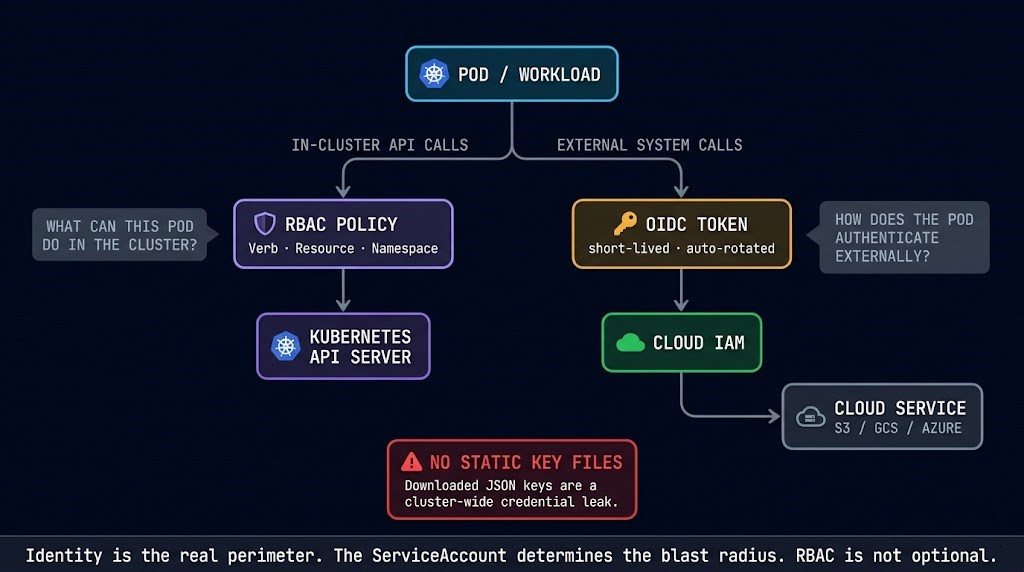
Kubernetes RBAC is the access control model for the Kubernetes API. Roles define a set of permissions on specific resources and verbs. RoleBindings attach Roles to ServiceAccounts, users, or groups within a namespace. ClusterRoles and ClusterRoleBindings extend this to cluster-wide resources. The critical architectural principle is least privilege: every ServiceAccount should have exactly the permissions it needs to function, scoped to exactly the namespace it operates in. Cluster-scoped permissions require explicit justification. The cluster-admin ClusterRole should never be bound to a workload ServiceAccount. The Kubernetes Cluster Orchestration guide covers the full RBAC model and the failure modes of misconfigured policy in production.
Identity is the real perimeter — not the container boundary.
A container can escape its namespace and still be blocked by RBAC. A container inside its namespace with a misconfigured ServiceAccount can compromise the entire cluster without breaking any isolation boundary. The perimeter is the identity, and the identity is defined by RBAC.
ServiceAccounts are the workload identity mechanism within the cluster. But workloads increasingly need to authenticate to systems outside the cluster — cloud storage buckets, secret management systems, databases, external APIs. The traditional answer was to mount credentials as environment variables or Kubernetes Secrets. The correct answer is workload identity federation.
Workload identity federation uses OIDC tokens issued by the Kubernetes API server to allow pods to authenticate directly to cloud IAM systems. A pod running in GKE can obtain a short-lived GCP service account token from the metadata server without any key file. A pod running in EKS can assume an AWS IAM role via IRSA (IAM Roles for Service Accounts). A pod in AKS can use Azure Workload Identity. In each case, the pod’s Kubernetes ServiceAccount is bound to a cloud IAM identity through a trust relationship — and credentials are short-lived, automatically rotated, and never stored in etcd or mounted as static secrets.
This eliminates one of the most persistent credential management failure modes in Kubernetes environments: the long-lived cloud credential stored as a Kubernetes Secret, accessible to any pod in the same namespace that can read secrets, with no expiry and no rotation. The Kubernetes Day-2 failure patterns that trace back to credential mismanagement consistently originate in this exact pattern.
