The Model Answered. Nobody Asked Who Authorized That.

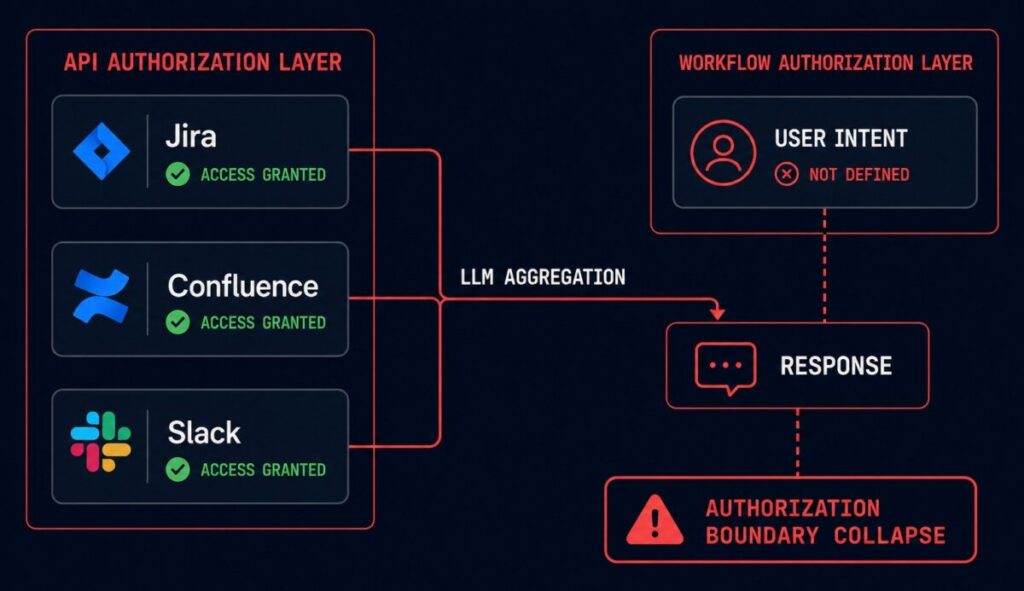
The ticket came in on a Tuesday. The AI assistant connected to Jira, Confluence, and Slack — the standard enterprise productivity stack. A product manager asked it for “incident history on the payment service.” The model returned a thorough summary: timeline, root cause, contributing factors, and a section pulled from a postmortem written by a different business unit that had never been shared with the product team.
Every API call succeeded. Every permission check passed. The model had access to Confluence. The postmortem was in Confluence. The user had a valid session. Nobody had defined what “incident history for this user in this workflow context” was actually supposed to mean.
Nobody noticed until the summary was pasted into an executive slide deck and someone in the room recognized content they hadn’t intended to share.
This is the llm authorization problem — and it isn’t solved by tightening API permissions.
The Failure Was Correct Behavior
The model didn’t malfunction. It did exactly what it was designed to do: aggregate relevant information across connected systems and synthesize a useful response. The Jira integration returned relevant tickets. The Confluence integration returned relevant documents. The Slack integration returned relevant thread context. The model assembled them into a coherent answer.
The failure was that nobody had defined the authorization boundary for the workflow — only for the individual API calls within it.
This distinction matters architecturally. In traditional enterprise systems, when a user requests data, the request is scoped at the API level: this user can read these records, these documents, these messages. The system enforces that scope at every call. The scope boundary is explicit, enforced, and auditable.
In an AI workflow connected to multiple enterprise systems, the scope question shifts. The user has permissions. The model has connections. But the model doesn’t ask “what was this user intended to retrieve?” — it asks “what is relevant to answering this question?” Those two questions return different result sets, and the gap between them is where authorization boundary collapse lives.
APIs Validate Identity. LLMs Aggregate Context.
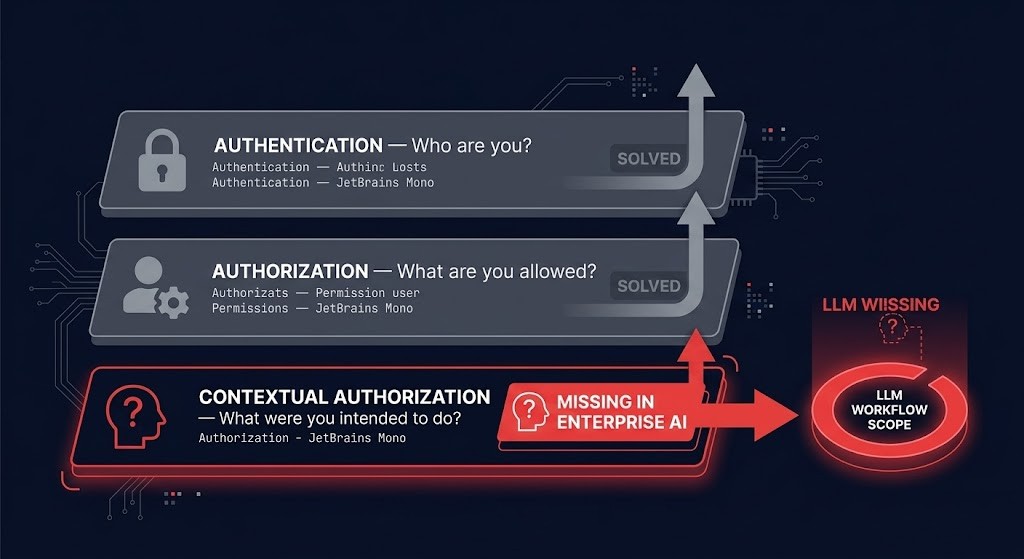
Traditional enterprise authorization operates on a three-layer model that most architects understand implicitly:
Authentication — who are you? Validate identity, confirm session, check credentials.
