The Disconnected Brain: Why Cloud-Dependent AI is an Architectural Liability
This is Part 2 of the Rack2Cloud AI Infrastructure Series.
Catch up on Part 1: TPU Logic for Architects: When to Choose Accelerated Compute Over Traditional CPUs.
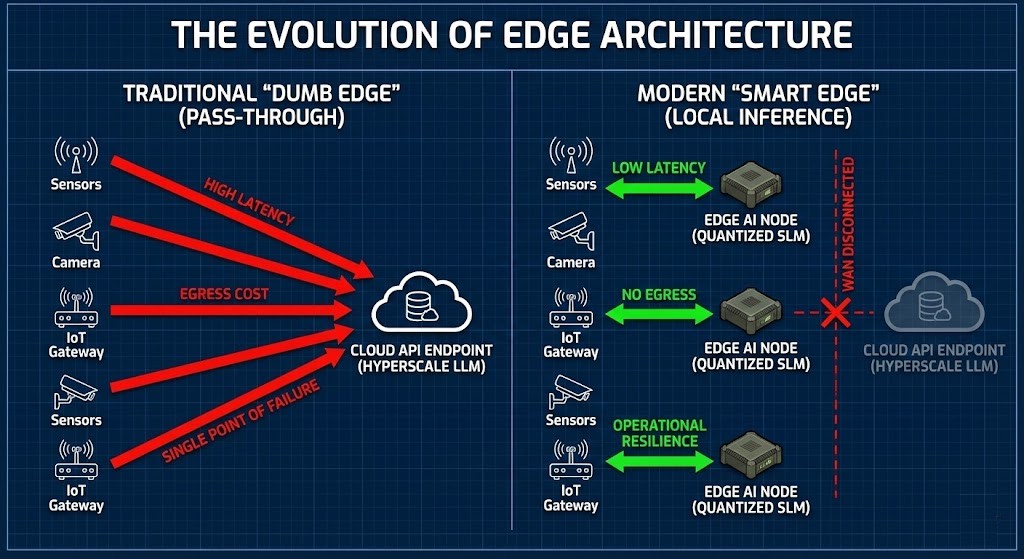
For years now, we’ve been told to build “Pass-through edges” when it comes to cloud architecture. The playbook went like this: toss a bunch of cheap sensors, cameras, or gateways out on the edge, then pipe all that data back to the cloud for heavy lifting. Easy enough.
Then Generative AI showed up, and honestly, we didn’t rethink much. We just kept stacking bigger models—100-billion parameter LLMs—in giant data centers and set up some API endpoints. In the lab, streaming half a gigabyte per second of video from thousands of sensors straight to the cloud looks pretty slick. Everything’s centralized, neat, easy to control.
But then, the WAN jitter jumps 200 milliseconds, and that whole fantasy falls apart.
The Tension: Reality Doesn’t Care About Your Diagram
Trusting a cloud API assumes the network is always there, always fast, and always free. It’s not. The cloud turns into a single, very fragile point of failure for any operational AI.
Step outside your air-conditioned office and into places where physics—or government rules—call the shots, and the “Pass-through edges” plan just breaks. You can’t rely on the cloud to run a robot line in a factory. You can’t wait for cloud inference when your oil rig is stuck on a satellite link. And you definitely can’t expect a defense drone in a hostile, disconnected zone to phone home for decisions.
When the cloud goes dark, your AI goes with it.
The Failure Story: That $150,000 Glitch
Picture a car factory rolling out a Generative Vision AI for quality control. During the trial, everything’s wired up: cameras send video to the cloud, the model catches every defect, and everyone’s happy.
Then production starts. A tiny ISP routing hiccup kicks WAN latency up by 200 milliseconds. Cameras still snap away at 60 frames per second, but now the cloud API times out. Even if 95% of the frames make it, that missing 5% means bad parts slip by. Suddenly, the system isn’t reliable, and the whole line stops.
Ten minutes of downtime? That’s $150,000 out the window.
The AI was flawless. The infrastructure let it down.
The Architectural Law
You can’t outrun the speed of light, and you can’t count on always being connected. Betting everything on centralized cloud compute for real-world, real-time decisions is a recipe for disaster.
If you want true resilience, you’ve got to move the brain to where the data lives—not the other way around.
Run your inference right at the edge, and you get an answer in 15 milliseconds. Ship it to the cloud and back? Now it takes 800 milliseconds. That 785-millisecond gap is the difference between smooth operations and a total mess.