Network Security
The Kubernetes network model has a default that most teams do not realize until after their first security audit: every pod can reach every other pod in the cluster. No firewall. No segmentation. No access control. A pod running a public-facing web application and a pod running an internal database are on the same flat network by default. An attacker who compromises the web application pod has direct network access to the database pod — no lateral movement required, because lateral movement is the default state.
NetworkPolicy is the Kubernetes primitive that closes this gap. A NetworkPolicy is a namespaced resource that defines ingress and egress rules for pods matching a label selector. Pods not covered by any NetworkPolicy receive all traffic. Pods covered by a NetworkPolicy receive only the traffic that policy explicitly permits. The default-deny pattern — a NetworkPolicy that denies all ingress and egress for all pods in a namespace, with additional policies that selectively allow required communication paths — is the correct baseline for production namespaces. It requires mapping every legitimate communication path in the cluster and encoding it as policy, which is operationally significant work. It is the only way to limit the blast radius of a compromised workload. See how flat network architectures amplify cascading failure risk across multi-cloud environments — the same principle applies inside a cluster.
A default Kubernetes cluster has 100% pod-to-pod lateral reach. Every pod can reach every other pod on every port. NetworkPolicy is opt-in, not opt-out. The burden of segmentation is entirely on the architect — the platform does not enforce it.
Default-deny NetworkPolicy per namespace, combined with explicit allow rules for required communication paths, is the only architectural response. Label-based selectors make policy portable across scaling events.
NetworkPolicy has real limitations that architects need to account for. It operates at Layer 3 and Layer 4 — IP addresses and ports. It cannot enforce policy based on HTTP methods, request paths, or service identity beyond IP. It cannot provide mutual authentication between services. It does not encrypt traffic in transit. For environments where east-west security requirements go beyond port-level segmentation — where the architecture requires cryptographic service identity, encrypted inter-service communication, or policy enforcement at Layer 7 — these are the problems a service mesh solves.
A service mesh adds a sidecar proxy to each pod that handles all inbound and outbound traffic. mTLS between sidecars provides cryptographic service identity and encrypted transit without application code changes. Traffic policy at Layer 7 allows fine-grained access control based on HTTP methods, headers, and service identity rather than just IP and port. The service mesh is the architectural evolution of NetworkPolicy for environments with mature security requirements — not a replacement, but an extension that operates at a different layer.
NetworkPolicy and service mesh are complementary controls, not alternatives. NetworkPolicy provides coarse-grained pod-to-pod segmentation at the network layer. Service mesh provides fine-grained identity-based policy at the application layer. Both belong in a production-grade container security architecture for regulated or high-security environments.
Secrets Management
The most common secrets management mistake in Kubernetes environments is not using Kubernetes Secrets incorrectly. It is believing that Kubernetes Secrets are secrets management.
Kubernetes Secrets are base64-encoded values stored in etcd. Base64 is not encryption — it is encoding. A Kubernetes Secret is accessible to any pod in the same namespace that has get or list permission on the Secrets resource. It is accessible to anyone with etcd access. It appears in plaintext in kubectl describe output unless explicitly filtered. The name “Secret” describes the intended use, not the security properties of the storage mechanism.
Environment variables are worse. A secret injected as an environment variable is visible in process listings, accessible via /proc/PID/environ on the host, logged by applications that dump their environment on startup, and preserved in container image layers if set during a build step. The pattern of storing database passwords, API keys, and cloud credentials as environment variables or in ConfigMaps is not a security practice. It is secret sprawl with an architectural veneer.
| Method | Encrypted at Rest | Rotation Support | Access Scope | Risk Level |
|---|---|---|---|---|
| Environment Variables | No | No | Process listing, /proc, logs | Critical |
| Kubernetes Secrets (default) | base64 only | Manual | All pods with RBAC read in namespace | High |
| Kubernetes Secrets + etcd encryption | Yes (at rest) | Manual | All pods with RBAC read in namespace | Medium |
| External Secrets Operator + KMS | Yes | Automated | Per-workload, policy-governed | Low |
| Vault Agent Injector | Yes | Automated | Dynamic, short-lived, per-pod | Low |
| Workload Identity + Cloud KMS | Yes | Automatic | Pod identity-bound, no etcd storage | Low |
The architectural principle for secrets management in container environments is elimination over mitigation: the goal is not to store secrets more securely in etcd, it is to eliminate static long-lived secrets from the system entirely.
