Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits.

You built the alert. You configured the dashboard. You set the anomaly threshold at 120% of baseline spend.
And your agentic pipeline still ran $40,000 over budget last quarter.
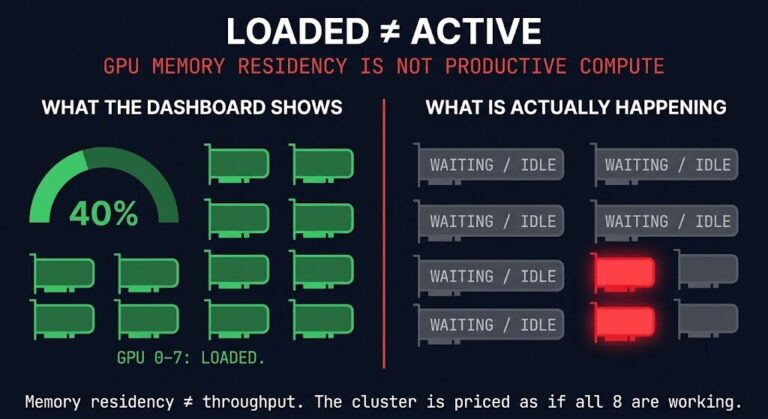
Not because the tools failed. Because alerts and dashboards are not cost controls. They are cost witnesses. They record what happened. They cannot stop what is about to happen.
This is the core AI inference cost control gap in most deployments in 2026: teams have invested heavily in visibility infrastructure and almost nothing in enforcement infrastructure. The result is organizations that can tell you — in impressive detail — exactly how they exceeded their budget, but had no mechanism in place to prevent it.
Part 1 of this series established why AI inference cost emerges from behavior, not provisioning, and why static budget models break under agentic workloads. Part 2 is the solution layer. Execution budgets. What they are, where they live in your architecture, how to model them before production, and what happens when you don’t build them in from day one.
GTC 2026 added a hardware dimension to that argument — dedicated inference infrastructure removes the natural cost feedback loops that shared GPU clusters provided. That context is in The Training/Inference Split Is Now Hardware.
THE ILLUSION OF CONTROL
Before we build the solution, we need to dismantle the tools teams are using as substitutes for it.
Alerts
Alerts fire after a threshold is crossed. By the time an inference cost alert triggers, the spend has already happened. In a human-initiated request architecture — where a user clicks a button and waits for a response — alerts are useful lag indicators. In an agentic architecture running autonomous loops at machine speed, an alert is a postmortem notification dressed up as a safeguard.
Dashboards
Dashboards are exceptional tools for attribution and analysis. They tell you which agent consumed the most tokens, which workflow triggered the most model calls, which pipeline spiked on Tuesday. That information has real value — after the fact, for optimization cycles. It has zero value as a runtime control. A dashboard cannot throttle an agent. It cannot cap a recursive loop. It cannot enforce a token ceiling at the moment of invocation.
Cost Anomaly Detection
Anomaly detection is the most sophisticated of the three illusions. Modern AI cost platforms can identify unusual spend patterns in near-real-time and fire escalating alerts as consumption deviates from baseline. This is genuinely useful — and still insufficient as a primary control. Anomaly detection identifies deviation after it has started accumulating. For an agentic system that can cascade thousands of inference calls in seconds, “near-real-time” is not fast enough to prevent the damage.
Post-Hoc Analysis
Post-hoc analysis is where teams spend the most time and derive the least protection. Understanding why a cost event happened in detail — token-by-token, call-by-call — is valuable input for architectural improvement. It is not cost control. It is cost forensics.
A billing dashboard can tell you what your system did. It cannot stop what it’s about to do.
Visibility is not control. Every one of these tools lives outside the execution path. Execution budgets live inside it.
