Client’s GKE Cluster Ate Their Entire VPC: The IP Math I Uncovered During Triage
The Triage: GKE Pod Address Exhaustion
GKE pod IP exhaustion is one of the few failure modes that gives you no warning before it goes terminal. I recently stepped into a war room where a client’s primary scaling group had flatlined — workloads cordoned, deployments stuck in Pending, and the estimated cost of the stall nearing $15k per hour in lost transaction volume. The culprit wasn’t traffic. It was a /20 subnet that had quietly run out of address space, and a set of GKE allocation defaults nobody had questioned at design time.
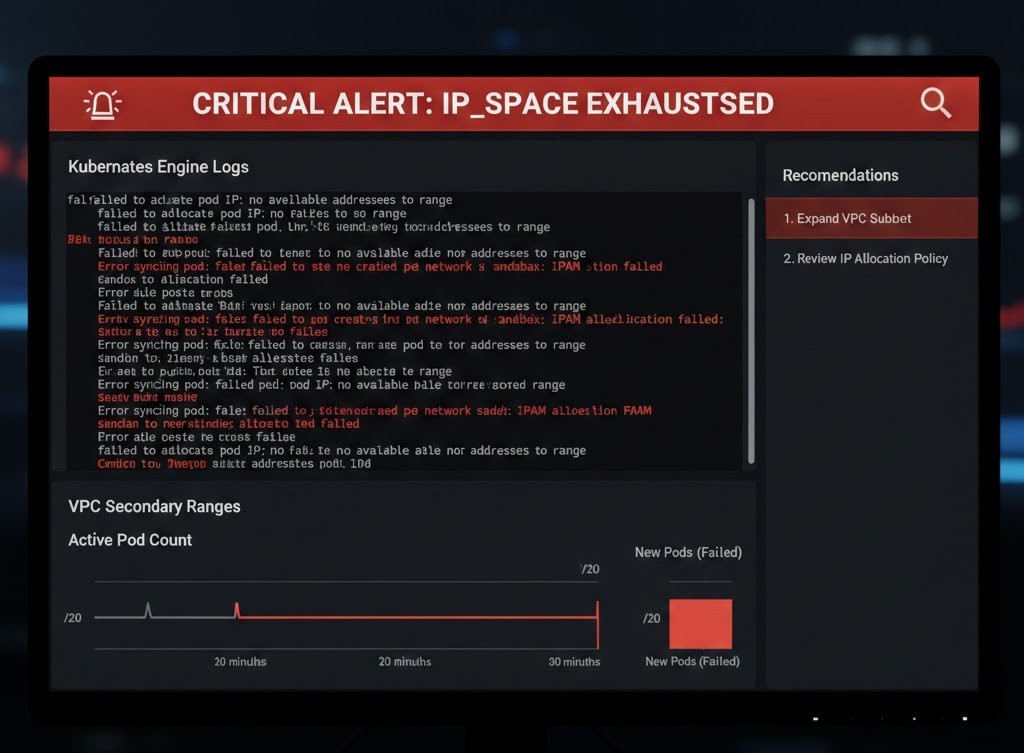
The Math of the “Hidden Killer”
This is where the Cloud Strategy usually falls apart: improper VPC sizing. GKE reserves a static alias IP range for pods per node. By default, it anticipates 110 pods per node. To satisfy that without fragmentation, GKE allocates a /24 (256 IPs) to every single node, regardless of whether that node runs 100 pods or just one.
Here is the breakdown of why that /20 evaporated:
| Waste Type | IPs/Node (Default) | /20 Capacity (4,096 IPs) | Reality Check |
| Pod Reservations | 256 (/24) | 16 Nodes Max | Hard ceiling for the entire VPC. |
| Services (ClusterIP) | 50 (Static) | 2-3% of total | Reserved upfront. |
| Buffer/Fragmentation | ~100 | N/A | The “invisible” cost of bin-packing. |

16 nodes. That’s the hard limit.
In a modern Modern Infra & IaC environment, hitting 16 nodes during a traffic spike is trivial. Once you request the 17th node, GKE cannot provision the underlying Compute Engine instance. The VPC-native alias range is dry.
Taxonomy of Waste
Most engineers check kubectl top nodes, see 40% CPU utilization, and assume they have runway. They don’t. In cloud networking, Address Space is a Hard Constraint, just like IOPS or thermal limits.
- Overprovisioning: The client kept 3 empty nodes for “fast scaling.” Total cost? 768 IPs locked up, doing absolutely nothing. (This specific type of “idle tax” is a primary driver behind our K8s Exit Strategy framework).
- CIDR Fragmentation: Because the secondary ranges weren’t sized for non-contiguous growth, we couldn’t simply append a new range to the existing subnet.
- The “Shadow” Nodes: Abandoned node pools that hadn’t been fully purged still held onto their
/24leases.
The Impact
The result wasn’t just “no new pods.” It was a cascading failure:
- HPA (Horizontal Pod Autoscaler) triggered scale-up events that failed immediately.
- Critical Patches couldn’t deploy because there was no “surge” space for rolling updates.
- Service Instability: Standard Kubernetes Services began to flap as
kube-proxystruggled with the incomplete endpoint sets.
The “Nuclear Option” vs. Actual Engineering
The standard playbook for GKE pod IP exhaustion suggests a full VPC rebuild: tear it down, provision a /16, and migrate the data. While that guarantees a fix, it’s a brute-force approach that introduces massive risk—DNS propagation issues, downtime, and weeks of testing.
We didn’t rebuild the VPC. We didn’t nuke the project. We utilized Class E space (240.0.0.0/4)—a “reserved” and largely forgotten corner of the IPv4 map that most vendors pretend doesn’t exist. We unlocked millions of IPs without moving a single workload offline.
I’m finalizing the documentation on the exact gcloud commands and routing adjustments we used.
Part 2: The Class E Rescue Guide [Coming Soon]
Architect’s Verdict
GKE pod IP exhaustion is not a networking failure. It is a capacity planning failure that gets diagnosed as a networking failure at the worst possible moment. The /20 default feels generous until you understand that GKE reserves a /24 per node regardless of pod density — and at that point you have 16 nodes and a hard ceiling, not a subnet.
The fix in this case was unconventional. Class E space is not what most architects reach for under pressure, and it is not universally supported across tooling and vendors. But the alternative was a VPC rebuild mid-incident, which introduces more risk than it resolves. The broader lesson is not about Class E — it is that address space needs to be modeled at design time the same way IOPS or throughput gets modeled. It is a hard constraint, not a soft one. By the time the HPA is firing scale-up events into a dry range, the architectural decision that caused it is weeks or months in the past.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




