CLOUD ARCHITECTURE STRATEGY
DISTRIBUTED CONTROL PLANES & IDENTITY-FIRST SECURITY.
Cloud is not a destination. It is a control plane — and like every control plane, it fails when the architecture beneath it is misunderstood.
For a decade, the default enterprise cloud strategy was “lift and shift”: move workloads wholesale, assume the provider handles resilience, and figure out the bill later. The bill arrived. The post-mortems followed. The lesson was consistent: cloud cost is an architecture problem, not a finance problem. Egress charges, zombie resources, over-provisioned reservations, and misaligned workload placement are not billing anomalies — they are architectural decisions that weren’t made.
This pillar covers cloud architecture from first principles. Not provider feature lists. Not vendor migration playbooks. The physics of how cloud behaves — economically, topologically, and operationally — and the decision frameworks that let architects place workloads with precision rather than optimism.
The four domains covered here — AWS, Azure, GCP, and Cloud Native — are not interchangeable. Each has a distinct compute model, a distinct data gravity profile, and a distinct cost envelope. Getting cloud right means understanding those differences before you commit capacity, not after you read the invoice.
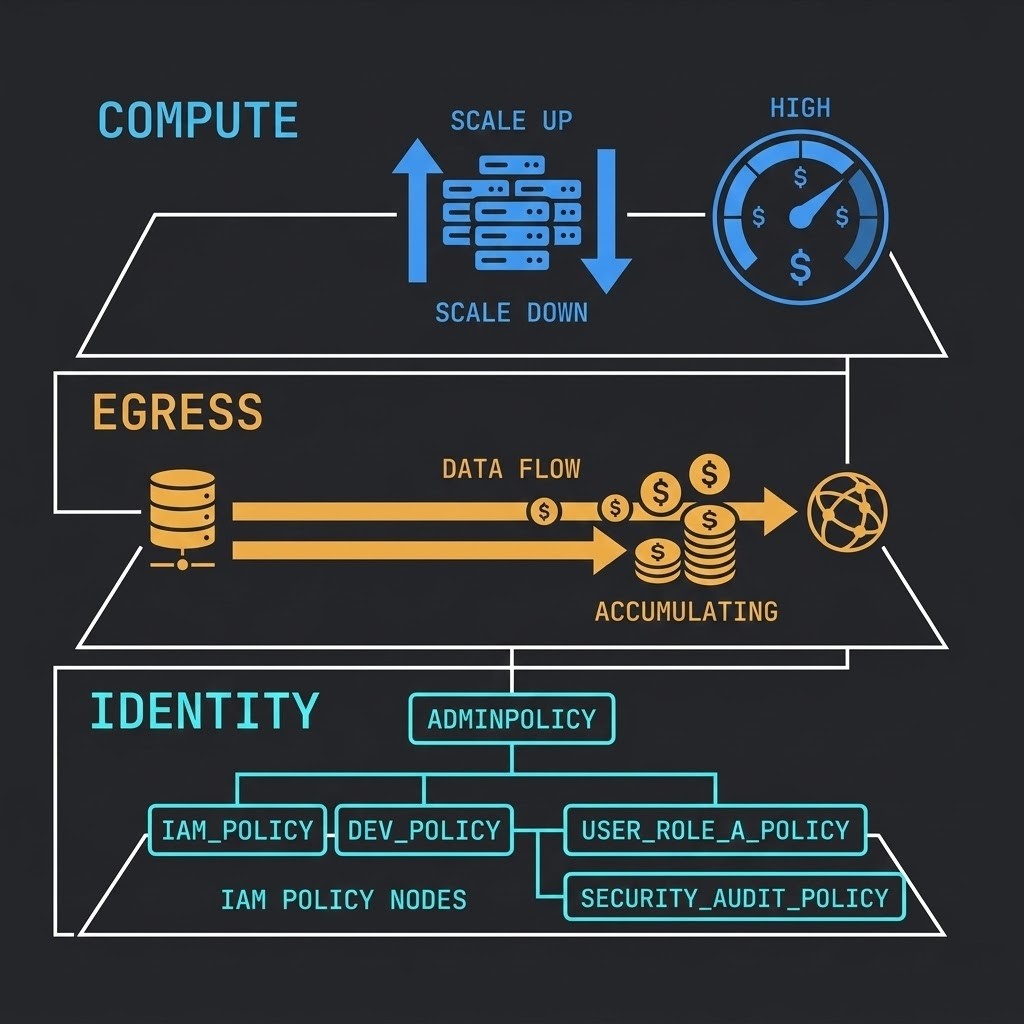
The Physics of Cloud Infrastructure
Cloud cost is metered physics, not subscription pricing.