Authorization — what are you allowed to do? RBAC, ACLs, policy enforcement. This is where most enterprise security investment lives.
Contextual authorization — what were you intended to do in this specific workflow? This layer doesn’t exist in most enterprise auth architectures because traditional systems didn’t need it. A database query returns exactly what you asked for. A REST endpoint returns a defined resource. The scope of the response is determined by the request.
LLMs break the third layer open. A model connected to ten enterprise systems doesn’t retrieve one resource — it aggregates context across all systems it has access to, ranked by relevance to the prompt. The user’s intent (“tell me about incident history”) becomes the model’s retrieval scope, and that scope is bounded only by what the model can access, not by what the user was supposed to see.
The result: an AI workflow can satisfy every individual authorization check at the API layer while returning a response that violates the organizational intent behind those policies. Every call was authorized. The aggregation was not.
Authorization Boundary Collapse
This failure pattern has a name: Authorization Boundary Collapse — the moment an AI workflow inherits access scopes broader than the user intent it is acting on.
It’s distinct from a permissions failure. The permissions were correct. The boundary between “what this user is allowed to access” and “what this user was intended to access in this context” simply wasn’t defined — because enterprise authentication infrastructure was built for intentional, scoped requests, not for AI systems that aggregate laterally across everything they can reach.
Authorization Boundary Collapse shows up in predictable patterns in enterprise AI deployments:
An enterprise copilot connected to HR, finance, and engineering systems returns salary information when asked about headcount planning — because the model’s connections include the HR system and “headcount planning” is semantically adjacent to compensation data.
A support AI with Slack and ticketing access surfaces internal escalation discussion when summarizing a customer issue — because the internal thread about that customer is in scope for the model’s Slack integration.
A developer assistant with repository and documentation access returns security architecture details when asked about a service’s error handling — because the threat model document lives in the same Confluence space as the engineering runbooks.
None of these are bugs. None of them would have been caught by an access review. Every individual permission was valid. The workflow authorization was never defined.
The workflow authorization problem has a prior gap: the agent executing the workflow was often never inventoried as an agent in the first place. When a Copilot Studio workflow with Confluence, Jira, and Slack access gets classified as automation, it never reaches the infrastructure team’s awareness — which means nobody defines its workflow authorization scope before it’s in production. The classification failure that creates this condition is documented in The AI Agent Inventory Gap Nobody Is Measuring.
The CLI control plane post makes the parallel argument for automated pipelines: when you hand execution authority to a system that can operate across your entire stack, the authorization model for human operators no longer covers the surface area. AI workflows operating across enterprise systems are the same problem at the retrieval layer.
The Hidden Assumption in Enterprise Auth
The architecture assumed every request was intentional. This assumption is embedded in how enterprise auth is designed and enforced, and it held up well for decades because traditional systems don’t generate lateral context — they respond to explicit requests.
A user queries a database: the query defines the scope. A user calls an API: the endpoint defines the resource. The request and the response have a direct, bounded relationship that authorization policy can govern.
An AI assistant processing “give me context on this customer issue” doesn’t have a bounded request. It has a semantic goal that it will satisfy by traversing every connected system it has access to. The model doesn’t know that the Slack integration wasn’t supposed to surface the internal escalation thread. It knows that the thread is relevant. Relevance and authorization are different properties — and most enterprise auth infrastructure only enforces one of them.
This is what makes Authorization Boundary Collapse structurally different from a misconfigured permission: it’s not a configuration error. It’s a missing layer in the authorization model. The AI FinOps governance gap is structurally similar — cost authority moved to a layer the governance model wasn’t designed to cover. LLM authorization is the same pattern at the access control layer: retrieval authority moved to a layer that enterprise auth was never designed to govern. The same displacement happens at the infrastructure layer below the access control surface — inference routing, agent orchestration, and observability pipelines deploy as ungoverned infrastructure with no authority model, creating the Runtime Authority Vacuum that makes authorization boundary enforcement structurally incomplete regardless of how tightly the access control layer is configured.
Architect’s Verdict
If the model can aggregate across systems, authorization must exist at the workflow layer — not only at the API layer.
This means defining, for each AI workflow: what data sources are in scope, what retrieval intent is authorized, and what response content is acceptable for this user in this context. That definition needs to exist as an explicit policy, enforced before the model aggregates — not inferred from the permissions of the connected systems.
The enterprise AI deployments that get this right are treating workflow authorization as a first-class architectural decision, the same way they treat identity management and RBAC. The ones that get it wrong are discovering Authorization Boundary Collapse in post-meeting debrief sessions when someone in the room asks where that data came from.
For agentic deployments — AI systems that don’t just retrieve but take action — the surface area expands from retrieval to execution. The protocol layer where that expansion happens in most enterprise environments is MCP: the authority boundary failures that MCP tool use introduces are the execution-layer equivalent of the retrieval-layer collapse this post describes. Governing either layer requires more than observability — it requires evidence that authorization occurred: who permitted what, under which policy, at execution time. The architectural distinction between observability and evidence is examined in AI Systems Need Evidence, Not Just Observability. Autonomous systems that drift without runtime governance are the next stage of the same problem. Authorization Boundary Collapse in a retrieval workflow is embarrassing. In an agentic workflow with write access, it’s an incident.
The governance architecture that defines execution authority, enforces policy at the runtime layer, and prevents the Runtime Authority Vacuum that makes authorization boundary enforcement structurally incomplete is the subject of Governance & Runtime Control (A6) in the AI Infrastructure Architecture Path.
The model answered. The architecture assumed that was the same as the model being authorized.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session