The Storage Wall: ZFS vs. Ceph vs. NVMe-oF for AI Training Clusters

The Real Problem: The “Checkpoint Stall”
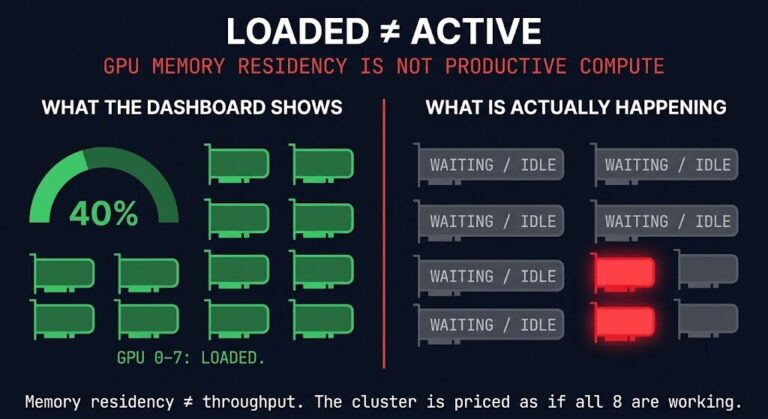
A 16x H100 cluster costs roughly $40/hour to sit idle. When your AI training storage can’t ingest a 2.8 TB Adam optimizer checkpoint fast enough, your GPUs wait — and your training run stalls.
Most AI clusters fail not because the GPUs are slow, but because the storage collapses under the brutal weight of checkpointing and training I/O workloads. In the race to build the fastest model, storage is no longer just plumbing — it is the throttle on your GPUs.
This problem sits within the broader challenges of AI infrastructure design, where compute, network, and storage all interplay. For a deeper look at infrastructure stacks and how storage sits alongside compute and networking, see the GPU Cluster Architecture guide on Rack2Cloud.
The Contenders: Vendor Promises vs. Practical Reality
ZFS (The Reliable Workhorse)
The Promise: Rock-solid data integrity, ARC caching, and ease of management.
The Reality: Scale-out ZFS often turns into a Frankenstein of complexity. In practice, multi-node ZFS clusters can fail under sustained checkpoint bursts because they weren’t designed for the massive concurrent throughput modern H100 fabrics demand.
ZFS’s design (as a local, transactional filesystem with strong data guarantees) shines in many traditional workloads — but its architectural limits show under distributed AI training load. For a more architectural comparison of these stacks (beyond performance), see the ZFS vs Ceph vs NVMe-oF Architecture Guide.
For foundational logic and physics behind storage performance, the Storage Architecture Learning Path explains why storage latency and queue management dominate cluster behavior more than raw device speed.
Ceph (The Sovereign Giant)
The Promise: Limitless scale and no single point of failure.
The Reality: The “latency tax” is real. CRUSH maps and distributed object layers are elegant — but the overhead of replication and network hops can kill training throughput unless you have a 400 GbE RoCE fabric and a team that knows how to run it.
Ceph’s architecture—object storage with metadata services and OSD layers—delivers flexibility and availability at massive scale. But every extra layer adds latency, which is deadly for bursty, checkpoint-heavy workloads.
NVMe-oF (The New Speed King)
The Promise: Near-local NVMe speeds across the network (PCIe extension).
The Reality: It’s “lossless or nothing.” NVMe-oF demands pristine network configuration — any packet loss or buffer misconfiguration can hang the kernel or kill the training job outright.
NVMe-oF’s architectural promise of disaggregated performance is real, but that value comes only with the right network fabric and operational discipline.