Every resource unit you consume — compute cycle, storage byte, network packet — has an economic weight attached to it. The providers abstract this into hourly rates and GB/month figures, but the underlying reality is simpler and more dangerous: cloud charges you for every decision you don’t make explicitly.
Elasticity has a floor. Cloud compute scales down, but not to zero unless you architect for it. A VM left running at 3% utilisation costs the same as one running at 90%. Reserved instances reduce unit cost but create a new liability: underutilised commitment. The discipline of cloud cost management is not FinOps tooling — it is rightsize-by-design, enforced at the architecture layer before provisioning begins.
Egress is the hidden gravity well. Moving data into a cloud provider is free or near-free. Moving data out — to another region, another provider, or back on-premises — is charged at rates that compound rapidly at enterprise data volumes. A 500TB dataset doesn’t just cost money to move — it costs time, and every hour that transfer runs is another hour of metered egress exposure. The Physics of Data Egress post covers the exact mechanics of how egress burns budget and what architectural guardrails prevent it.
Identity is the real control plane. Firewalls are not the perimeter in cloud environments — IAM is. Every resource, every API call, every cross-service interaction is governed by an identity policy. When that policy is fragmented across providers or misconfigured, you don’t have a hybrid cloud — you have multiple silos with a shared blast radius. The Multi-Cloud Cascading Failure series documents exactly how identity dependency creates outage amplification across providers.
Cost explosion has a taxonomy. The most common causes of runaway cloud spend are well-documented: over-provisioned compute reservations, data egress from unplanned replication, zombie load balancers accumulating across forgotten deployments, and snapshot policies with no expiry logic. The \$7,200 Zombie Load Balancers post dissects a real failure taxonomy. The Your Cloud Bill Quietly Increased in 2026 analysis maps the current cost drivers across providers.
The shim tax is real. Hybrid cloud creates integration seams — identity federation, network bridges, data synchronisation pipelines — each of which carries an operational overhead that doesn’t appear on a provider invoice. The Shim Tax covers the hidden engineering cost of operating across boundaries. Every integration point you add is a failure domain you must now maintain.
The Cloud Architecture Stack
Cloud is not a single platform. It is a layered architecture — and most comparisons evaluate only one layer.
| Layer | Description |
|---|---|
| Identity | IAM / Entra / federation / service identity |
| Network | VPC / VNets / routing / connectivity |
| Compute | VMs, containers, serverless |
| Data | Storage, databases, analytics engines |
| Control Plane | APIs, automation, governance |
Most cloud outages and cost explosions occur at layer boundaries — identity ↔ network, compute ↔ data, or control plane ↔ provisioning automation. The provider manages each layer’s underlying infrastructure. The architecture of how your layers interact is yours to own. A misconfigured identity boundary doesn’t trigger a provider SLA violation — it triggers your incident response.
Understanding which layer a failure originated in is what separates cloud architects from cloud operators.
Cloud Failure Modes
Cloud doesn’t fail the way on-premises infrastructure fails. The failure modes are architectural — and most of them are preventable.
| Failure Mode | Cause |
|---|---|
| Regional dependency | Service built assuming regional independence — single AZ or region coupling without failover design |
| IAM misconfiguration | Privilege escalation, overly permissive service roles, or identity federation gaps creating service lockout |
| Cross-region data replication | Unmodelled egress surge from replication jobs — typically discovered at month-end billing, not at provisioning |
| Control-plane throttling | API rate limits hit during autoscaling events — provisioning automation stalls while the load it was responding to continues |
| Provider service dependency | Managed service cascading failure — when a provider’s managed database, queue, or DNS has an outage, every service depending on it goes with it |
These failure modes are not theoretical. The Multi-Cloud Cascading Failure series documents the operational chain that connects each one. The pattern is consistent: the architecture worked correctly until a boundary condition the design hadn’t modelled was reached.
Cloud Operating Models
Architecture doesn’t fail in isolation. It fails because the operating model couldn’t sustain it.
