MIGRATION ARCHITECTURE PATH
MOVING STATE IS EASY. TRANSLATING PERFORMANCE IS THE CHALLENGE.
Why Migration Architecture Matters: The Lift-and-Shift Fallacy
For a long time, infrastructure teams saw hypervisor migration as a simple checklist: export the VMDK, move the state, import the VM, and power it up. If it boots, the job is done.
Modern infrastructure does not work that way.
Migration is not file transfer. It is architectural translation. When you move from a legacy monolithic stack like VMware vSphere (ESXi + vCenter) to a distributed HCI-based platform like Nutanix AHV (Acropolis Hypervisor + Prism) or KVM, you are not just moving disks – you are translating execution physics:
- CPU scheduling behavior
- NUMA exposure and memory locality
- Storage latency models
- Failure domain boundaries
- Cluster policy enforcement
A workload that behaved predictably on ESXi attached to a traditional SAN will not behave identically on AHV backed by distributed storage. CPU Ready becomes CPU Wait. Storage latency becomes replication amplification. Memory locality shifts under new NUMA mappings.
The workload itself hasn’t changed. The physics underneath it have.
Most migration failures are not catastrophic. They surface weeks later — during a rebuild storm, under East-West congestion, or when controller VMs compete for CPU cycles.
Migration is not about moving state. It is about preserving deterministic performance across execution models.
No vendor hype. No “one-click migration” fantasies. Just the real work of translating performance.
Who Should Read This
This path is for engineers responsible for moving workloads across hypervisor boundaries — and who care about keeping performance predictable.
- Virtualization Engineers: Planning migrations from vSphere to AHV, KVM, or other HCI-native platforms. You must understand how DRS, affinity rules, and resource pools translate — and where they break.
- Infrastructure & Platform Architects: Designing for N+1 headroom under migration load and failure-state stress.
- Infrastructure & Platform Architects: Designing for N+1 headroom under migration load and failure-state stress.
- Cloud & Sovereign Architects: Transitioning from legacy private infrastructure to HCI or hybrid models while preserving compliance and latency guarantees.
- Consulting & Migration Teams: Executing phased transitions that require deterministic validation before cutover.
If you are looking for tooling shortcuts, this is not that guide. If you are engineering for predictability under load, this is.
Phase 0: Control Plane Alignment (Before You Move Anything)
Before touching a workload, architects must align the execution environment. Migration without control plane translation creates “shadow drift”—where workloads technically function, but governance silently collapses.
Architects must map and validate:
- Identity & RBAC: Translating vCenter roles to Prism/KVM roles.
- Network Segmentation: Mapping legacy vDS (Virtual Distributed Switches) to modern overlay networks or SDN controllers.
- Backup and DR Hooks: Ensuring snapshot APIs are active before the first boot.
- Monitoring & Observability: Re-pointing telemetry pipelines.
A workload without governance alignment is not migrated — it is orphaned.
Deep Dive: Before you can translate the control plane, you have to untangle the legacy footprint. Read our analysis on:
- The Legacy Footprint: Before translating the control plane, you have to untangle the original footprint. Read The vCenter Control Plane: Optimization, Sizing, and the “Hidden” Java Tax.
- Closing the Console Gap: To understand how identity and authority shift between these hypervisor ecosystems, review Nutanix vs VMware: Availability vs Authority in the Post-Broadcom Datacenter (2026).
- Identity as a Failure Domain: Mapping RBAC across platforms requires treating credential paths as critical fault zones. See our guide on Logic-Gapping Your Data: Engineering “Air Gaps” in a Zero-Trust World.
- Control Plane Survivability: If migrating into a highly secure or isolated environment, you must validate that the destination architecture can operate without external dependencies. Read our engineering breakdown on The Physics of Disconnected Cloud Operations.
Phase 1: Policy Translation (The Brains)
Clusters enforce behavior through policy, not just hardware. A direct 1:1 rule copy between hypervisors is rarely deterministic.
When migrating from vSphere to AHV, the logical boundaries must be re-engineered:
- DRS Rules must become Placement Policies.
- Resource Pools must be re-modeled for the new scheduler.