External Secrets Operator synchronizes secrets from external secret stores — AWS Secrets Manager, GCP Secret Manager, Azure Key Vault, HashiCorp Vault — into Kubernetes Secrets at runtime. The secret value never lives in version control, never gets baked into an image, and is managed centrally with audit logging, rotation policies, and access governance. Vault Agent Injector goes further — injecting secrets directly into pod filesystems as short-lived, dynamically generated credentials that expire after a configured TTL. A database password that expires in 15 minutes and is regenerated on the next request is not a useful credential for an attacker who exfiltrated it. Short-lived credentials are architecturally superior to rotation schedules because they make the stolen credential problem self-resolving. Tie secrets management back to workload identity: secrets should not be accessible to all pods in a namespace. They should be accessible to the specific workload identity that needs them, governed by the same RBAC and IAM model that governs every other access decision in the architecture.
Zero Trust in Container Environments
Zero trust is not a product. It is an architectural philosophy with a single core principle: never trust, always verify. In a container environment, this translates to a specific set of architectural decisions that, taken together, eliminate the implicit trust that traditional perimeter-based security relies on.
Traditional security assumes the network perimeter is the trust boundary. Inside the perimeter, traffic is trusted. Container environments have no meaningful perimeter. Pods are ephemeral. IP addresses change. Workloads scale horizontally. Services communicate across namespaces, across clusters, and across clouds. A security model that relies on “inside the cluster = trusted” is broken by design.
Every access decision is based on verified identity — workload identity, user identity, ServiceAccount — not network position or IP address. A pod inside the cluster is not trusted because it is inside the cluster.
Mutual TLS between all services provides cryptographic proof of identity on both sides of every connection. Unencrypted east-west traffic is indistinguishable from attacker traffic on a compromised node.
RBAC, NetworkPolicy, seccomp profiles, and IAM permissions all follow the same principle: grant only what is required for the specific function, scoped to the specific resource, for the specific time it is needed.
Trust is not established once at deployment. It is continuously re-verified. Admission controllers re-evaluate policy on every pod creation. Short-lived credentials expire and are re-issued. Runtime monitors verify behavior matches the declared profile.
No single control is sufficient. Supply chain policy, admission policy, runtime policy, network policy, and identity policy operate independently and in depth. A failure at one layer does not mean an unrestricted path through the system.
Shared Responsibility Model
Kubernetes provides primitives, not security. This distinction is the source of more container security incidents than any specific vulnerability — organizations deploy Kubernetes believing the platform handles security, discover it handles security surfaces, and spend the next year retrofitting controls onto a production environment that was never hardened.
The shared responsibility model in container environments is not a binary platform-versus-customer split. It is a three-way division between the cloud provider, the Kubernetes platform, and the architecture team. Cloud providers secure the physical infrastructure and the managed control plane. Kubernetes provides the security API surface — RBAC, NetworkPolicy, Pod Security Standards, admission webhooks. The architecture team is responsible for configuring and enforcing all of it correctly.
The pattern across container security incidents is consistent: the cloud provider did not fail. The Kubernetes platform did not fail. The architecture team did not configure the controls the platform made available. Most container breaches are not zero-day exploits against hardened systems — they are known attack patterns succeeding against systems where the primitives existed but the policy was never written. Kubernetes gives you the tools. Security requires using them. How those tools fit into the broader platform governance model — across AWS, GCP, Azure, and hybrid environments — is covered in the Cloud Architecture Strategy hub. If you’re building toward a structured progression through cloud and container architecture, the Cloud Architecture Learning Path maps the sequence. For teams building the internal platform layer that container security policy runs on, the Platform Engineering Architecture pillar covers how security enforcement integrates into the golden path and developer platform governance model.
The Operational Reality
Container security programs fail in production for reasons that have nothing to do with the controls themselves. The tooling works. The policy definitions are correct. The security architecture is sound on paper. And yet the posture degrades, the alerts multiply, and teams end up less confident in their security posture after six months of investment than they were before they started.
This is the operational reality of container security at scale, and it deserves more honest treatment than most architecture guides provide.