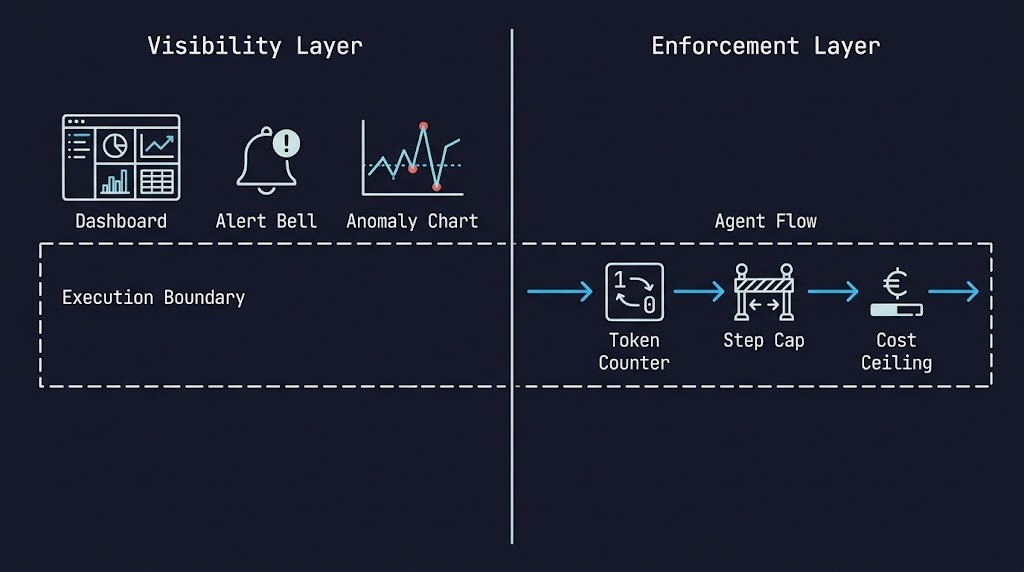
HOW COST ACTUALLY MULTIPLIES
Understanding why execution budgets are necessary requires a precise model of how inference cost compounds in agentic systems. Most teams underestimate this because they reason about cost as if they’re still in a request-response architecture.
They are not.
Consider what happens inside a single user action in a modern agentic system — clean path on the left, real-world path with production retry handling on the right:
Now run that pattern across 10,000 concurrent users. Or an always-on autonomous pipeline that never stops generating requests because no human is waiting for the response.
Cost doesn’t scale with load in agentic systems. It multiplies with behavior.
For the GPU locality and data gravity components of this cost stack, see the AI Infrastructure Strategy Guide.
NAMED FAILURE PATTERNS
Before building the enforcement architecture, you need to recognize what failure looks like in the field. These are the four patterns that account for the majority of uncontrolled inference cost events in production agentic systems.
Runaway Recursion
An agent designed to retry on failure, with no cap on retry attempts, encountering a persistent failure condition. The agent loops. Each loop is a full inference cycle. Without a step ceiling, the loop runs until something external terminates it — the API rate limit, a human intervention, or the billing alarm that fires three hours later.
The architectural failure is simple: recursion guards were not included in the agent loop layer. The agent was given a goal and a retry mechanism. It was not given a limit.
Silent Fan-out
A workflow designed to process items in parallel — often a feature, not a bug — that encounters an unexpectedly large input set. Instead of processing 10 documents in parallel, it processes 10,000. Each document triggers its own inference chain. The cost multiplier is not additive; it is the full per-item cost times the input volume.
Silent fan-out is dangerous because it is architecturally correct behavior. The system did exactly what it was designed to do. Nobody modeled what “exactly what it was designed to do” would cost at 1,000x the expected input size.
Cost-Latency Coupling
A team optimizes an agent pipeline for response speed by parallelizing inference calls — running multiple model invocations simultaneously rather than sequentially. Latency drops significantly. Cost increases non-linearly, because the optimization that reduced latency by 40% tripled the number of simultaneous model calls.
The trap is that cost and latency were treated as independent variables during the optimization cycle. In an agentic system, they are coupled. Architectural decisions that improve one frequently degrade the other.
Partial Budget Enforcement
The most common failure pattern in organizations that have already invested in cost controls. Budget enforcement exists — but only at one layer. The API gateway has rate limits. The billing platform has spend caps. But the agent loop has no step ceiling, and the orchestration layer has no workflow-level cost ceiling.
An agent that stays under the per-request token limit can still run 10,000 requests. A workflow that never triggers the billing spend cap can still cascade silently for hours before the total crosses the threshold. Partial enforcement gives teams confidence that does not match the actual protection in place.
WHAT AN EXECUTION BUDGET ACTUALLY IS
An execution budget is a runtime constraint — a limit on how much work an agent, workflow, or pipeline is permitted to perform, enforced at the moment of execution, not after the fact.
The key word is enforced. A budget that exists only as a configuration value in a dashboard is a reporting parameter. A budget that lives in the execution path — that the system checks before invoking a model, before spawning an agent step, before triggering a tool call — is an actual control.
