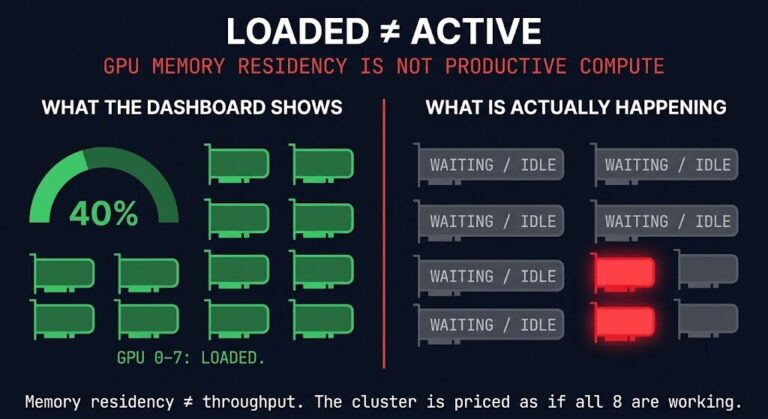
The Training/Inference Split Is Now Hardware — What GTC 2026 Actually Changed
The inference infrastructure decision most teams are ignoring isn’t the Vera Rubin GPU. It was not the $1 trillion demand forecast. It was not Jensen Huang calling NVIDIA “the inference king.”
The announcement that matters is the Groq 3 LPX — a dedicated inference rack shipping alongside the GPU rack. For the first time, NVIDIA is not selling you a GPU and telling you to run everything on it. They are selling you two separate systems for two separate workloads.
That is not a chip announcement. It is an architectural decision, made at the hardware level. The fabric architecture that makes that split possible at scale is covered in depth in the Distributed AI Fabrics strategy guide.
When the hardware splits, the architecture has to split with it. Most teams aren’t ready for that conversation.
What GTC 2026 Actually Announced
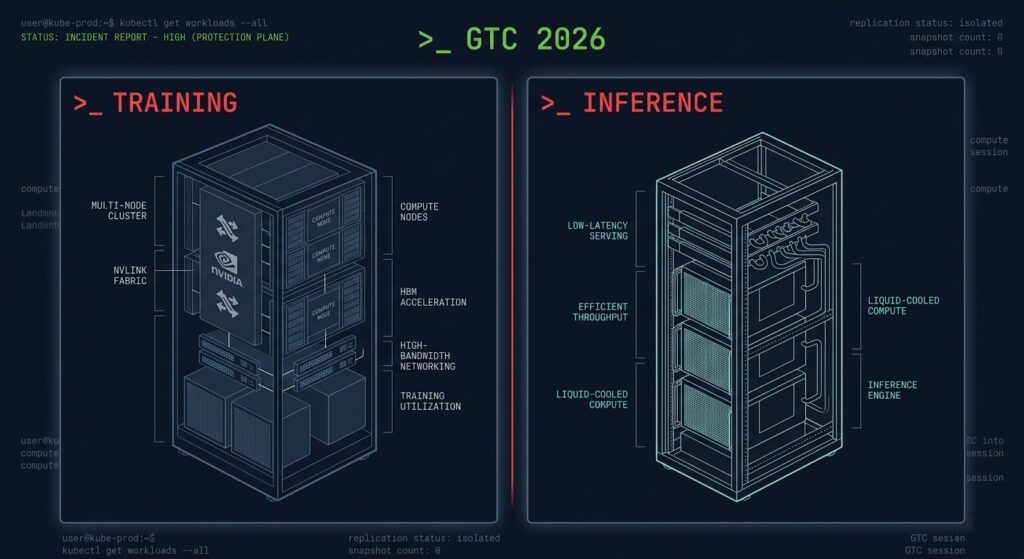
Description: Architecture diagram showing the two distinct GTC 2026 rack systems side by side. Used after the What GTC 2026 Actually Announced section to give the hardware announcement a visual anchor.
