Recovery Is The Only SLA That Matters.
Most organizations are over-invested in backup and under-invested in recovery.
They have backup jobs running. They have retention policies configured. They have snapshots accumulating. What they don’t have is a tested, isolated, provable path to recovery under adversarial conditions.
Data protection is not about storing copies. It is about controlling blast radius and guaranteeing recovery when everything else has already failed.
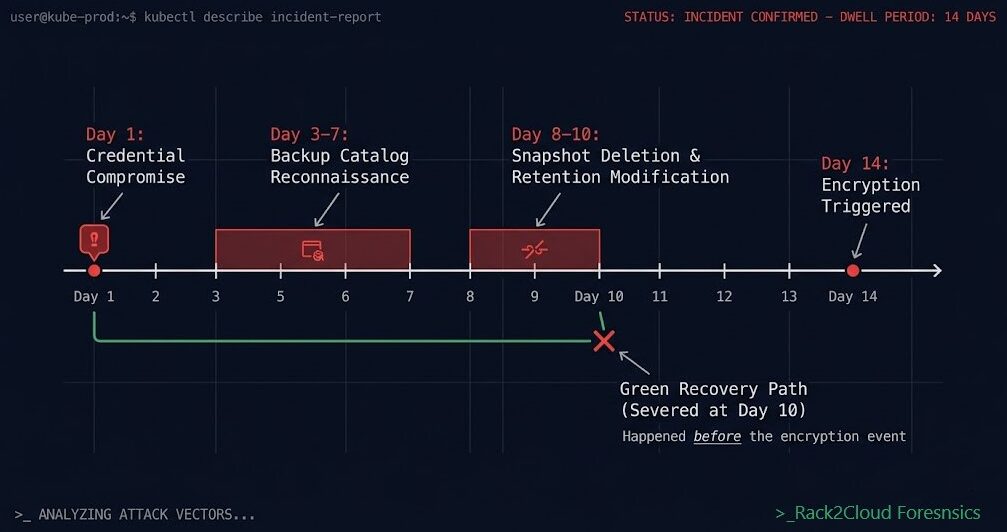
The distinction matters because attackers understand it. Ransomware operators don’t target your data — they target your recovery path. Credential compromise doesn’t end with encryption — it ends with backup catalog deletion, snapshot destruction, and control plane lockout. By the time encryption runs, the recovery path has already been severed. The six attack patterns that defeat standard backup architecture all follow the same sequence: sever recovery first, encrypt second.
This is the architecture that rebuilds it.
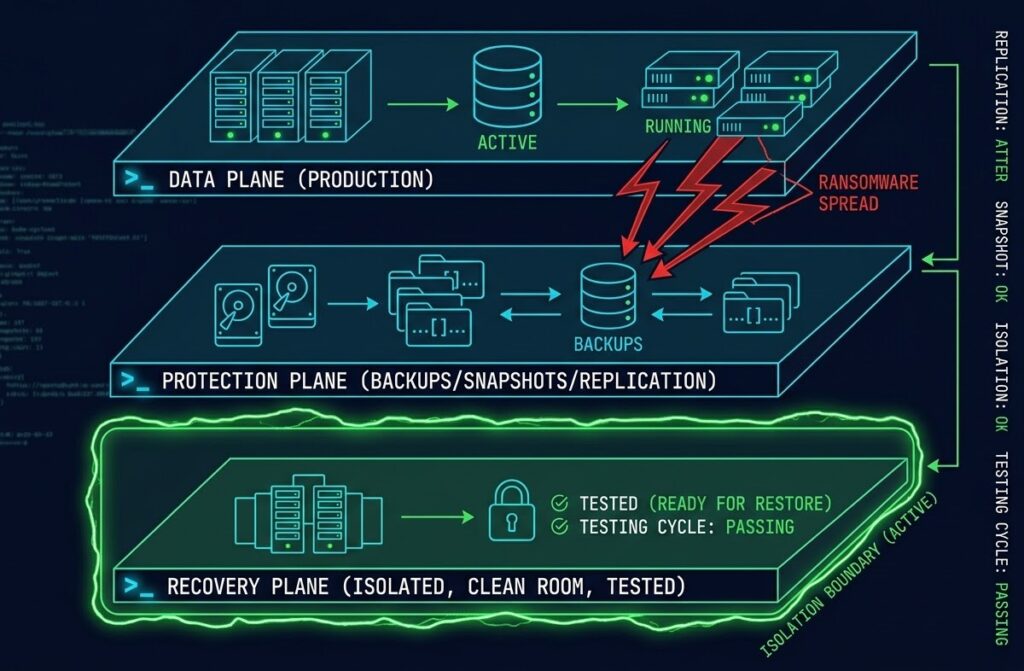
What Data Protection Actually Is
Data protection is three separate control planes operating in sequence. Most architectures build the first two and assume the third is implied. It isn’t.