Execution budgets operate across four dimensions:
- Token budgets — cap the number of tokens consumed per invocation, per session, or per workflow
- Step budgets — cap the number of agent loop iterations, recursion depth, or tool invocations
- Time budgets — cap the wall-clock time a workflow is permitted to run before forced termination
- Cost budgets — cap the total inferred cost of a workflow or agent session in real-time currency terms
Each dimension controls a different failure mode. A token budget prevents runaway prompts. A step budget prevents infinite loops. A time budget prevents stuck workflows. A cost budget prevents cascading spend.
A production agentic architecture needs all four. Enforcing only one is partial budget enforcement — the failure pattern described above. Execution budget enforcement is also a cluster orchestration problem. Where budgets are enforced depends on whether your execution environment has the placement authority to act on them — that’s the scheduling and admission control layer covered in the Runtime & Cluster Orchestration stage of the AI Architecture Learning Path.
For how these enforcement patterns translate to Kubernetes-level resource constraints, see the K8s in-place resize post.
THE ENFORCEMENT STACK
Execution budgets are not a single control. They are a layered enforcement architecture. Each layer addresses a different scope of execution, and each layer has different failure modes it is responsible for preventing.
Layer 1 — Invocation Layer
Scope: Individual model calls
Controls: Per-request token limits, context size caps, output length constraints
Failure prevented: Runaway prompts, token bloat from oversized context windows
Where it lives: API gateway, model client configuration, prompt layer
This is the cheapest enforcement point and the most overlooked. System prompt constraints, structured output requirements, and hard token ceilings on model invocations prevent cost accumulation at the source — before the request reaches the model. A token limit enforced at the invocation layer costs nothing to run and prevents the most common form of per-call cost overrun.
Layer 2 — Agent Loop Layer
Scope: Individual agent execution cycles
Controls: Step caps, recursion guards, retry limits, tool call budgets
Failure prevented: Runaway recursion, infinite loops, retry storms
Where it lives: Agent framework configuration (LangChain, LangGraph, AutoGen, custom orchestrators)
The agent loop layer is where recursion guards live. Every agent that has a retry mechanism needs a step ceiling. Every agent that can call itself recursively needs a recursion depth limit. These are not optional guardrails — they are the architectural difference between an agent that recovers from failure and an agent that loops until something external kills it.
Layer 3 — Orchestration Layer
Scope: Multi-step workflows and pipelines
Controls: Workflow-level cost ceilings, parallel execution limits, fan-out caps, time boundaries
Failure prevented: Silent fan-out, cost-latency coupling, stuck workflows
Where it lives: Workflow orchestration layer (Airflow, Prefect, Temporal, Step Functions)
The orchestration layer is where fan-out gets governed. Before a workflow spawns parallel branches, the orchestration layer should evaluate the input set size against a configured fan-out limit. A workflow that processes documents in parallel needs a ceiling on how many documents it will process in a single execution — not as a throughput constraint, but as a cost constraint. That ceiling belongs at the orchestration layer, not in the billing dashboard.
Layer 4 — Platform Layer
Scope: Global system-level spend
Controls: Org-level quotas, model-level spend caps, team-level budgets, hard cutoffs
Failure prevented: Cascading spend that escapes workflow-level controls
Where it lives: Cloud provider quota management, API provider usage tiers, FinOps platform configuration
The platform layer is the backstop — the control that catches everything the layers above it missed. It should never be the primary enforcement mechanism. An organization that relies on platform-layer spend caps as its primary cost control has effectively decided to accept partial budget enforcement. Platform-layer controls exist to catch the failures that slip through, not to substitute for the enforcement stack above them. Governing the enforcement stack across production — detecting partial enforcement, tracking budget adherence over time, and correlating cost signals to execution behavior — is the operational layer covered in Operations & LLMOps Architecture.