- Anti-affinity rules must be validated against the new physical node density.
- Protection Policies: Legacy SRM runbooks must be translated into native HCI protection domains.
You are not migrating VMs. You are migrating scheduling logic.
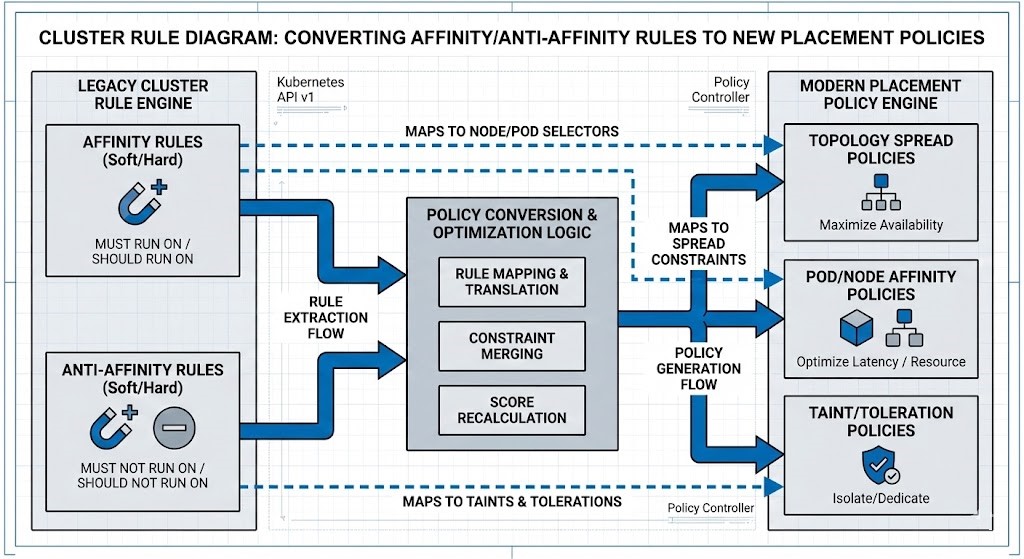
Deep Dive: You cannot migrate a workload’s performance without first translating the cluster’s execution logic. Read our analysis on mapping legacy rules to modern HCI behaviors:
- Rule Translation: For a step-by-step mapping of how legacy clustering logic translates to modern HCI, read our vSphere to AHV Migration Strategy: A Risk-Deterministic Framework for Legacy Workloads.
- Resource Contention: Understand exactly how CPU scheduling changes across hypervisors in CPU Ready vs. CPU Wait: Why Your Cluster Looks Fine but Feels Slow and our engineering breakdown of Resource Pooling Physics.
- Disaster Recovery Translation: Do not just migrate workloads; migrate their survivability. See how to translate replication policies in Nutanix Async & NearSync vs VMware SRM: The Blueprint for Modern DR.
Phase 2: State & Memory Physics (The Move)
Live migration is fundamentally a memory replication event.
Moving terabytes of RAM across a network introduces tail latency amplification. If the underlying fabric is not engineered for this, the migration will fail — or worse, succeed with degraded performance.
Key physical considerations:
- CPU Masking & EVC Baselines: Ensuring instruction set parity across the wire.
- Memory Pre-Copy Convergence: Calculating the delta of active memory changes versus the network bandwidth.
- Stun Time Thresholds: The exact millisecond gap where the VM is paused to cut over.
- NUMA Re-binding Effects: How memory access changes when the VM wakes up on the destination node.
Live migration is a race between memory churn and network determinism.
