Stop Renting Intelligence: The Architect’s Case for On-Prem DSLMs

The new center of gravity. Visualizing the shift from massive public cloud “Brain” models to distributed, highly specialized on-prem “Neural Nodes.”
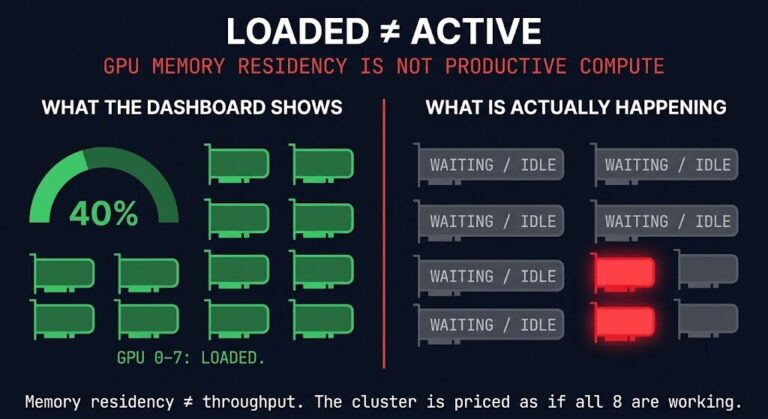
AI repatriation isn’t a trend anymore — it’s an architectural reckoning. For the last two years, enterprises treated AI like a utility bill: swipe the corporate card, send data to an API endpoint, pay per token. Easy. Fast. And now, fiscally unsustainable.
For the last two years, we treated AI like a utility bill. We swiped the corporate credit card, sent our data to an API endpoint (Mistral, OpenAI, Anthropic, Gemini), and paid per token. It was easy. It was fast.
It is also fiscally unsustainable.
As we enter 2026, the math has broken. We are seeing clients whose monthly AI API bills now exceed their entire VMware licensing renewal. Worse, they are realizing that “renting” intelligence for proprietary data is architecturally backward.
The future isn’t one giant model in the sky. It is thousands of Domain-Specific Language Models (DSLMs) running on your own metal, next to your own data.
The Architectural Trade-Off
This decision isn’t philosophical. It’s a four-axis architectural trade-off every enterprise will be forced to make by renewal time:
- Token Cost vs. Utilization Efficiency: Do you pay for every question forever, or buy the brain once?
- Contractual Privacy vs. Physical Control: Is a legal agreement enough, or do you need an air gap?
- Latency vs. Throughput: Do you need real-time local inference or massive batch processing?
- CapEx Shock vs. OpEx Bleed: The pain of buying GPUs vs. the bleeding wound of monthly API bills.
War Story: The $50k “Chatbot” Surprise
Observation from a Fintech Client, Q4 2025.
A mid-sized regional bank built an internal “Knowledge Bot” to help loan officers search PDF policies. They hosted it via a public LLM API using RAG (Retrieval-Augmented Generation).
- Month 1 (Pilot): Cost $500. Everyone loved it.
- Month 3 (Production): The tool went viral internally. Loan officers used it for everything.
- The Bill: $52,000 / month.
The Pivot: They called us in a panic. We helped them “repatriate” the workload. We bought two high-density nodes with NVIDIA L40S GPUs (CapEx: ~$80k one-time). They took an open-source model (Llama 3 70B), fine-tuned it on their docs, and ran it locally.
ROI: The hardware paid for itself in 6 weeks. Now, the marginal cost per query is effectively zero.
The Licensing Blast Radius in Year Two
We’ve seen this movie before. Public AI pricing behaves exactly like enterprise software licensing—except you don’t even own the binaries. This mirrors the exact trap we discussed in our Double EOL Survival Guide regarding legacy software: renting access to a dying asset (or in this case, a rented brain) is a losing strategy.
If you rely solely on public APIs, you are exposing yourself to the “SaaS Lock-in 2.0” effect.
- The “Context Window” Surcharge: Vendors are already introducing tiered pricing for larger context windows. Want to analyze a 500-page legal brief? That’s a premium tier.
- No Exit Leverage: When you build your workflow around a proprietary API (like GPT-5), you cannot leave without rewriting your entire application layer.
- No Depreciation: Your API bill never goes down. Unlike hardware, which depreciates and eventually runs “free” (minus power), rented intelligence costs the same in Year 5 as it did in Year 1.
CapEx vs. OpEx: The CFO’s Reality Check
| Feature | Public API LLM | On-Prem DSLM |
| Cost Curve | Exponential (Scales with usage) | Step Function (Scales with hardware buys) |
| Depreciation | None (100% OpEx forever) | Standard 3-5 Year Hardware Depreciation |
| Marginal Query Cost | Constant ($0.0X per token) | Zero (After hardware purchase) |
| Exit Cost | High (Code Refactoring) | Medium (Data Migration) |
| Data Residency | “Trust Us” (Cloud Region) | Physical Control (Your Data Center) |
Sizing the Hardware: Quantization & Thermal Debt
Architects often fail here because they treat AI nodes like VDI hosts. They are not. They are dense, hot, mathematical furnaces.