The Data Plane is where production data lives — databases, file systems, object storage, containerized workloads. This is the asset being protected.
The Protection Plane is where snapshots, backups, and replication live — the copies of the data plane maintained for recovery. Most organizations have this. Most consider it sufficient. It isn’t.
The Recovery Plane is the isolated, tested, usable path back to production. Clean room environments. Staged restore sequences. Identity systems that weren’t compromised with the production environment. Network isolation that prevents re-infection. Validation before reconnection.
The recovery plane is where data protection actually lives — and where most architectures have the largest gap.
A backup you haven’t restored is a theory. The recovery plane is what makes it proof.
How Systems Actually Fail
Most backup failures are not data loss events. They are recovery failures.
The data exists. The snapshots ran. The replication completed. And when the incident happens, none of it matters — because the recovery path was severed before encryption ran, or the backup environment shares credentials with the compromised production environment, or the recovery destination isn’t network-isolated, or the restore was never tested against the actual workload.
| Failure Type | Why Protection Fails |
|---|---|
| Ransomware | Backup catalog deleted before encryption — recovery path severed, not just data encrypted |
| Snapshot Corruption | Snapshots exist but are application-inconsistent — restore produces a broken workload |
| Replication of Bad State | DR replica faithfully replicates the compromised state — both sites are now infected |
| Identity Compromise | Admin credentials compromised — attacker logs into backup platform and deletes retention |
| Configuration Drift | Recovery environment diverges from production — restore succeeds but application fails |
| Egress Blindness | Recovery from cloud object storage triggers egress charges that weren’t modeled — you don’t pay for egress during normal operations, you pay for it when everything is already broken |
The common thread: none of these are storage failures. They are architecture failures.
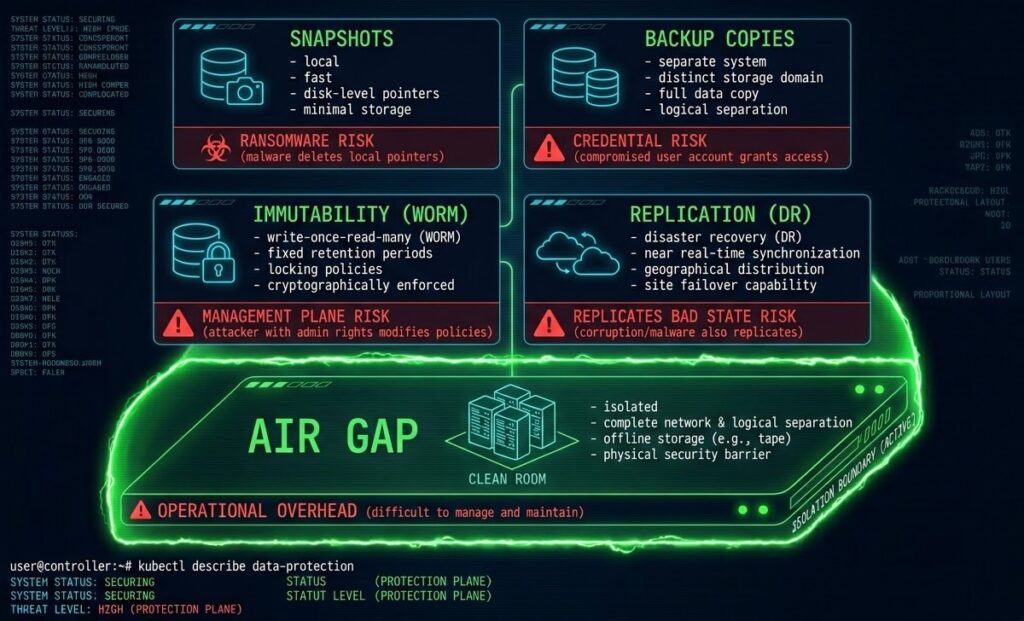
The Protection Primitives
Data protection is built from five architectural primitives. Each solves one failure mode. None solve all of them.
