InfiniBand Is Losing the Fabric War. Here’s What That Changes for Your Architecture.
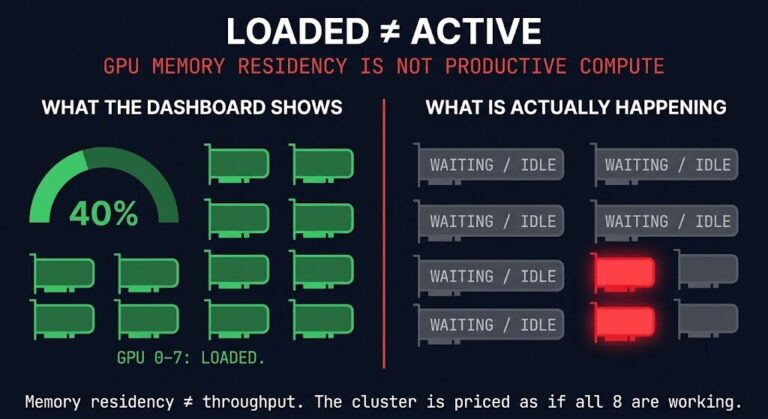
The InfiniBand vs RoCEv2 decision has been settled at the hyperscaler level — and the answer is Ethernet. Broadcom’s March 2026 earnings confirmed what most AI infrastructure architects had already suspected: roughly 70% of new AI infrastructure deployments are now choosing Ethernet-based fabrics over InfiniBand. That number is worth sitting with for a moment — because it didn’t happen because Ethernet got faster. It happened because InfiniBand ran out of room.
InfiniBand Didn’t Lose on Performance
Let’s be precise about what the InfiniBand vs RoCEv2 shift actually means — and what it doesn’t. InfiniBand remains a technically superior fabric for a specific class of problem: tightly coupled, homogeneous, single-vendor GPU clusters running large-scale distributed training in a controlled environment. At that workload, in that environment, InfiniBand’s latency characteristics and RDMA implementation are still genuinely differentiated.
The shift isn’t a performance verdict. It’s an ecosystem verdict. InfiniBand is losing the fabric war because of operational isolation, vendor lock-in, and scaling friction in the environments where enterprise AI actually runs — not because RoCEv2 won a latency benchmark. That distinction matters architecturally, because the decision in front of most teams right now is not “which fabric is faster.” It’s “which fabric can we actually operate at scale, across environments, with the team we have.”
The InfiniBand vs RoCEv2 decision is no longer about performance. It’s about ecosystem alignment, operability, and scale economics. And on those dimensions, the trend line is unambiguous.
What’s Actually Happening
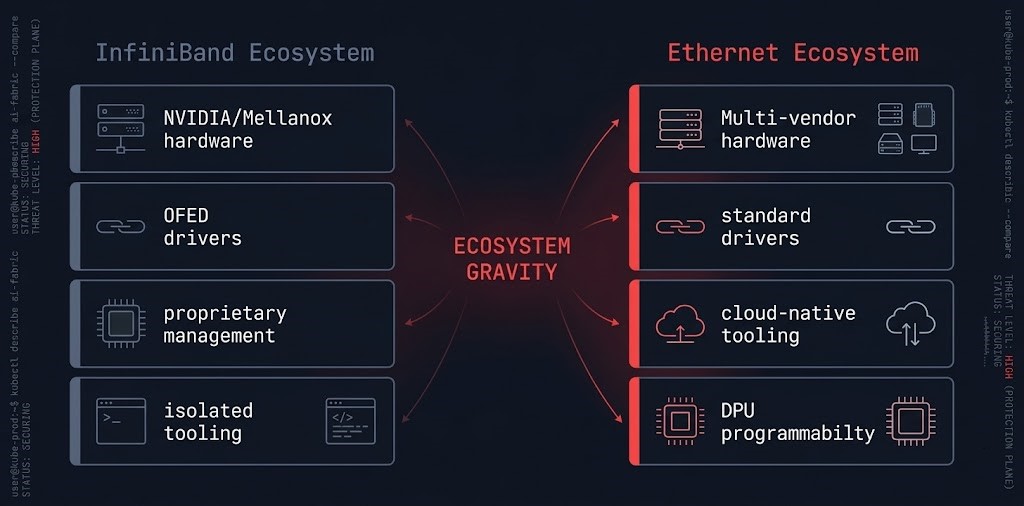
Three forces are converging to push AI infrastructure fabric decisions toward Ethernet, and none of them are primarily about raw throughput.