Policy drift is the first operational failure mode. A security policy that is enforced today will drift from reality within weeks in a production environment. New workloads get deployed with permissive defaults because the team is moving fast and nobody updated the OPA policy. A Helm chart installs with cluster-admin ServiceAccount permissions because nobody audited the RBAC defaults before running helm install. A new namespace gets created without the default-deny NetworkPolicy because it was provisioned manually rather than through the IaC pipeline that included the policy. Drift is not negligence — it is the default behavior of any system where policy and deployment are not coupled. The architectural response is policy-as-code, enforced through admission controllers that make non-compliant deployment impossible rather than monitored after the fact. See how drift compounds silently in autonomous systems — the same pattern applies to security policy in production container environments.
Alert fatigue is the second operational failure mode. A production Kubernetes cluster running Falco or a similar runtime detection tool will generate hundreds of alerts per day at default sensitivity. Security teams that cannot distinguish signal from noise stop treating alerts as signal. The fix is alert triage, not alert volume — tuning detection rules to the specific workload behavior of each environment so that alerts represent genuine anomalies rather than expected operational patterns. This requires knowing what normal looks like for each workload, which requires baseline profiling before alert thresholds are set.
The false sense of security from scanners is the third and most dangerous operational failure mode. A green scan result creates the impression that the workload is secure. It means the workload had no known vulnerabilities at the time of the scan. It says nothing about runtime behavior, RBAC configuration, network policy, secrets handling, or any of the other dimensions that actually determine security posture. Teams that invest heavily in scanning and lightly in the other four layers consistently have lower actual security posture than teams that invest proportionally across all five.
Complexity explosion is the fourth. Every security control adds operational surface area. seccomp profiles need to be maintained and updated when application behavior changes. Vault leases need to be monitored and renewed. OPA policies need to be tested before deployment. NetworkPolicies need to be audited when service communication patterns change. The total operational cost of a complete container security posture is significant, and it compounds with cluster scale. The architecture must account for this cost upfront — not discover it after the controls are deployed and the maintenance burden materializes.
Cost Physics of Security
Container security has a cost physics that most architecture reviews ignore until the bill arrives. The controls are not free, and the costs are not only financial.
Runtime tool overhead is the most visible cost. Falco and comparable runtime security tools instrument the kernel to observe syscall patterns. The observability comes with CPU and memory overhead that is measurable in production — typically 3–8% CPU overhead per node depending on workload density and event volume. At cluster scale, this is a real infrastructure cost that should be budgeted as a security line item, not discovered as unexplained node utilization.
Service mesh latency cost is the most architecturally impactful. Adding a sidecar proxy to every pod introduces additional network hops for every inter-service call. Envoy-based sidecars (Istio, Linkerd) add latency in the range of 1–5ms per hop under normal conditions. For latency-sensitive microservice architectures with deep call chains, this compounds across hops. The P99 latency impact can be significant. The architectural decision to adopt a service mesh must account for this cost explicitly — the security value of mTLS and identity-based routing needs to be weighed against the latency budget available for inter-service communication.
Observability explosion is the cost most teams discover too late. A fully instrumented container security posture — runtime detection, audit logging, network flow logging, admission audit logs — generates log volume that can exceed the application logs by an order of magnitude. The storage and processing cost of security observability at production scale is substantial. Log retention policies, tiered storage, and sampling strategies for high-volume security telemetry need to be designed into the observability architecture before deployment, not added reactively when the logging bill arrives.
Engineering cost is the largest cost and the hardest to budget. Writing workload-specific seccomp profiles requires application behavior profiling. Building OPA policies requires rego expertise. Designing NetworkPolicy for a complex microservice mesh requires complete service communication mapping. Maintaining all of it requires ongoing investment as the system evolves. The engineering cost of container security done properly is not a one-time project. It is a continuous platform capability that requires dedicated resourcing. Teams that treat it as a project consistently find themselves rebuilding it six months later when the system has evolved past what the initial implementation covered.

Where Container Security Breaks Down
These are not theoretical failure modes. They are the documented patterns behind the majority of container security incidents in production environments. Each one shares the same characteristic: the architecture had the capability to prevent it, and the control was either not deployed or not enforced.
