GitOps for Bare Metal: Applying SDLC to Physical Hardware

The “Spreadsheet of Doom”
You know the one. That “Master Inventory.xlsx” file everyone dumps in the Engineering Drive. MAC Address, IPMI IP, Rack Unit, Status—it’s all there.
And it is always, 100% of the time, wrong.
You go to provision a “spare” node, only to find it has a dead drive, or the wrong BIOS version, or someone quietly repurposed it for a dev cluster three months ago and never updated the sheet.
This is Physical Drift.
In the cloud, we treat infrastructure as code. We destroy and recreate VMs with a pull request. But on-prem, we still treat bare metal servers like pets. We name them, nurse them, and manually log into the BMC to mount ISOs.
That era is over.
Why This Matters Now
Bare metal is back—and not in a hobbyist way.
AI clusters, GPU farms, edge compute, and data sovereignty workloads are pushing infrastructure back into physical data centers. Hardware lifecycles are shrinking. Firmware vulnerabilities are increasing. And human-operated metal does not scale.
If your hardware lifecycle still depends on:
- Tribal knowledge,
- Spreadsheets,
- And a crash cart…
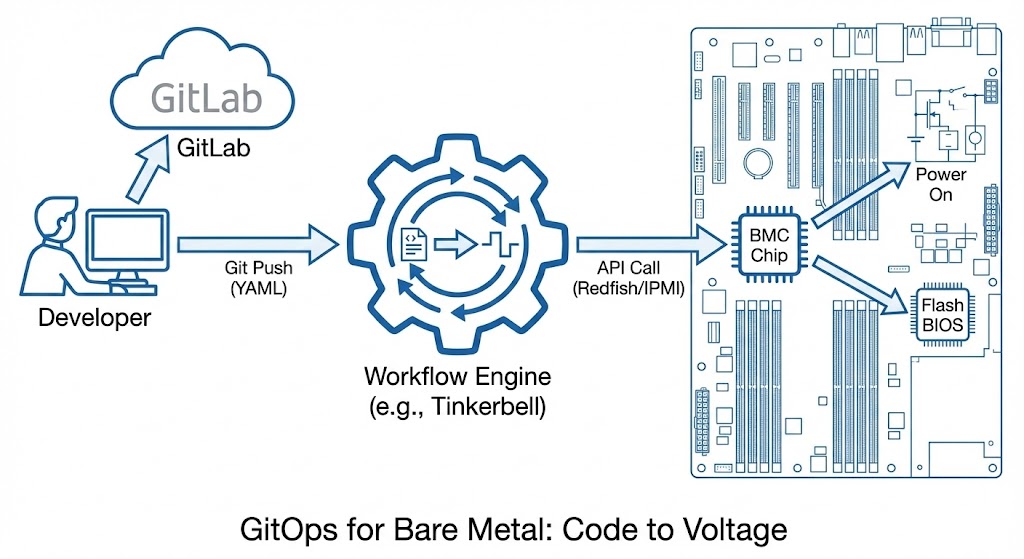
To make this work, we need a bridge between the API world (Git) and the physical world (IPMI/Redfish).
What GitOps for Bare Metal Is Not
Let’s be clear about what this architecture is—and isn’t.
It is not:
- A prettier UI for IPMI.
- A CMDB with YAML syntax.
- A magic fix for bad hardware.
The Mechanics: Bridging the Air Gap
“GitOps for bare metal” sounds like a buzzword until you realize it is just a reconciliation loop. In Kubernetes, an operator watches a Git repo and makes the cluster match the manifest. In Bare Metal, the “Cluster” is the data center, and the “Manifest” is the hardware state.
The “Machine” as a CRD
We stop thinking of a server as “that Dell R760 in Rack 12.” We think of it as a Machine object in YAML.