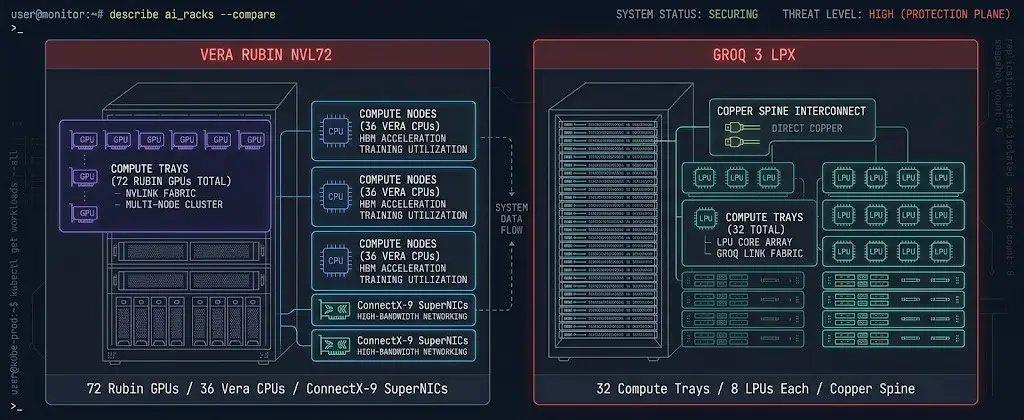
The Vera Rubin platform is NVIDIA’s successor to Blackwell. The NVL72 rack — 72 Rubin GPUs, 36 Vera CPUs, ConnectX-9 SuperNICs — delivers up to 10x inference throughput per watt and trains large models with roughly one quarter the GPU count of the previous generation. That is a meaningful hardware leap, but it is an evolution of what teams already understand.
The Groq 3 LPX is different in kind, not degree.
The LPX rack contains 32 compute trays with 8 LPUs each, connected via direct chip-to-chip spine using copper connections. Multiple LPX racks can operate as a single inference engine. The LPUs are purpose-built for low-latency token generation at lower operating costs than GPU-based inference. This category of hardware spawned an entire class of startups — Cerebras, SambaNova, Groq itself before the acquisition. The signal is that NVIDIA now considers dedicated inference silicon a permanent part of the stack, not an edge case.
The practical implication: you can now buy training infrastructure and inference infrastructure as distinct systems from a single vendor, designed to work together. The separation of concerns that architects have been modeling as an abstract decision is now a hardware procurement decision.
Why the Split Was Already Inevitable
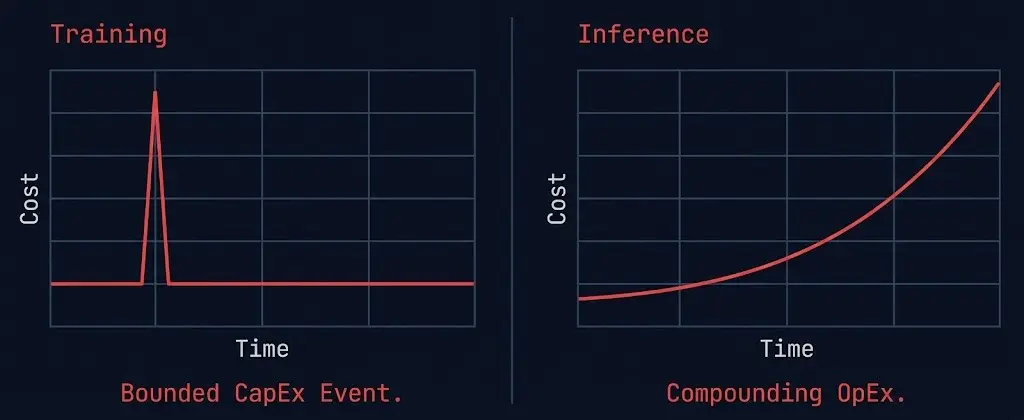
Training and inference are not versions of the same workload. They have different physics, different cost models, and different failure modes. The fact that both have historically run on GPUs was a convenience of early AI infrastructure, not an architectural design choice.