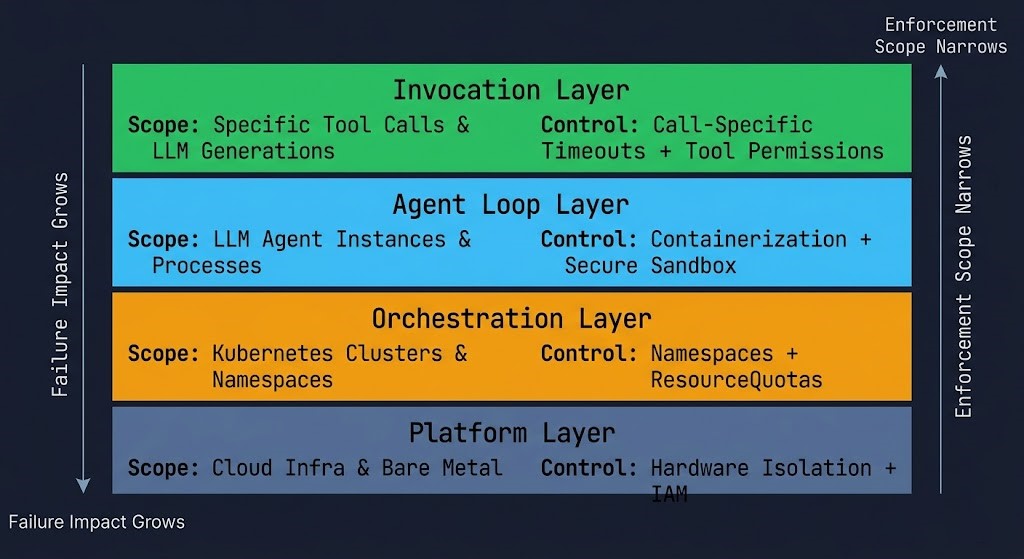
THE BUDGET REFERENCE TABLE
| Budget Type | What It Controls | Failure Prevented | Enforcement Layer | Where It Lives |
|---|---|---|---|---|
| Token | Model cost per call | Runaway prompts | Invocation | API gateway / prompt config |
| Output | Response size / token bloat | Context overflow | Invocation | Model client / system prompt |
| Step | Agent recursion depth | Infinite loops | Agent loop | Framework config |
| Retry | Failure recovery attempts | Retry storms | Agent loop | Framework config |
| Fan-out | Parallel branch count | Silent fan-out | Orchestration | Workflow orchestrator |
| Time | Wall-clock execution window | Stuck workflows | Orchestration | Workflow orchestrator |
| Cost | Total inferred spend | Cascading spend | Platform | FinOps / quota management |
MODELING CASCADE COST BEFORE PRODUCTION
The failure patterns described above are preventable — but only if cost modeling happens before the system goes live, not after the first billing surprise.
Cascade cost modeling requires three inputs:
1. The invocation graph
Map every model call your system can make for a given input. Include conditional branches, retry paths, and tool invocations. This is not documentation — it is a prerequisite for cost modeling. If you cannot draw the invocation graph, you cannot model the cost.
2. The input envelope
Define the realistic range of inputs your system will process. Not average-case — full range, including edge cases and unexpected input sizes. Silent fan-out almost always originates in an input envelope that was modeled at average case and encountered the tail.
3. The cost-per-invocation at each node
Token costs per model, tool invocation costs, egress costs for cross-zone calls. Each node in the invocation graph has a cost attached to it. The cascade cost is the sum of all paths, weighted by their probability and multiplied by their input volume.
With these three inputs, you can model the expected cost per user action, the worst-case cost at the tail of the input envelope, and the break-even point where parallel optimization becomes cost-negative.
Build this model before you build the enforcement stack. The enforcement stack parameters — step caps, fan-out limits, token ceilings — should be derived from the cost model, not from intuition.
For cross-cloud inference cascade cost components including egress modeling, see the Multi-Cloud AI Stack Architecture. For GPU locality cost inputs to the cascade model, see AI Cloud Architectures: GPUs, Neoclouds and Network Bottlenecks.
Architect’s Verdict
The 2026 inference cost problem is not a FinOps problem. It is an architecture problem wearing a FinOps costume.
Organizations that treat it as a FinOps problem buy dashboards and configure alerts and schedule quarterly spend reviews. They have excellent visibility into how they exceeded their budget. They exceed it again next quarter. The structural reason is the Cost Authority Inversion — AI workloads have inverted the ownership model that traditional FinOps was built on.
Organizations that treat it as an architecture problem build enforcement into the execution path. They model cascade cost before deployment. They implement step caps, token ceilings, fan-out limits, and time boundaries at the layers where they can actually intercept execution — not in the billing platform where they can only observe it.
The enforcement stack described in this post is not complex to build. Most agent frameworks expose the configuration surface for step caps and retry limits. Most orchestration platforms support workflow-level cost ceilings. The platform layer budgets are already available from your cloud provider.
What has been missing is not the tooling. It is the architectural intent — the decision to treat cost as a first-class constraint that belongs in the execution path, enforced at runtime, modeled before production.
Execution budgets are not a feature you add to an agentic system after it misbehaves. They are a load-bearing component of the architecture.
Build them in from day one. Model the cascade before the first production invocation. Enforce at every layer, not just the one that was easiest to configure.
A billing dashboard can tell you what your system did. The enforcement stack controls what it does next.
ADDITIONAL RESOURCES
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session