VIRTUALIZATION CONTROL PLANE ARCHITECTURE
Cluster coordination, scheduling authority, lifecycle governance, and the operational gravity of centralized orchestration.

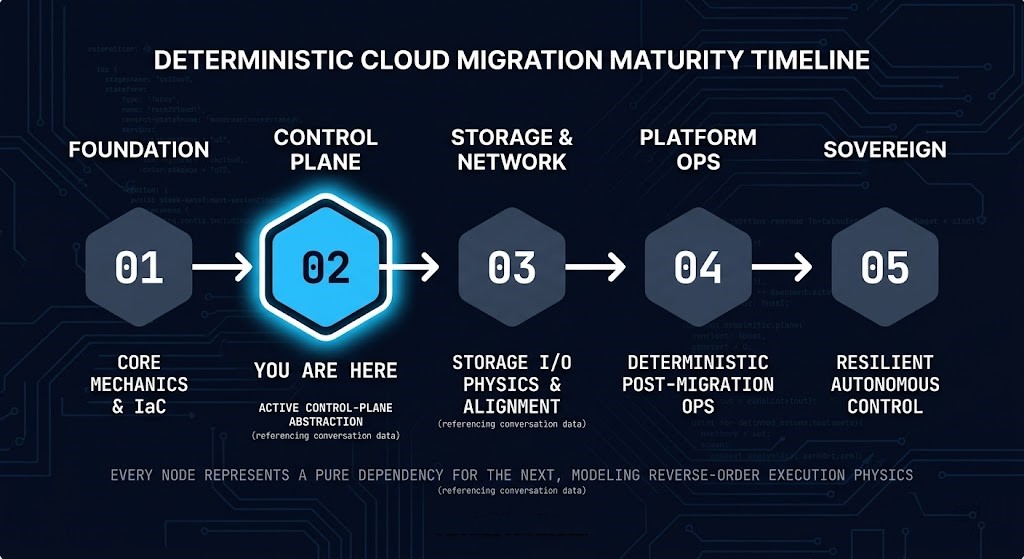
MATURITY STAGE POSITION
- Current Stage: Operational — Maturity Stage 02 of 05
- Primary Architectural Concern: How orchestration authority changes scheduling behavior, operational coordination, and infrastructure failure boundaries across the cluster
- Primary Failure Mode: Centralized orchestration amplifies coordination mistakes into cluster-wide operational instability
- Stage Outcome: Architects completing this stage can evaluate virtualization platforms by control plane authority model, sequence lifecycle operations without creating outage domains, and recognize how centralized orchestration concentrates operational gravity
- Next Stage: Operational — Storage & Network Integration
A virtualization platform is not the hypervisor. It is the control plane coordinating many hypervisors simultaneously. That distinction is the architectural transition that defines this stage — and it changes everything about how operational risk, scheduling decisions, and lifecycle management must be understood.
Stage 1 established the mechanics: abstraction layers, scheduling physics, NUMA topology, isolation boundaries, and failure domain vocabulary. Those concepts describe what a single hypervisor host does. Stage 2 is what happens when orchestration centralizes authority across many hosts at once. Five operational realities emerge from that centralization: cluster coordination, where hosts stop operating independently; scheduling authority, where placement becomes a centralized decision with cluster-wide consequences; state management, where drift and entropy become structural outputs; lifecycle operations, where updates become distributed-risk events affecting entire maintenance domains; and failure amplification, where the control plane magnifies mistakes rather than containing them. Centralization doesn’t just simplify operations — it concentrates risk, amplifies scheduling decisions, and creates operational gravity that every downstream architectural layer inherits. That gravity is what this stage is about — how to recognize it, design around it, and avoid amplifying it.
>_ THE HYPERVISOR IS NO LONGER THE PLATFORM
Modern virtualization architecture is no longer defined by the individual hypervisor host. It is defined by the orchestration layer coordinating scheduling, lifecycle operations, state management, and workload placement across many hosts simultaneously. The operational risks that matter most now emerge from the control plane itself — not the hardware underneath it.