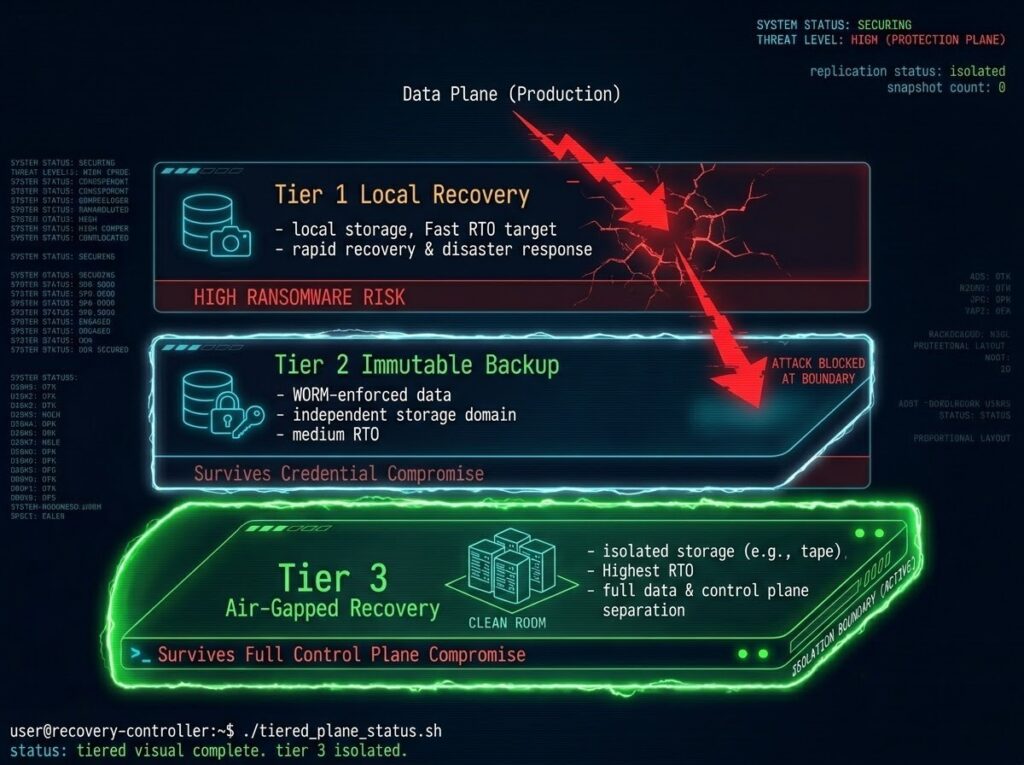
The Three-Tier Protection Model
Complete data protection architecture requires all three tiers. An architecture missing any one of them has a gap that will surface under the right failure condition.
If all three tiers don’t exist independently, you don’t have a complete protection architecture. You have a partial one — and partial architectures fail completely under adversarial conditions.
Identity Is the Real Control Plane
Attackers don’t break storage. They log in.
The most common data protection failure pattern isn’t a technical vulnerability — it’s a privileged credential. Backup administrators with domain admin equivalents. API tokens with deletion rights stored in the same credential vault as production secrets. MFA gaps on backup management consoles. Role assignments that give a single compromised account the ability to delete the entire retention catalog.
The identity architecture around your protection plane determines whether your backups survive a full environment compromise — not the backup software itself.
The three identity controls that determine protection survivability:
Separate identity planes — backup admin credentials must not exist in the same identity provider as production admin credentials. If your AD is compromised, your backup console should still require a credential that wasn’t in that AD.
MFA on all deletion operations — not just login. Every snapshot deletion, retention policy change, and catalog modification requires a second factor that isn’t stored in the compromised environment.
Role separation at the API layer — the service account that runs backup jobs should not have the rights to modify retention policies. Write access and delete access are different permissions that most platforms separate — most teams don’t.
The identity plane architecture that makes immutability real — not just WORM storage, but credential separation and API-level deletion controls — is the difference between compliance theater and actual ransomware survivability.