The hyperscalers moved first. AWS, Google, and Microsoft have all built or are building their AI backend fabrics on Ethernet-based architectures — either RoCEv2 over merchant silicon or custom implementations derived from the same principles. When the largest AI training environments in the world converge on a fabric model, the tooling, operational expertise, and ecosystem around that model compounds. Teams who train on cloud infrastructure and then build on-premises AI clusters face a jarring operational discontinuity if they select InfiniBand for the private side.
The Ultra Ethernet Consortium formalized the direction. The UEC — backed by AMD, Broadcom, Cisco, HPE, Intel, Meta, and Microsoft among others — is building AI-optimized extensions to Ethernet specifically to close the gap with InfiniBand for distributed training workloads. The congestion control, in-sequence delivery, and multipath capabilities that InfiniBand had as native features are being engineered into the Ethernet stack as open standards. The competitive gap is narrowing from below, not from above.
Broadcom’s March 2026 earnings put a number on it: roughly 70% of new AI infrastructure deployments are now selecting Ethernet/RoCEv2 protocols — a shift Broadcom’s own switching platforms are built to capture. NVIDIA is still pushing InfiniBand — but increasingly as part of a vertically integrated stack that includes the GPU, the NIC, the switch, and the software. That integration delivers real performance. It also delivers real lock-in. For organizations evaluating multi-vendor GPU procurement or heterogeneous inference environments, the tightly coupled NVIDIA InfiniBand stack is not a fabric choice. It is a platform commitment.
Why InfiniBand Is Losing in Practice
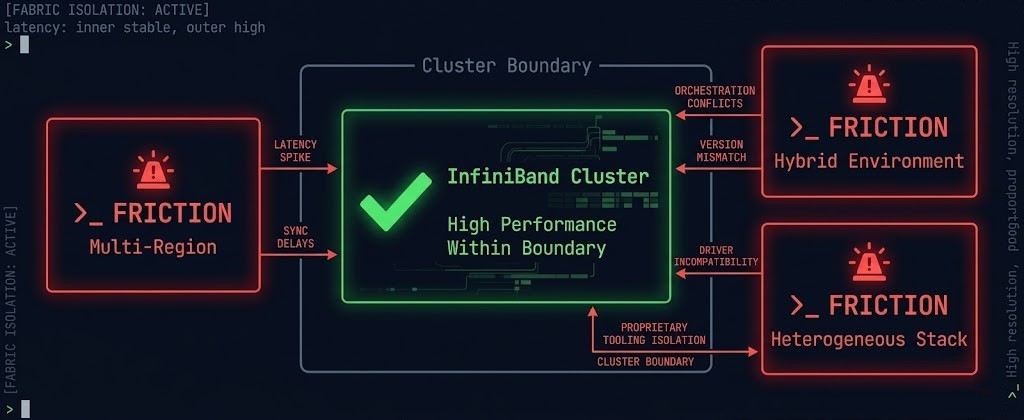
The architectural case against InfiniBand is not about what it cannot do at peak performance. It’s about three structural constraints that compound as environments grow.
Why Ethernet Is Winning
RoCEv2 is not winning because it is technically superior to InfiniBand in a controlled benchmark. It is winning because it removes the operational, ecosystem, and scaling constraints that InfiniBand carries — at a cost point and interoperability profile that compounds over time.
Ecosystem gravity is the primary force. Ethernet is the fabric of cloud infrastructure, enterprise networking, and the operational knowledge base of virtually every network engineer alive. When you choose RoCEv2, you are not choosing a networking protocol — you are choosing alignment with the tooling, talent, and integration patterns that the rest of your infrastructure already runs on. Monitoring integrates natively. Automation uses the same frameworks. Incident response uses the same diagnostic tools.