Images are scanned at build time and deployed days or weeks later. Base images are updated. Dependencies are patched. The image running in production has a different vulnerability profile than the image that passed the scan. Without continuous re-scanning of running workloads and automatic remediation pipelines, the scan result is a historical record, not a current security state.
The default container runs as root. The default Kubernetes pod has no seccomp profile applied. A root container with unrestricted syscall access on a shared kernel is a container escape waiting for a trigger — a kernel vulnerability, a misconfigured capability, an application-level code execution flaw. Rootless containers + restrictive seccomp profiles + no privileged containers in Pod Security Standards closes this gap. The K8s Day-2 failure analysis documents specific privilege escalation patterns from production incidents.
A compromised pod in a cluster without NetworkPolicy has unrestricted access to every other pod, every service endpoint, and the Kubernetes API server. Lateral movement from a compromised frontend to a production database requires no exploitation — only a TCP connection. Default-deny NetworkPolicy per namespace is the minimum viable network segmentation. The cascading failure risk from flat network architecture is well-documented across both cloud and on-premises environments.
Database passwords in environment variables. API keys in ConfigMaps. Cloud credentials baked into image layers during build. These are not uncommon patterns — they are the default patterns in many Kubernetes environments. Every one of them represents a credential that is accessible to any workload with read access to the namespace, visible in process listings, and permanent unless manually rotated. The fix is architectural: eliminate static credentials from the deployment surface entirely and replace them with dynamic, short-lived credentials injected at runtime.
OPA/Gatekeeper policies exist in staging. They are not deployed in production because “we’ll add that next sprint.” Pod Security Standards are configured in audit mode — violations are logged but not blocked. Admission webhooks are deployed but scoped only to specific namespaces, leaving others unprotected. The policy exists. The enforcement does not. A policy that does not block is not a security control — it is a monitoring tool. Admission enforcement must be active and cluster-wide, not advisory and scoped.

Decision Framework
Not every environment requires the same depth of container security controls. The decision framework below maps environment type to required security depth, recommended approach, and primary control priority. Use it to scope the implementation — not to justify skipping controls, but to sequence them correctly for your risk profile.
| Environment | Security Depth | Recommended Approach | Primary Control | Risk Profile |
|---|---|---|---|---|
| Development cluster | Baseline | Pod Security Standards (restricted), basic RBAC, no privileged containers | Admission control | Low — internal use, no production data |
| Staging / pre-production | Moderate | Full NetworkPolicy, image scanning pipeline, OPA/Gatekeeper active | NetworkPolicy + admission | Medium — may mirror production configuration |
| Production SaaS | High | All five layers active, default-deny NetworkPolicy, workload identity, Vault/KMS | Identity + secrets | High — customer data, internet-exposed |
| Multi-tenant production | High | Namespace isolation enforced, strict RBAC, network segmentation per tenant, runtime detection | RBAC + NetworkPolicy | High — tenant isolation is a contract |
| Regulated workloads (PCI/HIPAA/SOC2) | Maximum | Full stack + sandbox runtimes, mTLS, audit logging, immutable infrastructure, continuous re-scanning | Compliance posture | Critical — regulatory consequence of breach |
| Edge / IoT deployments | Selective | Lightweight runtime, minimal base images, identity-based access to central services | Supply chain + identity | Context-dependent — varies by exposure |
When This Model Is Overkill
A complete five-layer container security architecture with service mesh, Vault integration, workload-specific seccomp profiles, and OPA/Gatekeeper policy enforcement is not the right investment for every environment. Credibility requires saying so explicitly.
For small teams running internal tooling on a single-tenant cluster with no customer data and no regulated workloads, the full stack is more operational overhead than the risk profile justifies. The correct starting point is Pod Security Standards (restricted mode), default-deny NetworkPolicy, and basic RBAC hygiene — not Vault, not Falco, not a service mesh. These three controls eliminate the most common failure modes without the operational complexity that the full stack requires.
For simple monolithic applications being containerized for the first time, the priority is getting the container security basics right before layering advanced controls. Rootless containers, no privileged mode, no host path mounts, and secrets not in environment variables covers the majority of the risk surface for a straightforward single-service deployment.