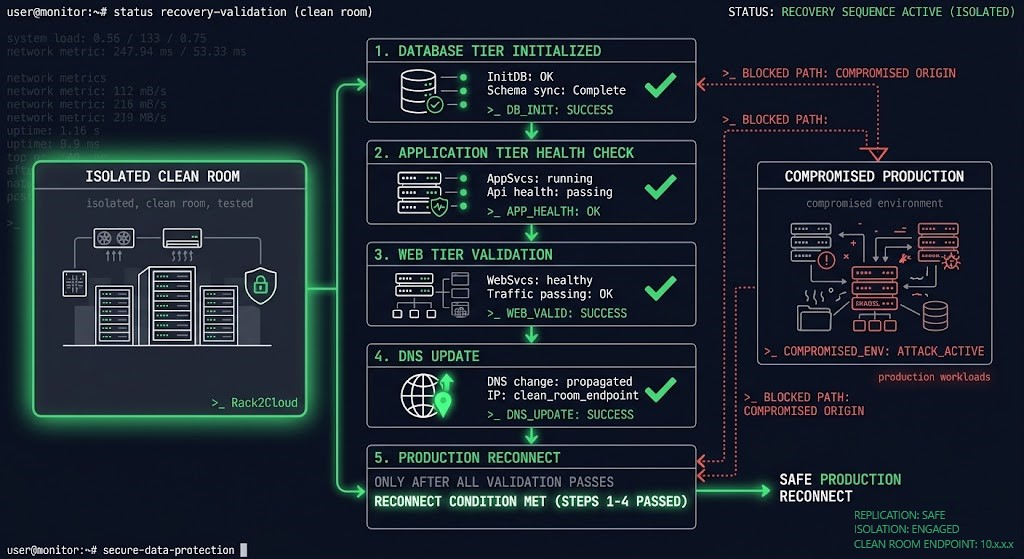
Recovery Architecture
Recovery is a system, not an event.
Most disaster recovery plans describe what to recover. Few describe the environment recovery happens into. The clean room. The network isolation. The identity sources that weren’t compromised. The validation sequence before production traffic reconnects.
A restore that succeeds but reconnects to a still-compromised network is not a recovery — it is a re-infection.
The recovery architecture that works under adversarial conditions requires four components:
Clean room environment — isolated compute and network that has no path to the production environment or its identity systems. Recovery happens here before anything is reconnected.
Staged restore sequence — not all workloads come back simultaneously. Database tier before application tier. Application tier health-checked before web tier. DNS updated only after application stack is validated. The sequence is the DR plan.
Identity bootstrap — a minimal identity source that exists independently of the production identity plane. Directory services, certificate authorities, and secret stores that were never connected to the compromised environment.
Validation before reconnect — every restored workload is validated at the application level before network paths to production are re-established. A VM that boots is not a recovered application. An application that passes a defined health check is.
The RTO Reality post covers why recovery drills are the only way to validate this architecture before the incident that requires it. The RTO, RPO, and RTA framework covers how to use recovery metrics as architectural inputs — not post-incident measurements.
The Cost Physics of Protection
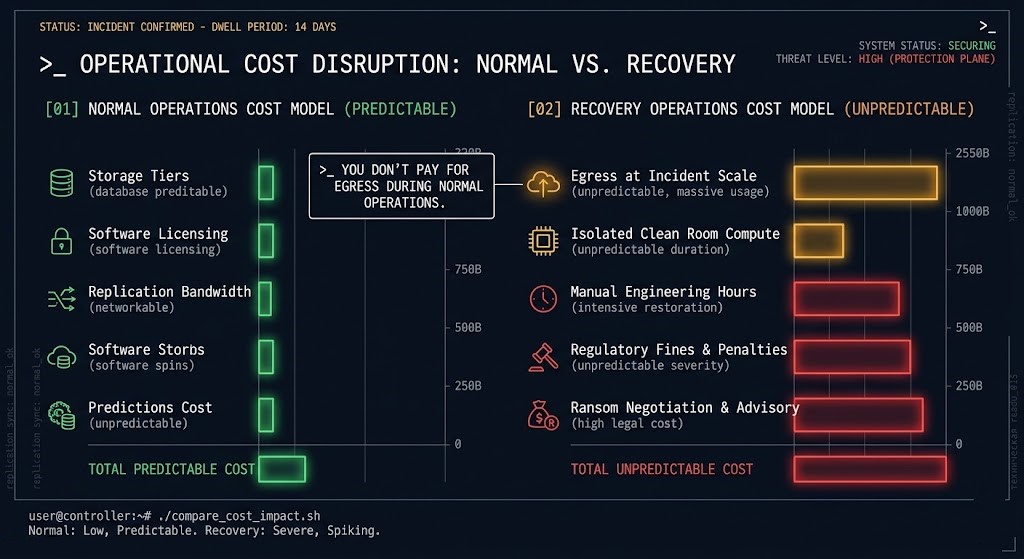
Data protection has two cost models. Most organizations model the first and discover the second during an incident.