WHAT THIS STAGE IS NOT
01 — NOT A VCENTER OPERATIONS GUIDE
This is control plane architecture — the organizational model of orchestration authority — not platform administration or day-to-day vSphere management.
02 — NOT A VENDOR FEATURE COMPARISON
Platforms are evaluated by orchestration authority model and operational coordination philosophy — not SKU lists, performance benchmarks, or licensing tables.
03 — NOT A CERTIFICATION TRACK
The focus is failure amplification, operational gravity, and lifecycle risk — not exam objectives, feature recall, or configuration procedures.
04 — NOT A BEGINNER INTRODUCTION TO CLUSTERING
Stage 1 covers hypervisor mechanics. This stage begins where execution mechanics give way to orchestration authority — readers arriving without Stage 1 context will find the framing unfamiliar.
>_ READING DEPTH
OPERATIONAL STAGE — VIRTUALIZATION CONTROL PLANE ARCHITECTURE READING SCOPE
| Article | Architectural Focus | Est. Read | Pillar |
|---|---|---|---|
| The Control Plane Problem in VMware Alternatives | Control plane emergence — what breaks when orchestration authority moves | 9 min | Virtualization |
| The vCenter Control Plane: Optimization, Sizing & the Java Tax | Centralized scheduling authority — vCenter as the architectural actor | 11 min | Virtualization |
| CPU Ready vs. CPU Wait: Why Your Cluster Looks Fine but Feels Slow | Scheduler-driven contention — reading orchestration signals, not host metrics | 10 min | Virtualization |
| Resource Pooling Physics: CPU Wait and Memory Ballooning | Workload density under centralized scheduling — where operational gravity concentrates | 12 min | Virtualization |
| Upgrade Physics: Rolling Maintenance Without Stopping Production | Lifecycle coordination — blast radius design and maintenance domain sequencing | 10 min | Virtualization |
| Proxmox vs Nutanix vs VMware: Post-Broadcom Constraints | Platform authority models — orchestration philosophy under external constraint | 14 min | Virtualization |
| Beyond the VMDK: Translating Execution Physics from ESXi to AHV | Authority model transition — what changes when the control plane model changes | 11 min | Virtualization |
| Configuration Drift: Enforcing Infrastructure Immutability | State drift as structural output — drift as consequence of orchestration at scale | 9 min | Modern Infra & IaC |
>_ WHERE TO ENTER THIS STAGE
Start here if you completed the Foundation stage and are ready to move from execution mechanics to orchestration authority — the core concern of virtualization control plane architecture — if your understanding of cluster operations is primarily procedural (how to configure DRS, HA, and vCenter) rather than architectural (what those systems decide and what those decisions cost across the cluster).
You can likely skip ahead to Card 3 if:
- You already reason about HA and DRS as control plane functions — not just features to configure
- You understand how centralized scheduling authority changes workload placement risk — not just what the utilization metrics show
- You can explain why lifecycle operations must be treated as cluster-state changes, not isolated maintenance events
If those three statements describe you, Card 3 (Lifecycle Coordination) is the correct entry point. If any of them require translation, start at Card 1 — The Emergence of the Control Plane.
>_ ARCHITECTURE MATURITY POSITION
| Stage | Level | Focus | Slug |
|---|---|---|---|
| 01 — Virtualization Foundations | Foundation | Abstraction mechanics, scheduling physics, failure-domain vocabulary, control plane inheritance | /virtualization-foundations/ |
| 02 — Control Plane Architecture ← YOU ARE HERE | Operational | Cluster coordination, scheduling authority, lifecycle governance, platform authority models | /virtualization-control-plane-architecture/ |
| 03 — Storage & Network Integration | Operational | Storage fabric, network virtualization, I/O path architecture | /virtualization-storage-and-network-architecture/ |
| 04 — Deterministic Platform Operations | Strategic | Day-2 governance, cost architecture, operational determinism | /virtualization-day-2-governance/ |
| 05 — Post-VMware Strategic Architecture | Sovereign | Platform independence, migration authority, exit strategy | /virtualization-sovereign-architecture/ |
>_ READING SEQUENCE
The six cards below are dependency-ordered. Each card builds the conceptual foundation the next one requires. Card 6 is the bridge — it closes the Operational stage by making explicit why the orchestration authority established here propagates into every control plane layer above it.