Inference crossed 55% of total AI cloud infrastructure spend in early 2026. It is now the dominant AI workload by cost, not training. Yet most enterprise teams are still running inference on the same GPU clusters they use for training — the architectural equivalent of running your production database on your development server because both technically work.
The AI inference cost architecture post mapped this from the cost side: inference spend is behavior-driven, not provisioning-driven, and every forecasting model built around training economics will fail when applied to inference operations. What GTC 2026 added is the hardware argument — the industry has now formally decided these are separate systems.
What Most Teams Will Miss
The teams that will misread GTC 2026 are the ones that treat it as a hardware upgrade announcement and go back to planning their next GPU refresh cycle.
The structural shift is that inference is no longer a secondary concern that lives on whatever GPU capacity is left over after training. It is a first-class infrastructure decision with its own hardware category, its own cost model, its own failure modes, and its own operational requirements.
The Architecture Decision GTC 2026 Forces
Every team running AI workloads in production now needs an explicit answer to three questions that didn’t require explicit answers twelve months ago.
Where does training live? Training workloads are GPU-cluster-bound, checkpoint-I/O-bound, and fabric-bandwidth-bound. The Vera Rubin NVL72 is the reference architecture for this workload. The distributed AI fabrics architecture maps the networking constraints that govern whether training scales or stalls.
Where does inference live? Inference infrastructure workloads are latency-bound, token-economics-bound, and — in agentic systems — behavior-bound. The LPX rack is the hardware argument that inference deserves dedicated silicon. The software argument for why behavior-driven inference cost requires dedicated runtime controls is in the execution budgets post. The security argument for what governs model invocation before execution reaches that silicon is in Kubernetes Is Not an LLM Security Boundary.
Inference placement also carries an orchestration dimension that dedicated silicon makes more acute. When inference can run on edge nodes, regional clusters, on-premises LPU racks, or cloud endpoints, the routing layer must account for where each request lands — not just which model handles it. Data gravity, latency constraints, and cost-per-token economics vary by placement zone in ways that a single-cluster architecture never exposed. See Inference Routing Is Becoming an Infrastructure Placement Problem for the placement architecture that dedicated inference infrastructure requires.
How do they interact? The boundary between training and inference is not a network segment — it is a data gravity problem. Models trained in one location need to serve inference requests from another. The latency and egress implications of that boundary are the architectural inputs that determine whether your AI infrastructure cost model is predictable or compounding. The full cost architecture is mapped in Part 1 of the AI Inference Cost Series.
Where Cost Control Breaks — And Why Runtime Control Becomes Necessary
This is the connection most architecture teams are not making yet.
When training and inference run on the same hardware, cost anomalies are visible at the resource level — GPU utilization spikes, cluster saturation, checkpoint I/O storms. The infrastructure signal and the cost signal are the same signal.
When inference moves to dedicated hardware with its own cost model, the signals decouple. Inference cost is now a function of token consumption, model call counts, retry rates, and context window utilization — not GPU cluster saturation. The infrastructure can look healthy while inference spend compounds silently in the background.
This is exactly the drift pattern described in Autonomous Systems Don’t Fail. They Drift. — but now with a hardware dimension. Dedicated inference infrastructure removes the natural feedback loop that GPU-sharing provided. When inference has its own rack, it also needs its own runtime controls.
Execution budgets — token ceilings, call count limits, retry caps enforced at the workflow level — are not an optional guardrail for teams running dedicated inference infrastructure. They are the architectural equivalent of a circuit breaker in a system where the cost driver is behavior, not provisioning. The full enforcement architecture is in Part 2 of the AI Inference Cost Series. Governing that enforcement stack across production — detecting when controls are absent, correlating cost signals to runtime behavior, and maintaining operational visibility across dedicated inference infrastructure — is the domain of Operations & LLMOps Architecture, the stage that covers the full LLMOps and cost observability layer for production AI systems.