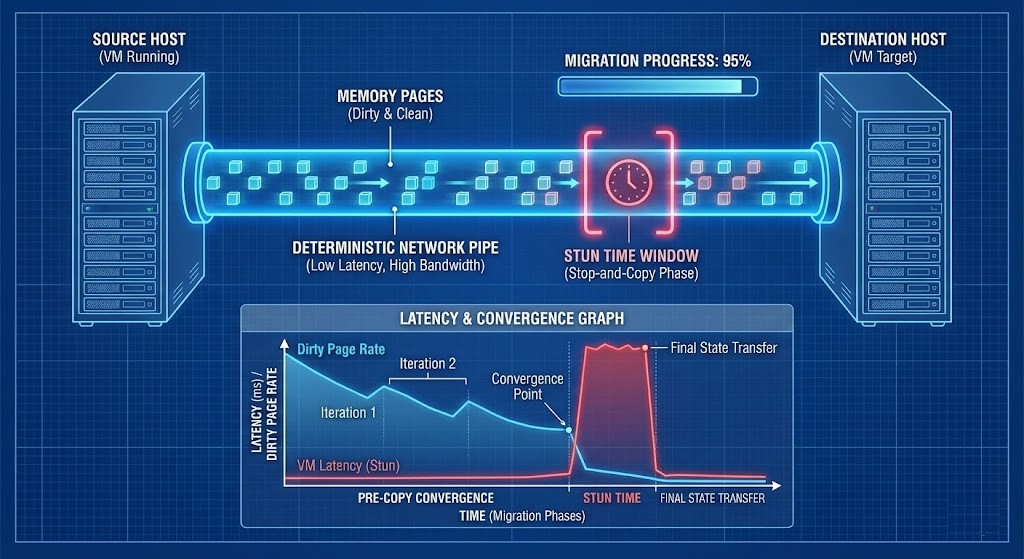
Deep Dive: You cannot move terabytes of active memory without a highly predictable transport layer. Read our analysis on engineering the network for migration events:
- Metro Latency Modeling: If you are migrating workloads across physical sites, validate your synchronous thresholds using tools like the Nutanix Metro Latency Scout.
- Network Determinism: Understand why raw bandwidth cannot prevent tail-latency spikes and dropped packets during live migrations in Deterministic Networking: The Missing Layer in AI-Ready Infrastructure.
Phase 3: Sizing the Destination (The Landing)
A 4vCPU VM on ESXi attached to a traditional SAN does not behave exactly like a 4vCPU VM on AHV utilizing local HCI storage.
HCI introduces specific physics that must be calculated into the destination cluster’s headroom modeling:
- Controller VM Overhead (The CVM Tax): Dedicated resources required to run the distributed storage fabric.
- Local Storage Amplification: How RF2/RF3 write behavior impacts available node performance.
- Rebuild Traffic Sensitivity: The performance impact of a drive failure on the migrated workload.
- Memory Ballooning Differences: How different hypervisors handle memory overcommitment.
Identical specifications do not guarantee identical contention physics.
Deep Dive: You cannot land a migrated workload safely without calculating the physical overhead of the new environment. Read our analysis on HCI capacity math:
- Convergence Physics: Learn how storage, compute, and replication traffic fight for the same physical boundaries in our foundational guide on HCI Architecture: The Physics of Convergence.
- Memory Overcommitment: See exactly how hypervisors handle resource starvation differently in our engineering breakdown of Resource Pooling Physics.
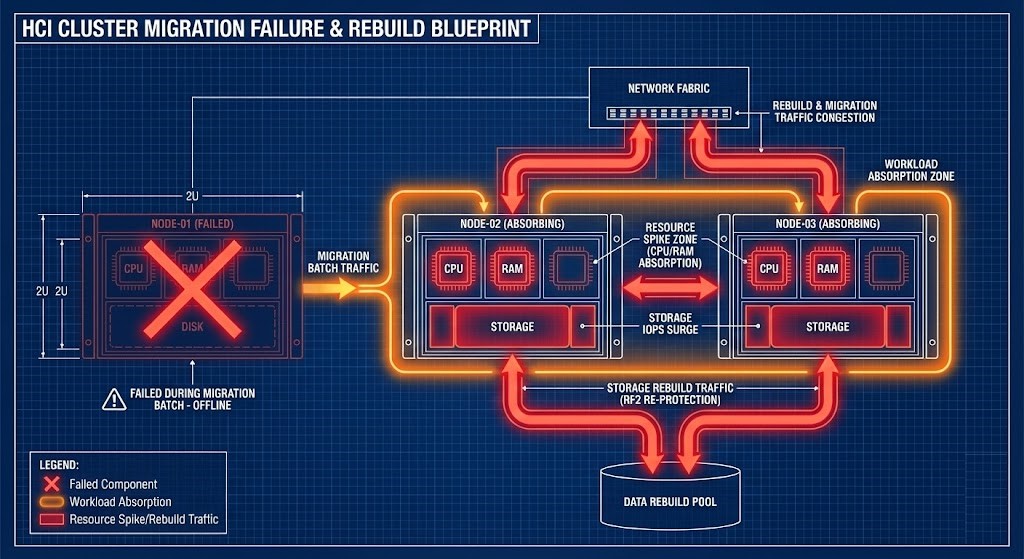
Phase 4: Validating Under Duress (The Proof)
Architects must validate the migration sequence under duress. If your migration plan only works in steady-state, it is not deterministic.