Programmability is the second force. DPUs and SmartNICs — NVIDIA BlueField, AMD Pensando, Intel IPU — sit on top of Ethernet and offload networking functions, security processing, and storage I/O to dedicated silicon without touching the host CPU. This programmability layer is native to the Ethernet ecosystem and does not exist in the same form on InfiniBand. For AI infrastructure architects building software-defined fabric policies, congestion control automation, or integrated security enforcement at the network layer, Ethernet provides the programmability surface that InfiniBand does not.
Cloud alignment is the third force. If your AI workloads span cloud training bursts and on-premises inference, or if your architecture involves hybrid connectivity between private GPU clusters and cloud-based retrieval or storage layers, a single consistent fabric model across both environments eliminates an entire class of integration friction. InfiniBand at the edge of a hybrid boundary requires gateways. Ethernet on both sides requires a routing decision — which is a solved problem.
The Real Shift: The Fabric Is Becoming Software
The deeper architectural change is not InfiniBand vs. RoCEv2. It is the transition of the fabric from a hardware-defined performance layer to a software-defined, policy-driven component of the infrastructure stack. That transition is native to Ethernet. It does not fit cleanly into InfiniBand’s design model.
The deterministic networking architecture that AI training clusters require — symmetric leaf-spine topology, ECN over PFC for congestion signaling, adaptive routing for failure recovery — is increasingly being implemented through programmable logic at the switch and NIC layer, not through hardware-enforced InfiniBand primitives. RDMA over Converged Ethernet achieves the low-latency, kernel-bypass memory access that distributed training requires. ECN provides the congestion feedback that keeps P99 latency deterministic without hardware credit-based flow control. Adaptive routing re-paths around failure without manual intervention. The full technical implementation of this stack is covered in Distributed AI Fabrics.
What this means operationally: the fabric engineering discipline is converging with the platform engineering discipline. Fabric policy — congestion thresholds, routing logic, QoS configuration — is increasingly expressed as code, version-controlled, and enforced through the same IaC pipelines that provision the rest of the AI infrastructure stack. That model is natural in an Ethernet environment. It requires significant tooling investment to replicate in an InfiniBand environment. That software-defined trajectory is also where the governance question enters. As fabric policy becomes programmable and the network layer begins making placement and routing decisions at infrastructure scope, it starts accumulating control plane authority. The network is becoming the AI control plane — the convergence point where routing authority, telemetry, and policy enforcement meet as inference execution distributes across substrates.
What Most Teams Will Miss
The teams that will make the wrong fabric decision in 2026 are not the ones that don’t understand InfiniBand’s performance characteristics. They are the ones benchmarking raw latency while ignoring the three dimensions that will actually determine operational cost over the lifecycle of the deployment.
The cost of complexity is the dimension most teams underestimate until they are operating the cluster in production. InfiniBand expertise is genuinely scarce. Specialized tooling requires specialized operations. Failure events in InfiniBand fabrics produce failure modes that Ethernet engineers do not immediately recognize. The gap between peak benchmark performance and sustained operational performance widens with team specialization constraints. A cluster that achieves 95% of InfiniBand’s throughput on RoCEv2 while being operable by the team that already runs the rest of the infrastructure is a better architecture outcome than a cluster that achieves 100% throughput and requires a dedicated fabric specialist to keep it running.
