The Sovereign AI Mandate: Why Private Data Must Stay on Private Infrastructure

The “Samsung Moment”
Building sovereign AI infrastructure means keeping your most sensitive data on hardware you control — not feeding it to a public API and hoping for the best. It happens everywhere. The CEO storms in and asks: “Why aren’t we using ChatGPT to write our code?”
Legal chimes in: “What actually happens to that code once we paste it into the prompt?”
The real answer? It freaks people out.
Back in 2023, Samsung engineers did exactly that—they pasted their secret semiconductor code into ChatGPT, hoping to improve it. But that code didn’t just vanish. It became part of ChatGPT’s memory bank. They didn’t just leak a PDF; they handed over hard-earned IP to a black box they couldn’t control.
That’s the essence of the Sovereign AI Mandate. If your data is your edge—financial models, patient records, proprietary code—shipping it off to a public API isn’t ‘innovation.’ It’s reckless. The infrastructure model that keeps that data on hardware you control — including the fabric architecture underneath private AI deployments — is what the Distributed AI Fabrics strategy guide addresses directly.
You Are the Training Data
Public LLMs aren’t stateless calculators—they are persistent archives. When you use an API like OpenAI or Anthropic, two things happen most teams don’t realize:
- Retention: Your prompts are logged for “Safety and Quality Assurance.” Even if you opt out of training, your data still sits on their servers, accessible to engineers and whatever subpoenas come knocking.
- RLHF (Reinforcement Learning from Human Feedback): Correcting the model’s mistakes turns your engineers into unpaid data labelers. Congratulations: you just trained an AI that someone else owns—maybe even your competitor.
Rule of thumb: If the AI runs on a GPU you don’t own, the thought process belongs to someone else.
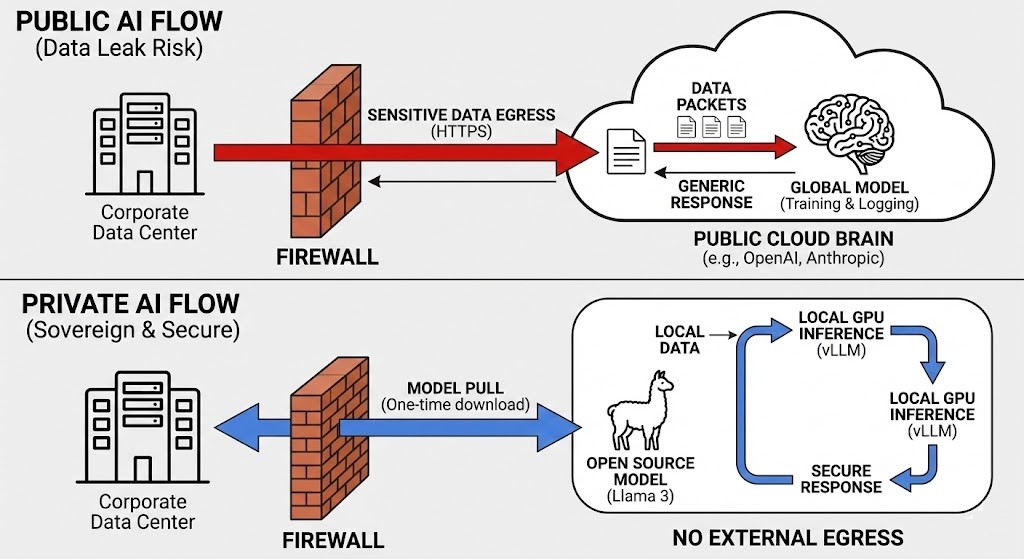
Air-Gapped Intelligence: How to Keep Control
Don’t ban AI. Take charge.
We’re in the golden age of open weights. Models like Llama 3, Mistral, and Mixtral can match GPT-4—and you can run them on your own workstation or server cluster.