The decision about how your teams own cloud infrastructure is as consequential as the decision about where workloads run. Most cloud cost and outage post-mortems trace back to an operating model mismatch — architecture designed for centralized governance being operated by federated teams, or federated product ownership without the cost accountability to match.
| Model | Description |
|---|---|
| Centralised platform team | Shared cloud governance — single team owns landing zones, networking, IAM policy, and provisioning standards across the organisation |
| Federated product teams | Product-level infrastructure ownership — each team manages its own cloud resources within guardrails set by a central policy layer |
| Platform engineering | Internal developer platform — a dedicated team builds and operates abstractions that product engineers consume, removing direct cloud API exposure |
| FinOps-driven governance | Cost observability and enforcement — cloud spend is attributed at team or product level, with budget ownership and chargeback models that create accountability at the provisioning decision |
Most organizations operate a hybrid of these models — centralized networking and identity with federated compute ownership, or platform engineering with FinOps attribution layered on top. The failure condition is not which model you choose; it is when the architecture assumes a level of governance discipline the operating model cannot deliver.
The Four Cloud Domains
No two cloud providers are architecturally equivalent.
The 2020 assumption — that workloads could be arbitraged across providers with minimal friction — broke against data gravity and platform specificity. In 2026, multi-cloud means best-of-breed silos, not workload mobility. You are not moving VMs between AWS and Azure. You are managing three radically different IAM models, three different networking topologies, and three different cost envelopes simultaneously.
Each domain below has a distinct architectural profile. Sub-pillar pages cover the depth. The decision framework in Section 5 maps workload types to placement logic.
Which Workloads Belong in the Cloud
Not every workload is a cloud workload. This is still an uncomfortable truth in 2026.
The repatriation wave is real. Teams that migrated everything to public cloud between 2018 and 2022 are now selectively moving high-volume, steady-state workloads back on-premises — not because cloud failed, but because the economic model only works for specific workload profiles. Repatriation is not a retreat. It is a correction.
The workload fit model below is not a feature comparison. It is an economic and operational decision framework based on three variables: utilisation pattern, data gravity, and latency sensitivity.
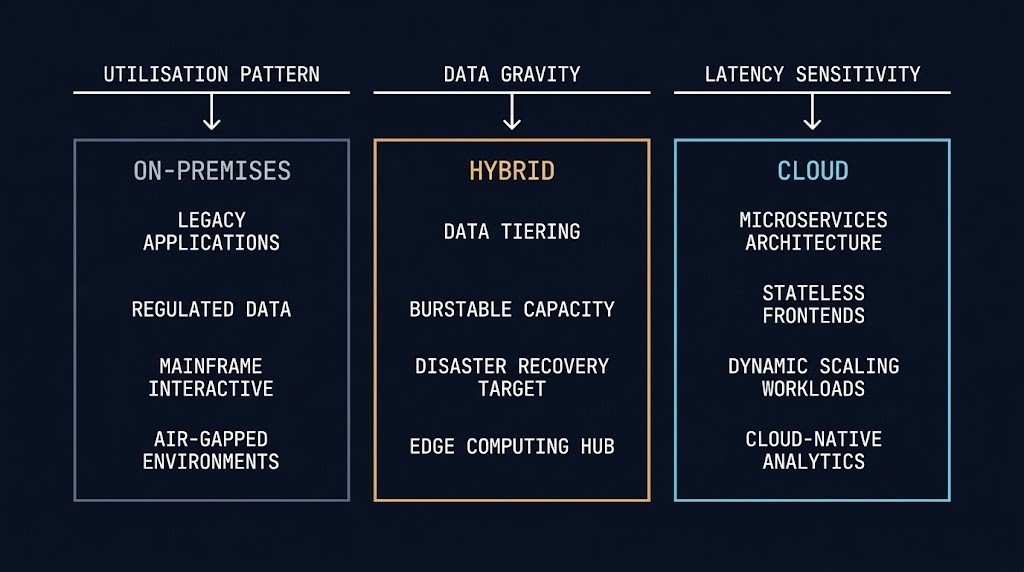
- Burstable workloads with unpredictable peak demand
- Dev/test environments with irregular utilisation cycles
- Event-driven processing (Lambda, Cloud Functions, Azure Functions)
- Global-reach applications requiring multi-region presence
- AI/ML training runs with GPU burst requirements
- SaaS-adjacent integrations requiring managed service proximity
- Disaster recovery targets and cold standby capacity
- Regulated workloads with data residency requirements
- Line-of-business applications with predictable, steady utilisation
- Workloads with high egress ratios (large outbound data volumes)
- Latency-sensitive applications requiring sub-5ms consistency
- Workloads dependent on legacy integration or on-premises datasets
- Steady-state high-utilisation workloads running 24/7 at 70%+ load
- High-volume data processing with large egress footprint
- AI inference workloads once monthly bill exceeds CapEx threshold
- Workloads requiring hardware-specific compliance controls
- Sovereign infrastructure requirements with strict jurisdictional boundaries
The data gravity argument is critical and underweighted in most cloud migration discussions. When compute moves to cloud but the source-of-truth datasets remain on-premises, you have not escaped data gravity — you have added a latency and egress bill to it. The Law of Data Gravity covers this in full.