Normal operations cost: Storage tiers, backup software licensing, replication bandwidth, retention infrastructure. These are predictable, budgeted, and visible on every infrastructure invoice.
Recovery cost: Egress from cloud object storage at incident scale. Compute for clean room environments that weren’t provisioned. Manual engineering hours during unplanned outages. Regulatory penalties for missed RTO/RPO SLAs. Ransom demands that are negotiated against a recovery timeline you can’t meet.
You don’t pay for egress during normal operations. You pay for it when everything is already broken — when you’re restoring hundreds of terabytes from cloud object storage under incident pressure, and the egress bill arrives alongside the recovery timeline.
The economics of data protection invert under failure. Cheap backups become expensive recoveries. Over-investment in Tier 1 local snapshots at the expense of Tier 2 and Tier 3 produces an architecture that is cheap to operate and catastrophic to recover from.
Model the failure-state cost, not the steady-state cost. The backup rehydration bottleneck post covers exactly how deduplication economics that look efficient during normal operations become recovery performance killers when RTO is measured in hours.
Protection Maturity Model
| Level | Description | What You Have |
|---|---|---|
| Level 1 | Backups exist | Jobs running, snapshots accumulating, no verified recovery path |
| Level 2 | Backups + immutability | WORM storage or object lock — deletion-resistant but untested |
| Level 3 | Segmented blast radius | Identity separation, role isolation — compromised production can’t reach backups |
| Level 4 | Tested recovery | Regular restore drills with application-level validation — recovery is proven, not assumed |
| Level 5 | Isolated recovery environment | Clean room, air-gapped tier, independent identity — survives full control plane compromise |
Most organizations operate at Level 2. Most ransomware attacks are designed to defeat Level 2 architectures. Level 3 and above is where recovery assurance begins.
Protection Strategy Decision Framework
| Requirement | Architecture Decision | Risk if Skipped |
|---|---|---|
| Low RTO | Snapshots + local replication | First target in ransomware — no recovery if Tier 1 destroyed |
| Compliance / Audit | Immutable storage + retention enforcement | Regulatory exposure if retention can be modified by compromised admin |
| Ransomware Survival | Separate identity plane + immutable Tier 2 | Full recovery path loss if backup admin credentials are shared |
| Zero Trust Recovery | Air gap + identity isolation + clean room | Re-infection if recovery environment has any path to compromised production |
| Cloud Workloads | Object storage with object lock + egress modeling | Recovery cost shock — egress at incident scale is not in the normal operations budget |
Workload-Based Protection Model
Protection investment scales with workload criticality. The architecture doesn’t change — the tier depth and recovery assurance requirements do.
Tier 0 — Mission Critical (transaction databases, identity systems, core infrastructure) All three protection tiers required. Tested recovery mandatory. Independent identity plane. Air-gapped copy with defined RTO. Recovery drill frequency: quarterly minimum. The application consistency requirements for database backup are non-negotiable at this tier — crash-consistent snapshots are not a database backup.
Tier 1 — Business Critical (application servers, file services, collaboration platforms) Tier 1 and Tier 2 required. Immutability mandatory. Recovery tested annually minimum. Blast radius modeled and documented.
Tier 2 — Operational (dev/test, non-production workloads, archival systems) Tier 1 sufficient with documented exception. Snapshot retention policy defined. Recovery path documented even if not regularly tested.
When Your Protection Strategy Fails
Honest failure conditions — the scenarios where a technically correct backup architecture produces an unrecoverable incident:
No immutability — snapshots and backup copies exist but can be deleted by any compromised admin account. Recovery path is destroyed before encryption runs.