The Emergence of the Control Plane
Standalone hypervisor hosts stop scaling operationally the moment workload placement, cluster state, and inventory authority become centralized concerns. This card establishes why the shift from host-level to cluster-level thinking is architectural — not just operational — and why the control plane is the unit of analysis from this point forward.
Scheduling Authority & Placement Logic
DRS and workload mobility appear to simplify placement. They do not — they centralize it, which changes the failure profile entirely. Workload mobility is not free abstraction: every migration carries cache locality, NUMA alignment, storage path, and network topology consequences (a cost that compounds significantly in GPU and latency-sensitive workload placement). The scheduler is an architectural actor with cluster-wide authority. Misread its behavior as convenience rather than governance and contention amplifies rather than resolves.
Lifecycle Coordination & Operational Blast Radius
Maintenance operations in a coordinated cluster are not isolated events. A patch sequence that ignores upgrade domain dependencies, vSAN node availability constraints, or workload migration timing turns a maintenance window into an outage domain. Lifecycle operations must be treated as cluster-state changes — the blast radius of a poorly sequenced update is defined by the orchestration topology, not the size of the individual host.
CONTROL PLANE ARCHITECTURE FAILURE PATTERNS
— Operational Coordination Failures —
— Structural Control Plane Failures —
Platform Models & Control Plane Authority
Virtualization platforms are differentiated less by hypervisor capability than by how they centralize, distribute, and govern orchestration authority across the cluster. The authority model shapes scheduler behavior, drift exposure, lifecycle risk, and failure amplification patterns — all of which must be understood before the platform choice is made, not after migration has started.
| Platform | Authority Model |
|---|---|
| VMware | Centralized orchestration authority — vCenter as the single, explicit control plane |
| AHV | Distributed CVM-mediated authority — control plane embedded per node, coordinated across the cluster |
| Proxmox | Federated cluster authority — quorum-based distributed coordination without a dedicated management VM |
| Hyper-V | Windows-integrated orchestration authority — SCVMM or cluster-native coordination through the Windows fabric |
Distributed orchestration reduces single-point authority concentration, but introduces quorum coordination, state convergence, and operational consistency challenges of its own. The question is not which model is safer — it is which failure profile your operational maturity can govern.
State Drift & Operational Integrity
Drift is not an operational failure — it is a structural output of orchestration at scale. Different authority models create different drift vectors: centralized platforms produce drift when changes bypass the control plane; distributed platforms produce drift when quorum and state convergence assumptions break down. In both cases, configuration inconsistency and policy sprawl emerge from the same root cause — the gap between what the orchestration layer believes about cluster state and what is actually running. This card bridges directly into the IaC and GitOps disciplines that treat drift as a design problem rather than a remediation task.