The Hybrid vs Multi-Cloud in 2025 analysis maps what hybrid and multi-cloud actually look like operationally — not the marketing diagram, but the IAM fragmentation, the network bridging complexity, and the governance overhead that accompany real hybrid deployments.
For the repatriation decision specifically — which workloads should never leave, which should come back, and how to model the economic break-even — two dedicated posts cover the full framework: Workloads That Should Never Leave The Cloud and Cloud Repatriation: When to Move Workloads On-Prem.
Decision Framework
Platform placement decisions should follow workload physics, not provider relationships.
The table below maps workload profile to recommended platform. It is not exhaustive — edge cases and sovereign requirements will override these defaults — but it reflects the dominant placement logic for enterprise cloud architecture decisions.
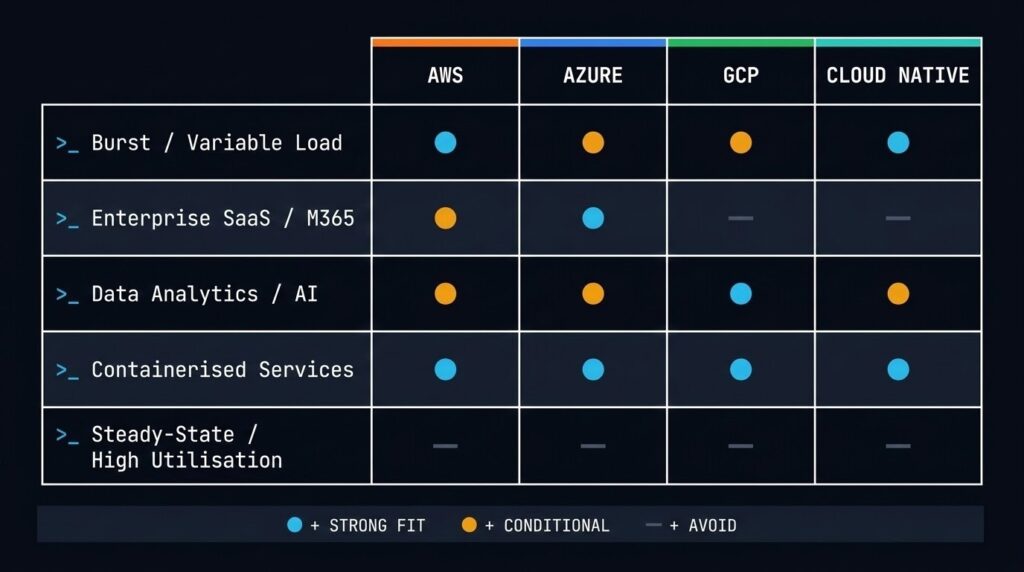
| Workload Profile | Primary Signal | Recommended Platform | Risk Flag |
|---|---|---|---|
| Burstable web / app tier | Unpredictable peak demand | AWS / Azure / GCP | Right-size reservations or costs spike |
| Event-driven / serverless | Scale-to-zero requirement | AWS Lambda / GCP Cloud Run / Azure Flex | Cold start physics — model before committing |
| AI/ML training (burst) | GPU burst, short run duration | GCP / AWS (P-class) / Azure (ND-series) | Repatriate once monthly bill > CapEx threshold |
| Enterprise SaaS / M365-adjacent | Entra ID dependency | Azure (Landing Zone) | Identity lock-in — scope governance early |
| Data analytics / AI pipelines | High data processing volume | GCP (BigQuery / Cloud Storage) | Near-zero egress only within GCP fabric |
| Containerised microservices | Provider-agnostic workload | Cloud Native — any provider | Day-2 ops complexity — see K8s series |
| Steady-state high-utilisation | 70%+ load, predictable pattern | On-premises / HCI (repatriation candidate) | Model CapEx vs reserved instance break-even |
| Sovereign / regulated data | Jurisdictional boundary requirements | Sovereign-region cloud or private cloud | Verify provider sovereignty claims — not all regions qualify |
The AWS Control Tower vs Azure Landing Zone deep dive maps governance architecture differences for teams operating across both providers. For multi-cloud networking dependencies and the vendor lock-in that happens through connectivity rather than APIs, see Vendor Lock-In Happens Through Networking.