The calibration question is proportionality: does the operational cost of the control match the value of the asset it protects and the likelihood of the threat it addresses? The decision framework table above provides the starting point. The answer to “how much security is enough” is always a function of your specific risk profile — not a generic best practice checklist applied uniformly.
You’ve covered container security architecture — the five enforcement layers, the failure modes, and the operational reality. The pages below cover what sits alongside it: the orchestration layer that security policy runs on, the microservices that security policy governs, and the cloud platforms that determine where the controls are implemented.
Architect’s Verdict
Container security is not a checklist you complete and file. It is an architecture you design, enforce at every layer, and maintain as the system evolves. The controls exist. The primitives are in the platform. The failure modes are documented and preventable. The gap between a secure container environment and an insecure one is not a gap in tooling — it is a gap in architectural intent, operationalized as policy that is either enforced or it isn’t.
Identity is the perimeter. Enforcement is the architecture. Build both.
You’ve Defined the Policy.
Now Test Whether It Actually Holds.
Seccomp profiles, AppArmor policies, network policy enforcement, image signing, and RBAC scope — container security is not configured once and forgotten. It drifts, it has gaps, and the gaps are usually in the places that weren’t tested. The audit finds them before an attacker does.
Container Security Audit
Vendor-agnostic review of your container security posture — image supply chain controls, runtime security profiles, network policy coverage, RBAC scope, pod security admission configuration, and the privileged container exposure that most Kubernetes environments accumulate silently.
- > Image supply chain and signing policy review
- > seccomp and AppArmor profile coverage audit
- > Network policy enforcement gap analysis
- > RBAC scope and privileged workload exposure assessment
Architecture Playbooks. Every Week.
Field-tested blueprints from real container security environments — seccomp vs AppArmor breakout analysis, network policy enforcement failures, image supply chain compromise case studies, and the runtime security patterns that actually stop container escapes.
- > Container Runtime Security & Breakout Prevention
- > Image Supply Chain & Policy Architecture
- > Network Policy & Zero Trust Enforcement
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is the difference between container security and VM security?
A: The core difference is the isolation model. VMs run separate guest operating systems on top of a hypervisor — a kernel vulnerability in one VM does not affect neighboring VMs because each has its own kernel. Containers share the host kernel. A kernel vulnerability or a container escape that breaks the namespace boundary affects every container on that node. VM security is built around the assumption of hard kernel isolation. Container security must compensate for the absence of that isolation through seccomp profiles, AppArmor policies, rootless execution, and sandbox runtimes like gVisor or Kata Containers. The network model also differs: VMs sit behind a virtual switch with explicit routing between segments, while Kubernetes pods are on a flat network by default with unrestricted pod-to-pod access unless NetworkPolicy is explicitly configured.
Q: Is image scanning enough to secure a container environment?
A: No — and treating it as sufficient is one of the most dangerous misunderstandings in container security. Image scanning detects known vulnerabilities in an image at a specific point in time. It says nothing about runtime behavior, RBAC configuration, network segmentation, secrets handling, or admission control. An image with a clean scan result can still be deployed with a root container, a default ServiceAccount with cluster-admin rights, no seccomp profile, and access to every pod in the cluster over an unsegmented network. The scan passed. The security posture is broken. Image scanning belongs in Layer 1 of a five-layer security architecture — supply chain integrity. The other four layers — registry and admission, runtime isolation, network and identity, and secrets management — are equally necessary and frequently underinvested.
Q: What is the most common Kubernetes security misconfiguration in production?
A: Overprivileged ServiceAccounts. The majority of Kubernetes security incidents trace back to a ServiceAccount that was granted more permissions than the workload required — often because a Helm chart installed with broad RBAC defaults, a developer granted cluster-admin for convenience during setup, or a default ServiceAccount was never scoped down from its namespace-wide read access. The blast radius of a compromised container is directly determined by the permissions of its ServiceAccount. A container with a read-only ServiceAccount scoped to a single namespace is a dead end for an attacker. A container with cluster-admin or list/get on all secrets is a cluster-level incident. Least-privilege RBAC design — scoped to namespace, scoped to specific resources and verbs, with no cluster-wide permissions unless explicitly justified — is the single highest-leverage security investment in most Kubernetes environments.