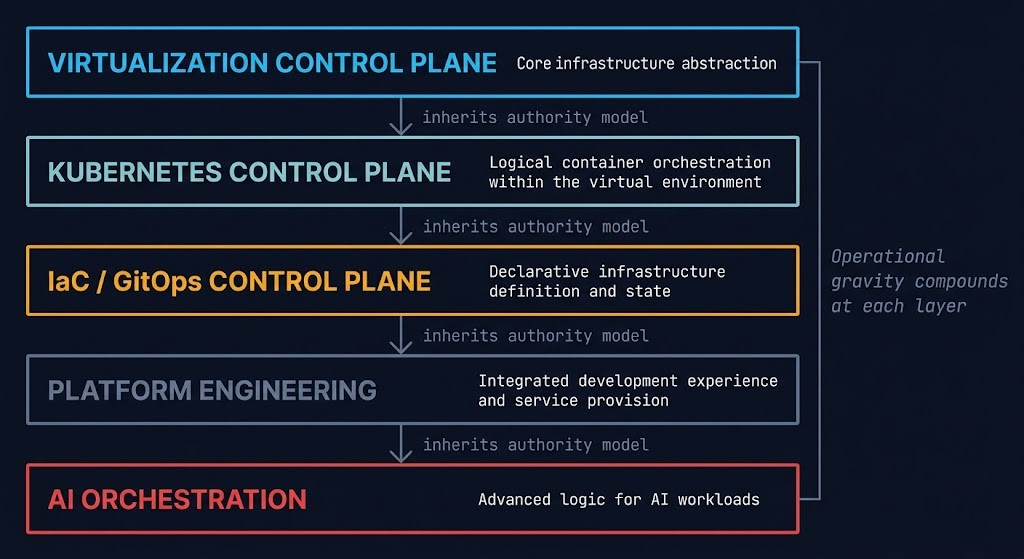
Control Plane Inheritance & Platform Engineering
Kubernetes did not eliminate control plane gravity. It inherited and expanded it. The scheduling authority models, failure amplification patterns, and operational gravity established at the virtualization control plane layer propagate upward into every orchestration layer built above it. IaC treats infrastructure state as a control plane problem. GitOps applies version-controlled authority to the same cluster coordination challenges. Platform engineering abstracts those controls into golden paths that assume the virtualization layer underneath is governable. AI orchestration inherits all of it — GPU placement, cluster state, workload mobility cost — at higher density and shorter tolerance windows.
>_ STAGE GRADUATES CAN NOW
Completing this stage marks the first genuinely operational milestone in the Virtualization Architecture Path. Stage 1 gave you the mechanical vocabulary — the physics of what a hypervisor does. Stage 2 establishes how orchestration authority changes the operational model entirely: where risk concentrates, how scheduling decisions amplify, and why the control plane — not the host — is the unit of architectural accountability. Stage 3 introduces storage and network integration as new failure domains inside the same virtualization control plane architecture model — the operational gravity established here becomes the lens through which those dependencies are evaluated..
- Evaluate virtualization platforms by orchestration authority model rather than feature checklist
- Identify scheduler-driven contention and workload mobility risks before they become operational instability
- Sequence lifecycle and maintenance operations without unintentionally creating outage domains
- Recognize how centralized orchestration concentrates operational gravity and failure amplification
- Understand how virtualization control plane assumptions propagate upward into Kubernetes, IaC, platform engineering, and sovereign infrastructure architecture
>_ SPECIALIZATION TRACKS
The Specialization Tracks branch from this stage because the control plane authority concepts covered here are the prerequisite for every specialization that follows. Compute Architecture, Networking Architecture, Storage Architecture — each one assumes Operational-stage fluency. The Tracks give you depth in a specific discipline without re-explaining the orchestration mechanics established here.
>_ Where Do You Go From Here
YOUR CONTROL PLANE IS AN ARCHITECTURAL DECISION.
FIND OUT IF YOURS IS DEFENSIBLE.
The orchestration authority model you’re running today determines your scheduling behavior, drift exposure, lifecycle risk, and failure amplification pattern. A triage session maps what you have against what your operational maturity can govern.
Migration Readiness Assessment
Control plane authority mapping, scheduling risk analysis, and lifecycle governance review for platform migration decisions.
- > Control plane authority model review
- > Scheduler contention and blast radius mapping
- > Lifecycle sequencing and upgrade domain risk
- > Platform authority model comparison and recommendation
Architecture Playbooks. Field-Tested Blueprints.
Field-tested blueprints for virtualization platform decisions, migration sequencing, and post-VMware operational governance.
- > VMware exit sequencing frameworks
- > Control plane authority migration patterns
- > Scheduler contention playbooks
- > Post-migration operational governance checklists
Zero spam. Unsubscribe anytime.
>_ FREQUENTLY ASKED QUESTIONS
Q: What is a virtualization control plane?
A: A virtualization control plane is the orchestration layer that coordinates scheduling, workload placement, lifecycle operations, cluster state, and inventory authority across many hypervisor hosts simultaneously. It is not the hypervisor itself — the hypervisor executes workloads on a single host. The control plane governs how those hosts behave as a coordinated cluster. In VMware environments, vCenter is the explicit control plane. In AHV, it is distributed across Controller VMs on each node. In Proxmox, cluster coordination uses a quorum-based model without a dedicated management VM.