Cloud Architecture Tools
Cost decisions need numbers, not estimates.
The tools below are built for the specific failure modes covered in this pillar: egress exposure, private endpoint misconfigurations, and serverless refactoring break-even. Each one produces a deterministic output from your actual architecture inputs.
You’ve Mapped the Domains.
Now Choose Your Path.
AWS, Azure, GCP, Cloud Native — the architecture is clear. The harder question is what the right placement model looks like for your specific workload profile, team capability, and cost constraints. That conversation is where architecture decisions actually get made.
Cloud Architecture Audit
Vendor-agnostic review across AWS, Azure, GCP, and Cloud Native for your specific workload profile, team capability, and 5-year cost model. No preferred platform. The right answer for your environment — not the right answer in general.
- > Workload classification and platform placement
- > 5-year TCO model across cloud and on-prem options
- > Egress exposure and repatriation break-even analysis
- > Platform recommendation with migration runway
Architecture Playbooks. Every Week.
Field-tested blueprints covering every domain this page maps — egress physics, landing zone failures, workload repatriation decisions, and cloud-native Day-2 operations from real enterprise environments. No vendor marketing. Just the architecture depth your team needs.
- > Cloud Cost & Egress Physics
- > Workload Placement & Repatriation Analysis
- > Landing Zone & Governance Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is the difference between cloud strategy and cloud migration?
A: Cloud migration is a project. Cloud strategy is the architecture that governs where workloads live, how they communicate, how they scale, and how they fail. Migration without strategy is the fastest route to a bill that exceeds your on-premises cost within 18 months.
Q: How do I decide whether a workload belongs in cloud or on-premises?
A: Three variables drive the decision: utilisation pattern (burstable vs steady-state), data gravity (where the source-of-truth datasets live), and latency sensitivity (sub-5ms requirements cannot tolerate cloud network variance). Steady-state workloads running at 70%+ load 24/7 are typically repatriation candidates once the reserved instance break-even is modelled.
Q: What is cloud repatriation and when does it make sense?
A: Repatriation is the process of moving workloads from public cloud back to on-premises or private cloud infrastructure. It makes sense when the unit economics of cloud no longer justify the operational overhead — typically for high-utilisation steady-state workloads, AI inference workloads where monthly GPU spend exceeds CapEx threshold, or workloads with large outbound data volumes generating sustained egress charges.
Q: What is data gravity and why does it matter for cloud architecture?
A: Data gravity is the tendency for compute and services to accumulate around large datasets — because moving data is expensive and slow. When your source-of-truth datasets are on-premises, placing compute in cloud adds latency and egress cost without eliminating the on-premises dependency. Cloud strategy must account for where data lives before deciding where compute should run.
Q: What is the difference between hybrid cloud and multi-cloud?
A: Hybrid cloud integrates on-premises and cloud environments with shared identity, networking, and governance — workloads are placed based on fit, with seamless policy enforcement across boundaries. Multi-cloud is operating across multiple public cloud providers simultaneously, typically to use best-of-breed services rather than to achieve workload portability. In 2026, true workload mobility between providers remains largely theoretical — data gravity and platform specificity prevent it at enterprise scale.
Q: How does Cloud Native differ from cloud provider architecture?
A: Cloud Native refers to the application delivery layer — Kubernetes orchestration, containerised microservices, serverless functions — that can run on any provider or on-premises. Cloud provider architecture refers to the platform-specific infrastructure patterns of AWS, Azure, and GCP. Cloud Native workloads are designed to be provider-agnostic by default, though in practice they accumulate managed service dependencies that reduce portability.
The cloud strategy decision is the architectural frame. The pages below are the execution layers — pick the path that matches your environment.