Can your live migration window survive:
- An N+1 degraded cluster state?
- Active storage rebuild traffic crossing the same spine links?
- A Top-of-Rack (ToR) or Spine switch failure scenario?
- Cross-site replication lag during the cutover?
Failure is not an edge case. It is the validation environment.
The Transition Risk Matrix
To model a successful migration, architects must map the translation of execution logic against specific validation metrics.
| Migration Dimension | Hidden Risk | Validation Metric |
| Scheduler Logic | CPU ready spike | %RDY before/after |
| Storage Path | Write amplification | P99 write latency |
| NUMA Topology | Cross-node memory | Remote memory % |
| Network Fabric | Microburst stun | Live migration pause time |
| Failure Behavior | Rebuild overlap | I/O during node loss |
Success is measured in physics — not boot state.
Economic Modeling & Exit Physics
Migration carries hidden costs that architects must account for in the project scope. Deterministic migration requires cost predictability, not just technical predictability.
- Double-Run Infrastructure Window: The cost of keeping both the legacy and destination clusters powered and cooled.
- Licensing Overlap: Simultaneous hypervisor taxation.
- Egress Bandwidth Bursts: If moving between physical sites or cloud boundaries.
- Automation Refactoring: Rebuilding Terraform/Ansible state for the new API.
Predictable migration requires cost modeling — not just technical modeling.
Deep Dive: For a full breakdown of cloud boundary costs during migrations, read The Physics of Data Egress and our analysis of the Shim Tax: Hidden Hybrid Costs.
Continue the Virtualization Architecture Path
HCI and Hypervisor migration is not an isolated design choice. It intersects directly with:
- Modern Virtualization Learning Path
- Storage Architecture Learning Path
- Networking Architecture Learning Path
- Modern Compute Learning Path
- Performance Modeling Learning Path
- Data Protection & Resiliency Learning Path
Architect FAQ
Q: Is migration just copying virtual disks?
A: No. Migration translates scheduling logic, NUMA alignment, storage write paths, and failure-domain behavior — not just data.
Q: Why can identical VM specs perform differently after migration?
A: Because hypervisor schedulers and storage architectures differ. vCPU count stays the same; contention physics does not.
Q: What is the biggest risk during live migration?
A: Memory stun time during final state sync — especially if the network lacks deterministic bandwidth under load.
Q: Do DRS and placement rules map 1:1 between platforms?
A: No. Affinity, anti-affinity, and resource scoring models behave differently and must be re-engineered, not copied.
Q: Should migrations be sized for steady-state or failure-state?
A: Failure-state. Rebuild traffic and migration bursts can push clusters beyond safe thresholds.
Q: Is migration primarily a compute problem?
A: No. It is a storage convergence event that exposes network and replication limits.
Q: What validates a successful migration?
A: Not “VM powered on.” Validate P99 latency, CPU contention metrics, storage amplification, and failure behavior.
Canonical Engineering References
- VMware: Host Configuration for vSphere vMotion
- Nutanix: Migrating VMs to Nutanix AHV (Nutanix Move)
- Red Hat: KVM Live Migration Architecture
DETERMINISTIC MIGRATION MODELING
Migration is not a lift-and-shift event. Stop guessing at your destination cluster headroom, cross-node NUMA penalties, and live migration stun times. Run your translation parameters through our deterministic calculators before you move the state.
LAUNCH THE ENGINEERING WORKBENCH