What Actually Breaks at Scale (The War Stories)
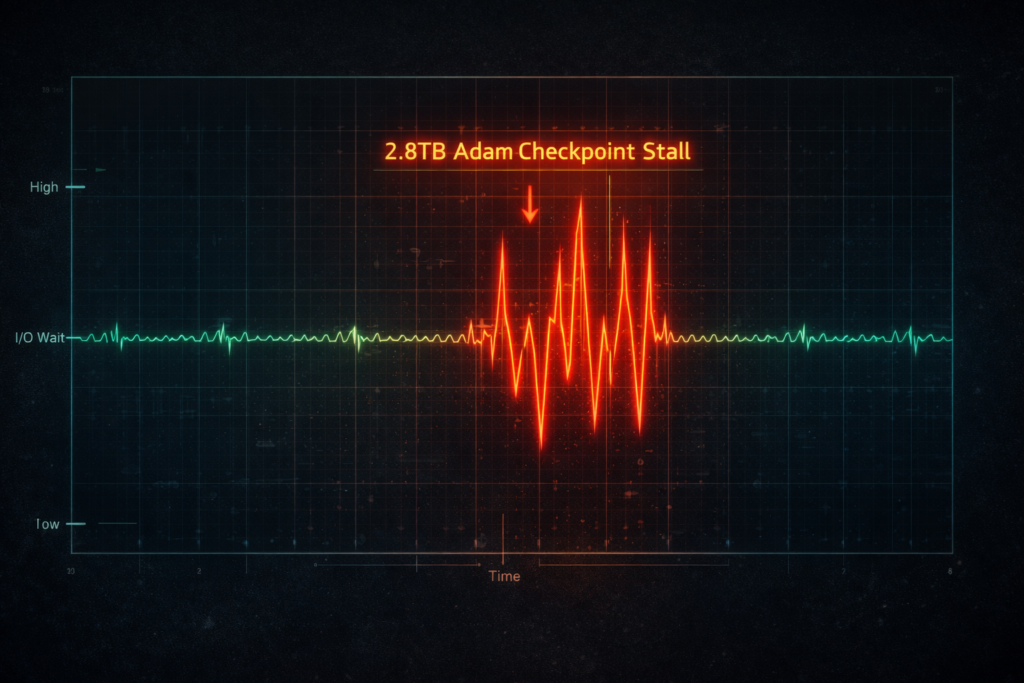
Latency Amplification: A single overloaded Ceph OSD can push PyTorch step times from 200ms to 2.5s — not because the GPUs were slow, but because the storage fabric jittered, forcing the training loop to wait on I/O.
Recovery Bottlenecks: When a drive fails in a production ZFS node, the resilver process can consume up to 60% of your backplane bandwidth. If this happens mid-training, your entire “Training-to-Model” timeline can double.
Network Saturation: Storage bursts and NCCL/GPUDirect traffic can collide on shared fabrics unless properly isolated with QoS or dedicated networks. This conflict is a common root cause of mysterious performance drops in tightly coupled AI systems.
If you want a broader understanding of how compute, networking, and storage interplay in distributed architectures, check out Rack2Cloud’s AI Architecture Learning Path.
Performance & Reliability Comparison
| Feature | ZFS (TrueNAS or Ubuntu) | Ceph (RBD/CephFS) | NVMe-oF (TCP/RoCE) |
|---|---|---|---|
| Primary Strength | Data Integrity / Snapshots | Limitless Scale-Out | Near-Local Latency |
| Operational Risk | Low | High | Medium-High |
| Max Scalability | Limited (Vertical) | Infinite (Horizontal) | High (Fabric-dependent) |
| Complexity | Low to Medium | High (24/7 Ops) | Medium (Network-heavy) |
| Best Use Case | Small/Mid Dev Clusters | Massive Multi-tenant Labs | Tier-0 Production Training |
Which Stack Fits Which Workload?
Training & Checkpoint-Heavy Jobs: NVMe-oF is the gold standard — if you have the networking chops.
Inference & Data Lakes: Ceph shines here — relaxed latency tolerance and capacity scalability make it efficient for mixed workload clusters.
Research & Prototyping: ZFS remains an excellent choice for predictable performance with minimal distributed complexity.
Hybrid Architectures: For budget-constrained teams who still need performance, pairing ZFS metadata + NVMe-oF checkpoints balances cost and speed effectively.
For architectural insights into hybrid and multi-tier storage stacks, see the ZFS vs Ceph vs NVMe-oF Architecture Guide.
Architect’s Verdict: What to Deploy Today
If you are building a cluster under 32 nodes, do not over-engineer — go ZFS on NVMe. It’s reliable and easier to troubleshoot.
If you are scaling to 100+ nodes and have the budget for a dedicated storage team, Ceph offers sovereign scale and resilience.
However, if you need the absolute lowest time-to-train and your network team can manage a lossless fabric, NVMe-oF is the only way to fully realize the ROI of your GPU investment.
In AI infrastructure, storage isn’t plumbing — it’s the throttle on your GPUs.
The structured reading sequence for AI storage architecture — from data locality through checkpoint design through the Data Availability Boundary — is in the Storage & Data Pipeline Architecture stage of the AI Architecture Learning Path.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session