What This Means for Your Infrastructure Roadmap

GTC 2026 hardware isn’t shipping until the second half of 2026. You don’t need to make a procurement decision today. What you do need to do today is update your architecture model.
Does your current AI infrastructure treat training and inference as the same workload? If yes, that assumption is now formally obsolete at the hardware level.
Does your cost model for inference depend on GPU utilization as the primary signal? If yes, you are missing the behavioral cost drivers that compound independently of utilization.
Does your team have runtime controls — execution budgets, call count limits, token ceilings — deployed at the workflow level for inference workloads? If not, you are running unbounded inference on infrastructure that the hardware industry has now formally recognized as a separate system category.
The training/inference split is not a future architectural concern. GTC 2026 made it a present hardware reality. The teams that recognize the implication now — before the procurement cycle, before the dedicated hardware ships — are the ones that will have the runtime controls in place when the cost model changes.
For the full AI infrastructure architecture framework — GPU orchestration, distributed fabrics, LLM ops, and cost architecture — the AI Infrastructure Architecture pillar maps the complete decision space. The AI Architecture Learning Path is the sequenced reading order for architects building or stress-testing this stack.
The teams that treat inference as a workload will optimize it. The teams that treat it as a system will control it.
Architect’s Verdict
For the first time, NVIDIA shipped dedicated inference hardware alongside training hardware as a first-class platform component. That is not a product announcement. It is the industry’s formal acknowledgment that inference is a separate system.
The architectural response is not a procurement plan for H2 2026. It is a design review today — of your workload model, your cost instrumentation, and your runtime controls. The hardware is catching up to what the cost data has been telling architects for the past year. Your architecture should be ahead of it.
Frequently Asked Questions
Q: What did NVIDIA announce at GTC 2026 for inference?
A: NVIDIA announced the Groq 3 LPX — a dedicated inference rack built around LPUs (Language Processing Units) rather than GPUs. This is the first time NVIDIA has shipped purpose-built inference hardware as a first-class platform component alongside its training hardware. The LPX rack is designed for low-latency token generation at lower operating costs than GPU-based inference.
Q: What is the difference between training and inference infrastructure?
A: Training infrastructure handles the bounded, capital-intensive process of building a model — large GPU clusters, checkpoint I/O, gradient synchronization. Inference infrastructure handles the continuous, behavior-driven process of running a model in production — every token, every API call, every pipeline invocation. Training cost is a bounded CapEx event. Inference cost is compounding OpEx that scales with behavior, not provisioning.
Q: Why does dedicated inference hardware change the cost model?
A: When training and inference run on shared GPU hardware, cost anomalies show up as GPU utilization spikes — the infrastructure signal and cost signal are the same. When inference runs on dedicated hardware, those signals decouple. The infrastructure can show healthy utilization while inference spend compounds independently through token consumption, retry rates, and context window usage. Dedicated inference hardware requires dedicated cost instrumentation at the workflow level.
Q: What is an execution budget for AI inference?
A: An execution budget is a runtime constraint — a limit on how many tokens an agent or workflow can consume, how many model calls it can make, and how many retries it is permitted — enforced at the moment of execution. Execution budgets are the primary mechanism for making inference cost visible and controllable when the cost driver is behavioral rather than provisioning-based.
Q: When is the Vera Rubin platform shipping?
A: NVIDIA announced the Vera Rubin platform at GTC 2026 with a second half of 2026 target for hardware availability. The Vera Rubin NVL72 rack delivers up to 10x inference throughput per watt compared to Blackwell, with training capacity requiring roughly one quarter the GPU count of the previous generation.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session