1. The VRAM Trap & The Quantization Escape Hatch
You don’t just need “GPU Cores”; you need VRAM. A 70B parameter model requires ~140GB of VRAM to run at full precision (FP16). That forces you into expensive A100/H100 territory.
- The Escape Hatch: Use Quantization. By running inference at INT8 or INT4, you can compress that same model down to ~40GB of VRAM with negligible accuracy loss for most business tasks. This allows you to run enterprise-grade models on cheaper, readily available GPUs (like the L40S or A10).
2. Thermal Debt
AI nodes don’t just consume power; they accumulate Thermal Debt.
A standard 2U AI server can draw 2000W+ continuous load. Unlike a web server that bursts and idles, an LLM inference node runs hot constantly.
- The Risk: Most legacy enterprise racks are designed for 8-10kW per rack. Two or three AI nodes can saturate a standard CRAC unit’s cooling zone.
- Action: Verify your HVAC limits. You may need to space these nodes out (1 per rack) rather than stacking them, creating a new “failure domain” based on heat rather than network.
Why AI Repatriation Starts With Data Gravity
Why move the mountain?
If you have 5PB of customer history, legal archives, and engineering blueprints sitting on a Nutanix Objects store or a Pure FlashBlade, moving that data to the cloud to feed an AI is insanity.
- Egress Fees: The cloud provider taxes you to move data out — and at petabyte scale, that tax restructures the entire architecture. See The Physics of Data Egress for the full cost compounding model.
- Latency: The speed of light is a hard limit. RAG (Retrieval) works best when the “Brain” (GPU) is connected to the “Memory” (Storage) via 100Gb local ethernet.
- If you can manage a SQL database, you can manage a Vector Database.
- The full infrastructure stack — GPU orchestration, fabric design, VRAM sizing, and LLM Ops — is covered in the AI Infrastructure Architecture guide.
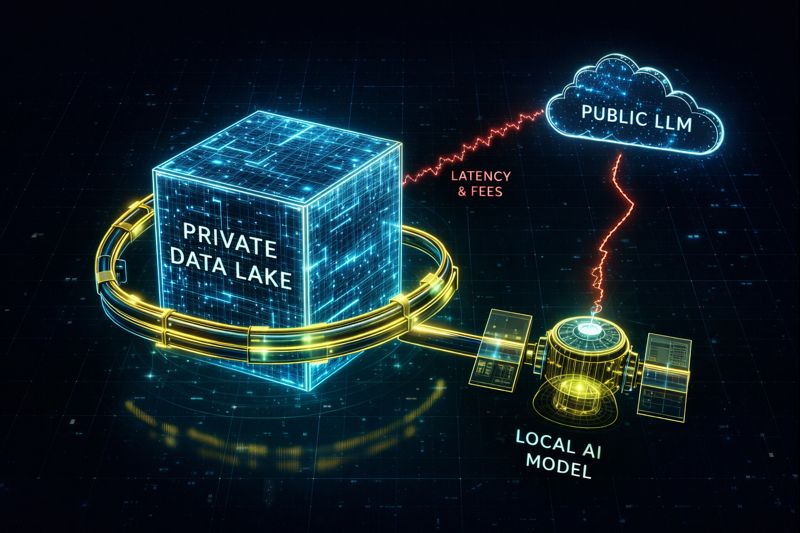
Figure 1: The Repatriation Architecture. Keeping the “Brain” (AI Model) adjacent to the “Memory” (On-Prem Storage) creates a high-speed, zero-egress loop.
Operational Reality: Who Runs This?
The fear is: “We don’t have Data Scientists.”
The reality is: You don’t need them anymore.
The modern “AI Platform” (like Nutanix GPT-in-a-Box) is just an appliance. It’s a VM.
Field Note: Every failed on-prem AI deployment we’ve seen wasn’t a modeling problem—it was a storage or network bottleneck the architect ignored. The model works fine; the pipe feeding it was too small. Check your throughput fundamentals with our Virtualization Architecture Guide before you buy the GPUs.
Architect’s Verdict
AI repatriation isn’t a contrarian position anymore — it’s the financially inevitable conclusion of running production AI workloads at enterprise scale. The $50k chatbot story isn’t an edge case. It’s the standard outcome when token costs compound against an architecture that was never designed to contain them.
The decision framework is straightforward: if your monthly API spend is approaching the amortized cost of owned hardware, the CapEx case is already won. If your data has regulatory residency requirements, the cloud API path was never viable. If your workload is predictable and query volume is stable, the marginal cost of owned inference approaches zero within 12–18 months.
The architects who get this wrong aren’t the ones who chose cloud — they’re the ones who never modeled the exit. Build the four-axis trade-off into your architecture review before the next renewal lands. The question isn’t whether AI repatriation makes sense. It’s whether you model it before or after the bill forces the conversation.
Additional Resources:
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session