Beyond the Hyper-scaler: Why AI Inference is Moving to the Edge (and How to Architect It)
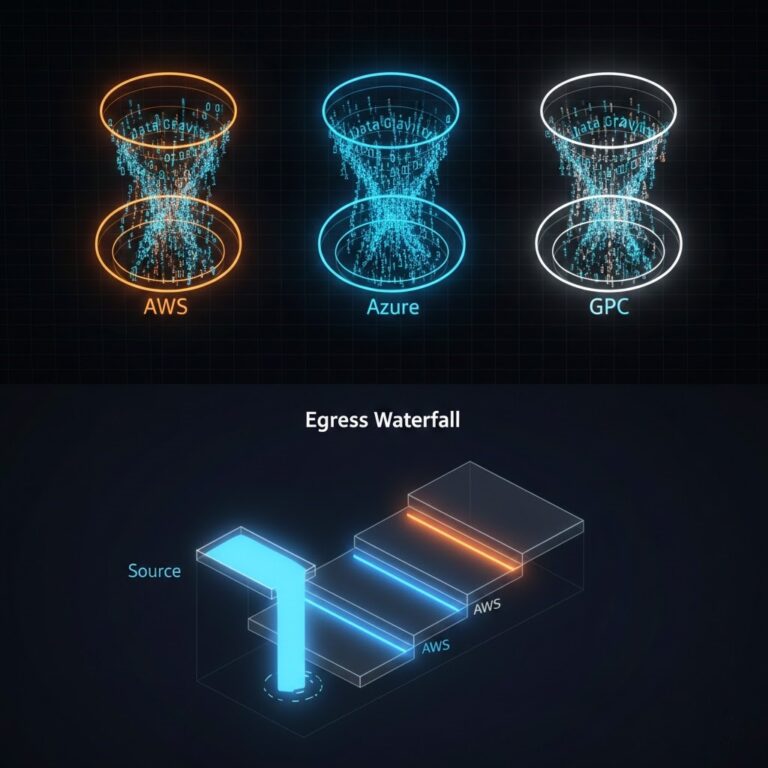
The NVIDIA-Groq deal confirms what infrastructure architects have suspected for eighteen months: centralized cloud is struggling with AI inference edge workloads. Real-time inference at scale — thousands of devices, sub-20ms latency requirements, metered connectivity — breaks the hyperscaler model. This post covers the decision framework, financial reality, and architecture pattern for moving AI inference to…