Shared credentials — backup admin credentials live in the same identity plane as production. Credential compromise is complete environment compromise.
No recovery testing — backups run successfully for years. First restore attempt happens during an incident. Application-level inconsistencies surface only under production load.
Replication-only DR — DR site is a faithful replica of the production environment, including its compromised state. Failover to DR reproduces the incident, not the recovery. The 72-hour restore failure case study covers exactly how this plays out in production.
Egress blindness — recovery architecture requires restoring from cloud object storage at scale. Egress cost was never modeled. Recovery timeline is extended by cost approval processes during an active incident.
You’ve seen how data protection is architected. The pages below cover the five execution domains — the operational layers where recovery strategy becomes engineering reality. Each is a standalone architecture discipline. Each must connect to the others.
The data protection decision is the survival architecture. The pages below are the execution layers — pick the path that matches your threat model and recovery requirements.
Architect’s Verdict
Most organizations are over-invested in backup and under-invested in recovery.
The investments are real — backup software licenses, snapshot storage, replication bandwidth, DR site infrastructure. The gap is in what happens after the backup runs. Whether the recovery path was tested. Whether the identity plane was isolated. Whether the recovery environment is clean and provable before production traffic reconnects.
Data protection is not a technology problem. It is an architecture problem. The technology works. The failure is in how the layers connect — and whether the recovery plane, the tier that matters most, was built with the same rigor as the protection plane.
RPO and RTO are architectural inputs. Recovery Assurance is the architectural output. The only way to know if your architecture produces it is to test the recovery — not the backup.
You’ve Built the Backup Strategy.
Now Find Out If It Actually Recovers.
Immutability claims, RTO/RPO commitments, air-gap architecture, and ransomware survival — most data protection strategies look correct until the recovery drill exposes the gaps. The triage session validates whether your specific environment can actually meet its recovery commitments before a ransomware event does it for you.
Data Protection Architecture Audit
Vendor-agnostic review of your data protection posture — immutability implementation, backup control plane exposure, air-gap architecture validity, RTO/RPO model against your actual recovery infrastructure, and ransomware survivability under adversarial conditions.
- > Immutability implementation and storage-layer validation
- > Backup control plane exposure and credential audit
- > RTO/RPO model vs actual recovery infrastructure
- > Ransomware survivability and recovery runbook review
Architecture Playbooks. Every Week.
Field-tested blueprints from real data protection environments — ransomware attack simulations, backup control plane compromise case studies, RTO failure post-mortems, and the immutability architecture patterns that actually survive adversarial conditions.
- > Ransomware Survival & Recovery Architecture
- > Immutability Implementation & Validation
- > RTO/RPO Physics & Recovery Drill Analysis
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: Is backup the same as data protection?
A: No. Backup is a copy of data. Data protection is the architecture that ensures that copy can be recovered under the conditions you’ll actually face — including adversarial conditions where the attacker has had days to prepare before you know anything happened.
Q: Are snapshots a backup?
A: Snapshots are a recovery tool, not a backup. They live on the same storage platform as the production data they protect. Ransomware that compromises your storage admin account deletes both simultaneously. A backup requires a copy on a separate system, separate credentials, and ideally separate physical media.
Q: How often should recovery be tested?
A: Tier 0 workloads: quarterly minimum. Tier 1: annually minimum. The frequency matters less than what you test — application-level recovery, not just VM boot. A VM that boots is not a recovered application.
Q: What breaks first in ransomware?
A: The backup catalog. Before encryption runs, sophisticated ransomware operators delete backup jobs, shorten retention windows, and remove snapshot schedules. The attack on your recovery path precedes the attack on your production data by days.
Q: Is replication enough for DR?
A: No. Replication produces a consistent copy of your data — including any compromised or corrupted state. DR replication that runs during an active ransomware dwell period faithfully replicates the infection to the DR site. Replication is a component of DR architecture, not a substitute for it.
Q: What is an air gap in 2026?
A: A true air gap means not reachable via network, not reachable via identity, not reachable via API, and not reachable via any automated process your compromised environment can trigger. The moment your “air-gapped” backup can be reached by anything your compromised environment can reach — it is not air-gapped. Connected air gaps are compliance theater.