YAML
apiVersion: tinkerbell.org/v1alpha1
kind: Hardware
metadata:
name: worker-node-04
spec:
metadata:
facility: "us-east-dc1"
network:
interfaces:
- dhcp:
mac: "00:25:90:fd:8b:22"
ip: "10.10.30.24"
bmc:
ip: "10.10.10.24"
username: "admin"
password: "ipmi-password-secret"
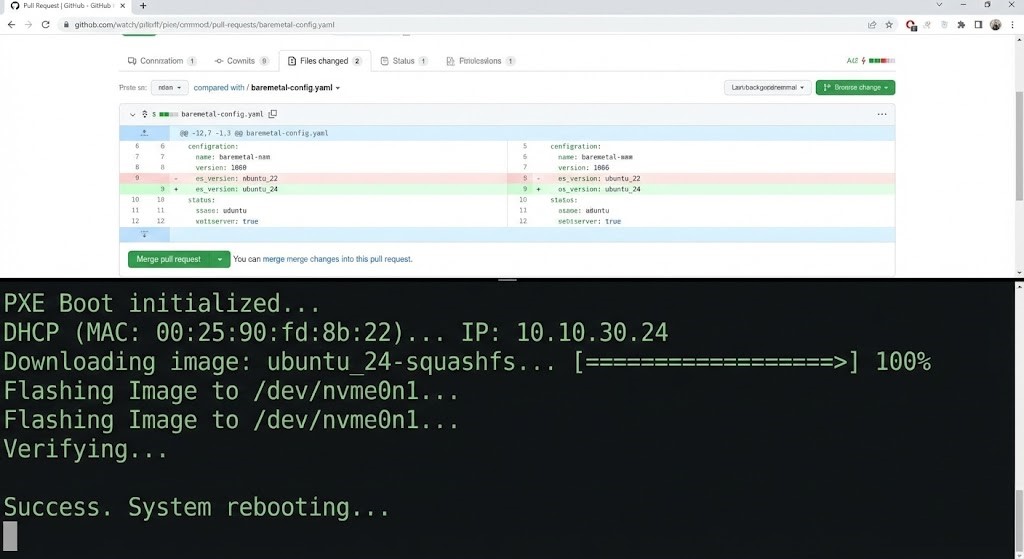
When you push this YAML to Git:
- The Workflow Engine (like Tinkerbell or Canonical MAAS) sees the new commit.
- The Provisioner talks to the BMC via Redfish/IPMI.
- The Action powers on the server, sets the boot order to PXE, and streams the OS image directly to RAM.
There is no spreadsheet. The “Inventory” is the Git Repo. If a server dies, you delete the YAML, and the provisioner wipes the hardware.
The Solution: A Declarative Data Center
So, what is this actually?
It is:
- A reconciliation system between desired state and physical reality.
- A way to apply SDLC principles to hardware lifecycle.
- A foundation for operating physical infrastructure like cloud.
To build this, you need a stack that speaks both Git and IPMI.
1. The Source of Truth (Git)
Your entire fleet state lives here.
hardware/: Defines MACs, BMC IPs, and physical location.profiles/: Defines what the server is (e.g., “GPU Worker”, “Storage Node”).templates/: Defines the boot workflow (wipe disks -> flash BIOS -> install OS).
2. The Workflow Engine (Tinkerbell / Smee)
This is the “Kubernetes for Metal.” It runs a DHCP server, a TFTP server, and a workflow controller. When a server boots, it doesn’t just get an IP. It gets a Job.
- Job 1: Erase partition table.
- Job 2: Flash Firmware v2.4.
- Job 3: Stream CoreOS image to
/dev/nvme0n1.
3. The Reconciliation Loop
This is where the magic happens. If you change the OS_VERSION in Git from v1.2 to v1.3:
- The engine detects the drift.
- It marks the node as “Out of Compliance.”
- Depending on your policy, it effectively reboots and re-images the node automatically.
What Breaks Without This
If you ignore declarative hardware, you are building on sand. Without this:
- Zombie servers run outdated firmware for years.
- Shadow clusters never get patched.
- Disaster recovery depends on one engineer’s memory.
- Security controls stop at the hypervisor.
- Compliance audits turn into scavenger hunts.
You don’t have an infrastructure problem. You have a state management problem.
The Architect’s Verdict
We need to stop fearing the hardware. The reason on-prem operations fail is that we rely on human memory to manage physical state.
- Treat MAC Addresses like UUIDs. They are just unique identifiers for a compute resource.
- Kill the Snowflake Servers. If a server requires a “special BIOS tweak” that isn’t in the code, it is technical debt. Wipe it.
- The BMC is the API. Stop walking to the rack with a crash cart. If you can’t fix it via IPMI, it’s a hardware RMA, not a sysadmin problem.
If you are building your Modern Infrastructure Pillar, this is the foundation. You cannot run a cloud on top of manual hardware.
If you’re serious about Infrastructure as Code, GitOps can’t stop at the hypervisor. The metal is next. If you are ready to automate it, start the Modern Infra & IaC Learning Path.
Additional Resources
- Tinkerbell Docs: Architecture & Components – The CNCF project for bare metal provisioning.
- Open Compute Project: Open System Firmware (OSF) – Moving BIOS/Firmware to open standards.
- GitOps Principles: OpenGitOps.dev – The official CNCF manifesto for declarative continuous delive
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session