What This Means for Your Architecture
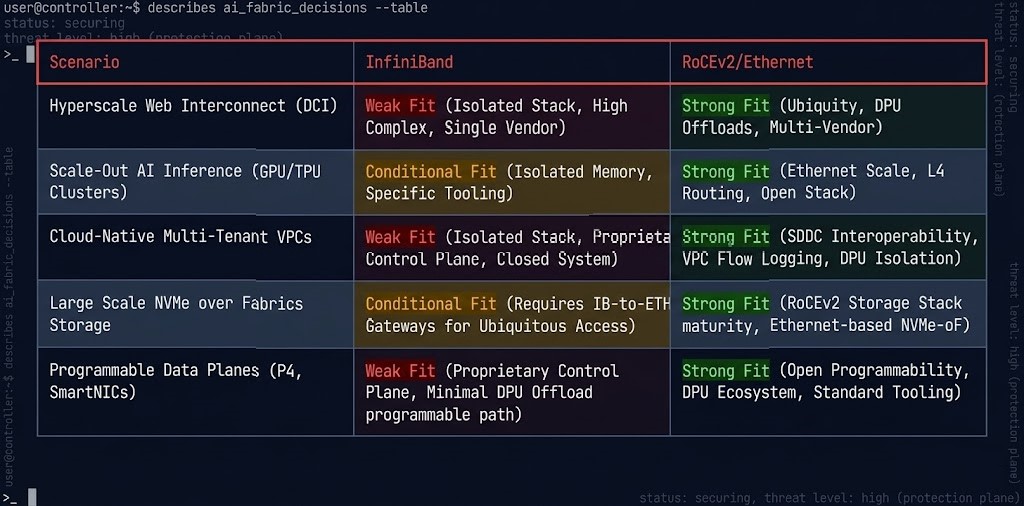
The InfiniBand vs RoCEv2 decision in 2026 is not a binary verdict — it is a workload-specific evaluation that most teams are still running through the wrong framework. The 70/30 Ethernet split means InfiniBand is no longer the default answer for any workload — and that changes the starting point for every fabric conversation.
| Scenario | InfiniBand | RoCEv2 / Ethernet |
|---|---|---|
| Homogeneous NVIDIA GPU cluster, isolated training | Strong fit | Strong fit — evaluate operational overhead |
| Heterogeneous GPU environment (multi-vendor) | Friction at boundaries | Natural fit |
| Hybrid cloud + on-prem AI architecture | Hard boundary complexity | Consistent model across environments |
| Inference-only cluster | Overcomplicated for workload | Right-sized for latency requirements |
| Team with existing Ethernet expertise | Operational gap — assess hiring cost | No gap |
| Multi-region AI infrastructure | Not designed for this boundary | Cloud-native alignment |
The evaluation framework is not “is InfiniBand better?” It is three questions: What is your workload type — training, inference, or both? What is your scale model — isolated private cluster, hybrid, or multi-region? And what is your team’s operational capability and hiring model? For large-scale isolated training on homogeneous NVIDIA hardware, InfiniBand remains a valid selection. For everything else — and for most enterprise AI deployments that involve hybrid connectivity, heterogeneous environments, or inference serving — RoCEv2 on a deterministic Ethernet fabric is the architecture that compounds operational simplicity over time. The AI Infrastructure pillar covers the full stack decision framework, including where fabric choice intersects with inference cost architecture and the training/inference hardware split that GTC 2026 formalized.
Architects working through the full fabric decision — topology, congestion control, hybrid boundary design, and the Execution Locality Boundary — will find the structured reading sequence in the Fabric Architecture stage of the AI Architecture Learning Path.
Architect’s Verdict
The InfiniBand vs RoCEv2 question is settled at the ecosystem level — but not at the workload level. InfiniBand is not disappearing. It will remain the correct selection for specific, bounded, high-performance training environments — particularly those already committed to the NVIDIA full-stack model. But it is no longer the presumptive default for AI fabric decisions. The 70/30 Ethernet split reflects a market that has moved past the performance comparison phase and into the operational reality phase of AI infrastructure deployment at scale.
- [+]Evaluate fabric against workload type, scale model, and team capability — not benchmark scores
- [+]Model the operational cost of InfiniBand expertise — specialization has a real hiring and retention cost
- [+]Design the hybrid fabric boundary explicitly before committing — InfiniBand-to-Ethernet bridging adds latency and complexity
- [+]Treat ECN configuration and congestion control as first-class architecture decisions on RoCEv2 — not default settings
- [!]Default to InfiniBand “because AI” — the workload, environment, and team all shape the right answer
- [!]Treat RoCEv2 as a drop-in replacement without engineering the congestion control layer — misconfigured RoCEv2 performs worse than InfiniBand under load
- [!]Benchmark only peak throughput — operability, failure recovery, and hybrid boundary cost determine production outcomes
- [!]Lock in fabric before modeling the training vs. inference infrastructure split — they have different latency requirements and different fabric optimization profiles
The fabric decision is the foundation of every AI infrastructure choice made above it — GPU placement, storage topology, hybrid connectivity, inference routing, and cost architecture all inherit its constraints. Getting it right means evaluating it as a systems decision, not a networking benchmark. For the full AI infrastructure stack context — from silicon through operations — the AI Infrastructure Architecture pillar is the right starting point. For the deterministic networking layer that sits directly above the fabric, Deterministic Networking for AI Infrastructure covers P99 latency physics, RDMA configuration, and the congestion control implementation that determines whether your fabric performs at benchmark or at production.