Q: What is the difference between NetworkPolicy and a service mesh for container security?
A: They operate at different layers and solve different problems — they are complementary, not alternatives. NetworkPolicy operates at Layer 3 and Layer 4: it controls which pods can communicate with which other pods based on IP addresses and ports. It is enforced by the CNI plugin and requires no changes to application code. A service mesh operates at Layer 7: it controls traffic based on service identity, HTTP methods, request paths, and headers, and provides mutual TLS between services for cryptographic authentication and encrypted transit. NetworkPolicy is the right first control for east-west segmentation — default-deny per namespace with explicit allow rules. A service mesh is the right next control when the architecture requires cryptographic service identity, mTLS encryption, or policy enforcement that goes beyond port-level segmentation. For most production environments, the sequence is: NetworkPolicy first, service mesh when the requirements justify the operational overhead.
Q: How should secrets be managed in a Kubernetes environment?
A: The architectural goal is elimination of static long-lived credentials from the deployment surface entirely. The progression from lowest to highest security: environment variables (never — visible in process listings and logs), Kubernetes Secrets without etcd encryption (inadequate — base64 encoded, not encrypted), Kubernetes Secrets with etcd encryption at rest (acceptable minimum), External Secrets Operator syncing from AWS Secrets Manager, GCP Secret Manager, or Azure Key Vault (good — centrally managed, rotation supported), Vault Agent Injector with dynamic short-lived credentials (better — credentials expire after TTL), workload identity federation with cloud KMS (best — no credentials stored anywhere, pod identity bound directly to cloud IAM). The key principle: a credential that expires in 15 minutes is architecturally superior to a rotated static credential, because the stolen credential problem becomes self-resolving.
Q: What is admission control and why does it matter for container security?
A: Admission control is the gate between what teams want to deploy and what the Kubernetes cluster will accept. When a pod creation request hits the API server, admission webhooks intercept it before the resource is persisted to etcd and evaluate it against configured policy. If the pod requests a privileged container, runs as root, or uses an unsigned image — and the policy prohibits those things — the request is rejected before the pod ever runs. This is the architectural significance: admission control converts security policy from a recommendation into an enforcement mechanism. OPA/Gatekeeper and Kyverno are the primary policy engines for Kubernetes admission control, providing custom policy authoring beyond the built-in Pod Security Standards. The critical operational point: admission webhooks configured in audit mode log violations but do not block them. Audit mode is a monitoring tool. Enforcement mode is a security control. Deploying admission control in audit-only and calling it enforced is one of the five named failure modes in production container security.
Q: When should a service mesh be added to a container security architecture?
A: When the security requirements exceed what NetworkPolicy can provide. Specifically: when east-west traffic requires encryption in transit (NetworkPolicy does not encrypt), when service-to-service authentication requires cryptographic identity proof rather than IP-based trust (NetworkPolicy is IP and port only), when traffic policy needs to operate at Layer 7 on HTTP methods, headers, or request paths, or when the environment has compliance requirements for mTLS between all internal services. A service mesh adds operational complexity — sidecar proxies, control plane management, certificate rotation, latency overhead — that is justified when the security requirements listed above are present. For environments without those requirements, NetworkPolicy plus RBAC is the correct baseline. The service mesh is the architectural evolution of network security for mature container environments, not a day-one control for every cluster.
Q: What does “zero trust” mean specifically in a Kubernetes environment?
A: In a Kubernetes context, zero trust means treating no workload as trusted by virtue of its network position inside the cluster. It operationalizes as five concrete architectural decisions: identity-based access (every access decision uses verified workload identity, not IP address), mTLS between all services (cryptographic authentication on both sides of every connection), least privilege at every layer (RBAC, NetworkPolicy, IAM, and seccomp all scoped to minimum required function), continuous verification (admission controllers re-evaluate on every deployment, credentials expire and are re-issued, runtime monitors verify behavior continuously), and policy enforcement at multiple independent layers (supply chain, admission, runtime, network, and identity policies operate in depth — a failure at one layer does not create an unrestricted path through the system). Zero trust in containers is not a product or a platform feature — it is the cumulative result of implementing all five of these principles consistently.