Q: Why do virtualization clusters become operationally complex at scale?
A: Because orchestration centralizes authority that individual hosts previously handled independently. As cluster size grows, the control plane must coordinate scheduling decisions, track configuration state, manage lifecycle operations across upgrade domains, and enforce placement policies — all simultaneously. Each of those functions introduces a new failure amplification vector: a misconfigured placement rule affects the entire scheduler; a missed upgrade domain sequencing step turns a patch window into an outage domain; a control plane availability event removes governance from the entire cluster at once. Complexity is not a function of host count — it is a function of centralized authority scope.
Q: What is the difference between a hypervisor and a virtualization platform?
A: A hypervisor runs workloads on a single physical host — it handles CPU scheduling, memory isolation, I/O virtualization, and VM lifecycle on that one node. A virtualization platform is the control plane layer that coordinates many hypervisor hosts as a unified cluster. The platform provides scheduling authority across the cluster, manages workload mobility between hosts, enforces placement and resource policies, and handles lifecycle operations at scale. vSphere is a platform; ESXi is the hypervisor. AHV is the hypervisor; the Nutanix distributed cluster with Prism as the management layer is the platform. The distinction matters because the failure domains, operational risks, and architectural decisions are entirely different at each layer.
Q: Why does workload mobility create architectural risk?
A: Because live migration is not free abstraction. Moving a workload between hosts carries cache locality disruption, NUMA alignment changes, storage path renegotiation, and network topology cost — at minimum. For latency-sensitive workloads, NUMA re-pinning after a migration can introduce measurable performance degradation that persists until the scheduler relearns the optimal placement. For GPU workloads, mobility cost is compounded by peer-to-peer bandwidth topology, NVLink configuration, and driver state. DRS makes mobility invisible operationally — which is precisely why the architectural cost must be understood before the scheduler is allowed to make placement decisions autonomously.
Q: How does DRS affect workload determinism?
A: DRS introduces non-determinism into placement by design — its goal is utilization balance, not placement stability. That tradeoff is acceptable in many environments and catastrophic in others. Workloads with strict NUMA locality requirements, predictable memory access patterns, or latency SLAs that depend on specific physical host characteristics lose determinism the moment DRS is permitted to migrate them. The scheduler has no visibility into application-layer topology — it sees CPU utilization and memory pressure, not cache residency, network flow affinity, or storage path latency. For performance-sensitive workloads, DRS rules must encode architectural constraints explicitly — or be disabled entirely on those workloads.
Q: When does virtualization become a platform engineering problem?
A: When the orchestration layer’s operational scope exceeds what manual governance can track. At small scale, a single administrator can reason about cluster state, placement rules, and lifecycle dependencies directly. As cluster count, workload density, and automation surface area grow, the control plane becomes a platform that must itself be governed — through IaC, policy enforcement, drift detection, and access control disciplines that treat the orchestration layer as a first-class infrastructure component. The transition is not triggered by host count. It is triggered by the point at which undocumented control plane state creates operational risk — which typically arrives much earlier than teams expect.
>_ RELATED SYSTEMS
Parent architectural domain — the full pillar covering platform decision frameworks, hypervisor architecture, and operational models.
Open Pillar →Full Domain Path — all 5 maturity stages from Foundation through Sovereign. This page is Stage 02.
Open Domain Path →Prerequisite stage — hypervisor mechanics, abstraction, NUMA topology, and failure domain vocabulary that this stage builds on.
Open Stage →Next maturity transition — storage fabric and network integration as new failure domains inside the control plane authority model established here.
Open Stage →Declarative control planes inherit virtualization assumptions — IaC state models depend on the drift and state management behavior established at this layer.
Open Domain Path →The drift vectors introduced by orchestration at scale — and why detection design outperforms prevention as an operational strategy.
Open Post →VMware’s official documentation on DRS scheduling logic, placement constraints, and cluster resource management architecture.
Open Reference →Nutanix’s technical documentation covering CVM architecture, distributed orchestration, and AHV cluster coordination design.
Open Reference →