Frequently Asked Questions
Q: Is InfiniBand still worth using for AI infrastructure in 2026?
A: For specific, bounded workloads — large-scale distributed training on homogeneous NVIDIA GPU clusters in isolated on-premises environments — InfiniBand remains a technically strong selection. The performance characteristics are real. The question is whether the operational constraints, vendor lock-in, and scaling friction of InfiniBand are acceptable trade-offs for the workload and environment in question. For most enterprise AI deployments involving hybrid connectivity, heterogeneous hardware, or inference-heavy workloads, RoCEv2 on a properly engineered Ethernet fabric delivers sufficient performance with significantly lower operational overhead.
Q: What is RoCEv2 and how does it compare to InfiniBand for AI training?
A: RoCEv2 (RDMA over Converged Ethernet v2) is a network protocol that provides RDMA capabilities — kernel-bypass, low-latency memory access — over standard Ethernet infrastructure. For distributed AI training, it achieves the fundamental requirement of InfiniBand (low-latency, high-throughput inter-node communication for gradient synchronization) while using the Ethernet ecosystem for hardware, tooling, and operations. The performance gap between well-configured RoCEv2 and InfiniBand has narrowed significantly as congestion control (ECN), adaptive routing, and hardware offload capabilities have matured. The key caveat: misconfigured RoCEv2 performs significantly worse than InfiniBand under load. The congestion control layer must be engineered deliberately — it is not a default-on capability.
Q: What is the Ultra Ethernet Consortium and why does it matter?
A: The Ultra Ethernet Consortium (UEC) is an industry group — including AMD, Broadcom, Cisco, HPE, Intel, Meta, and Microsoft — developing AI-optimized extensions to the Ethernet standard specifically to address the use cases where InfiniBand has historically had an advantage: large-scale distributed training with tight latency requirements and reliable message delivery. The UEC is engineering congestion control, in-sequence delivery, and multipath capabilities as open Ethernet standards. Its significance is that it represents the industry formally standardizing the convergence of AI fabric requirements and Ethernet infrastructure — making the performance gap between InfiniBand and Ethernet a narrowing target rather than a fixed differential.
Q: What is the risk of misconfigured RoCEv2 in an AI training cluster?
A: Misconfigured RoCEv2 is one of the most common causes of underperforming AI training clusters. The two most critical configuration requirements are ECN (Explicit Congestion Notification) and PFC (Priority Flow Control) settings. Without proper ECN configuration, RoCEv2 defaults to loss-based congestion signaling — which causes RDMA connections to reset under congestion, producing exactly the P99 latency spikes that stall gradient synchronization. Improperly tuned PFC settings create head-of-line blocking that degrades all traffic classes. A cluster that benchmarks well on InfiniBand and then underperforms on RoCEv2 is almost always a congestion control configuration problem, not a fundamental protocol limitation.
Q: How does the InfiniBand vs. RoCEv2 decision interact with the training vs. inference split?
A: Training and inference have different fabric requirements. Training workloads require deterministic, low-latency, high-bandwidth all-to-all communication for gradient synchronization — the use case InfiniBand was optimized for. Inference workloads require consistent P99 latency for individual request handling, but do not require the same all-to-all collective communication patterns. For organizations building separate training and inference infrastructure — which GTC 2026 formalized as the hardware-level standard — a single fabric choice does not need to serve both workloads. Training clusters can be evaluated against InfiniBand’s strengths. Inference infrastructure almost universally selects Ethernet-based fabrics for cost, operability, and cloud alignment reasons.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session