Private RAG: Build Your Own Stack
You don’t need to train a model from scratch—that’s expensive and slow. Instead:
- Inference: Set up a local inference server like vLLM or Ollama on your GPUs. Their APIs mimic OpenAI’s, so your devs don’t have to relearn anything.
- Memory: Keep your PDFs, wikis, code repositories, and internal docs in a local vector database—think Milvus or Chroma.
- Orchestration: Use LangChain or LlamaIndex to tie it all together.
Now, when your team queries the system, it searches your private docs, sends the relevant pieces to your local LLM, and returns an answer.
Not a single byte leaves your network.
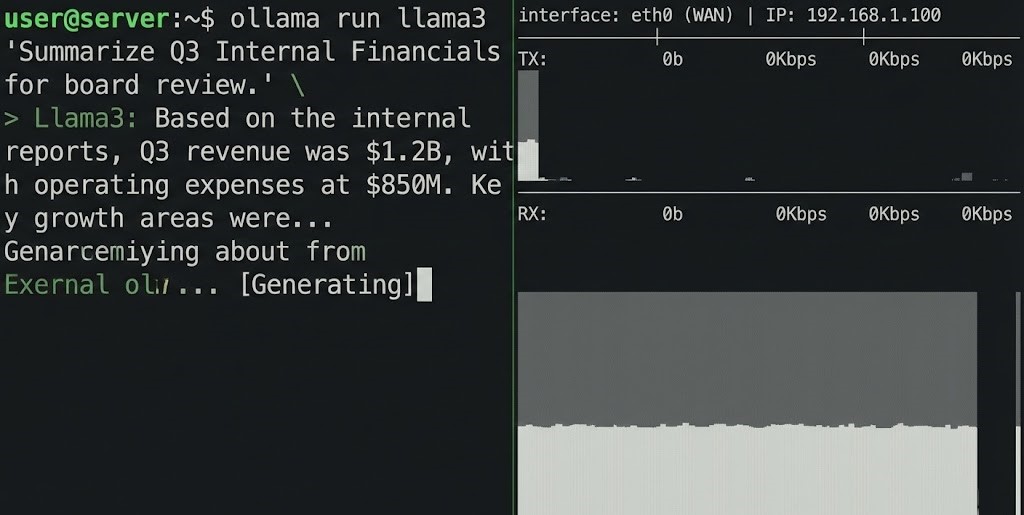
The Fabric Reality Behind Sovereign AI
Private AI infrastructure doesn’t fail at the model layer. It fails at the fabric layer. When you move inference on-premises, your GPU cluster becomes the bottleneck — and the network connecting it determines whether your sovereign AI stack performs or stalls.
Distributed training workloads require deterministic, low-latency east-west fabric with zero tolerance for packet jitter. A misconfigured leaf-spine topology or an undersized buffer allocation doesn’t just slow your training runs — it idles $40/hour worth of GPU compute waiting for gradient synchronization to resolve. The physics don’t change because the data is sovereign.
Before you finalize your sovereign AI infrastructure stack, the fabric layer needs the same architectural rigor as the model runtime. The Distributed AI Fabrics Strategy Guide covers the topology, congestion control, and failure domain decisions that determine whether your private AI cluster performs at scale or collapses under training load.
The Architect’s Verdict
Intelligence is becoming a utility, like electricity. But here’s the catch: the public “grid”—the cloud—remembers everything you feed it.
For trivial tasks like marketing emails or news summaries, public AI works fine. But for the heart of your business—drug discovery, algorithmic trading, proprietary algorithms—you need full ownership.
Key principles:
- Data Gravity: Moving a 40GB model to your local data lake is easier and safer than uploading terabytes of sensitive data to the cloud.
- Speed: Local NVMe + 100GbE smokes any API call bouncing back to Virginia.
- Real Security: The only API nobody can hack is one that never goes online.
If you are building your Modern Infrastructure Pillar, make room for GPUs—not just CPUs. AI is just another heavy-duty workload. Treat it like one.
Deep Research & References
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