The Model: Two Ways to Survive at the Edge
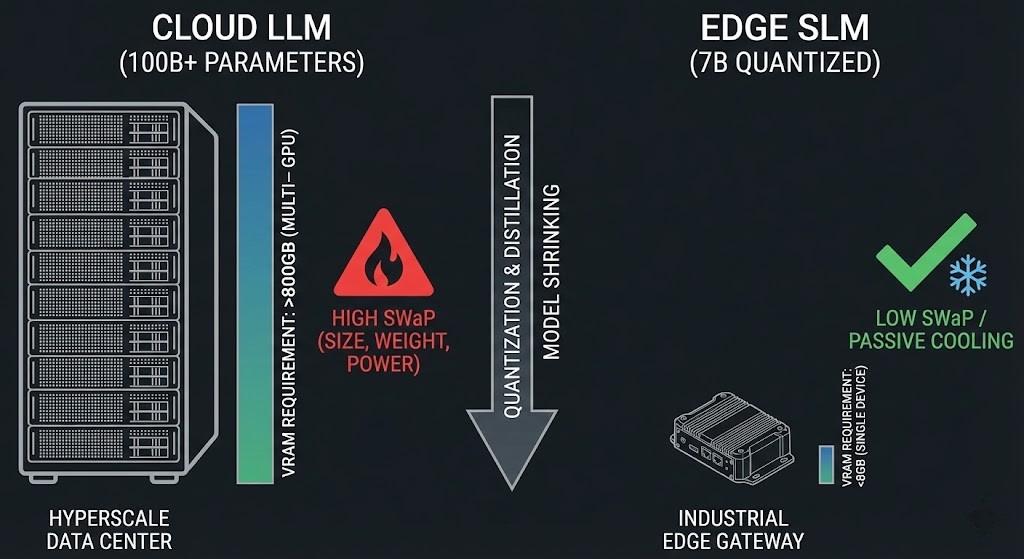
If you want to build systems that last out on the edge, you have to leave behind those giant, centralized models and move toward a tougher, more local kind of intelligence.
Cloud API Inference (The Centralized Brain)
Here, you’re working with huge language models—think GPT-4 and up, over 100 billion parameters—parked in massive data centers. You tap into them using REST APIs. But the real headache? The network. Every time you call out to the cloud, you’re at the mercy of latency, sky-high bandwidth fees, and the hope that everything stays online.
Edge Inference (The Local Brain)
Now, flip the script. This time, you’re running smaller, sharper language models—maybe 7 billion parameters, often quantized—right on local, rugged hardware. The catch? Hardware limits and keeping your fleet under control. You have to push updates to thousands of edge devices that aren’t always connected. Each node needs to squeeze as much as it can out of limited memory—usually running super-lean, 4-bit models on less than 8GB of VRAM. It’s a whole different game.
The Consequence Matrix
Translating the architecture into operational and financial outcomes:
| If X Fails / Changes | Cloud Inference Result | Edge Inference Result | Cost Impact |
| WAN Connectivity Drops | Total system halt; API times out. | Operates normally; zero impact. | Averts $X,000s in downtime per minute. |
| Data Sovereignty Mandate | Data leaves the perimeter (High Risk). | Data never leaves the sensor (Secure). | Eliminates compliance/audit fines. |
| Model Requires Update | Instant, centralized API update. | Requires complex local fleet orchestration. | Increases IaC and DevOps overhead. |
| Continuous Video/Telemetry | Chokes network; massive ingress. | Microsecond response; local discarding. | Saves massive monthly cloud egress/ingress fees. |
The Verdict: Where Do You Want to Take Your Chances?
This isn’t just “Cloud vs. Edge.” Really, you’re deciding where your system stays in control when the network starts falling apart.
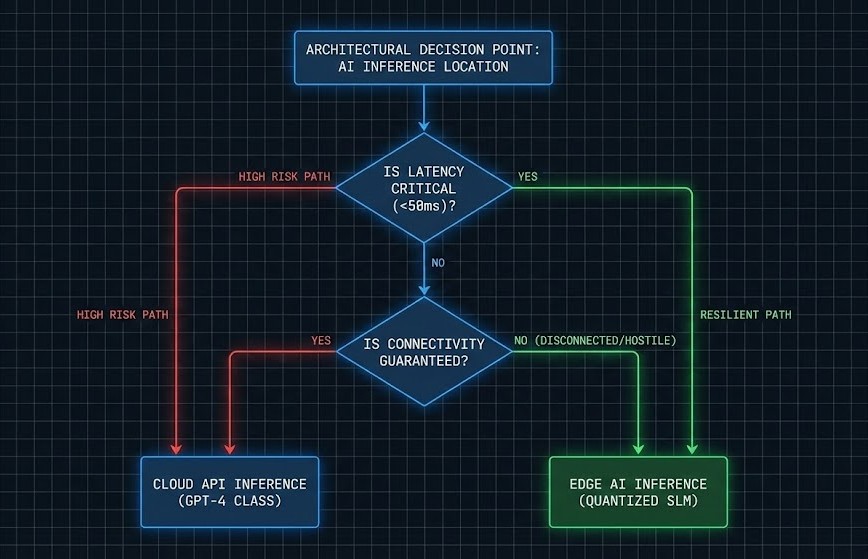
- Pick Cloud Inference when: You can live with a little lag (think chatbots or document summaries), you need those massive models to reason over your data, and your WAN connection is rock solid.
- Go with Edge Inference when: Every millisecond counts, you’re dealing with spotty or hostile environments, or sending sensor data offsite isn’t even legal.
Edge AI doesn’t push the cloud aside. It steps in when the cloud drops out.
Rack2Cloud Alignment
Running inference right where you collect data shakes up your entire tech stack.
- Data Gravity: Edge AI tackles the heavy lifting of data right at the source. Instead of burning cash on egress fees just to ship mountains of raw video to the cloud, as we outlined in our AI Infrastructure Strategy Guide, you handle it locally and only send up the slimmed-down metadata.
- Compute Architecture: Edge inference calls for local gear, usually with some serious acceleration. The thinking we laid out in TPU Logic for Architects fits here—it just happens on a much smaller scale.
- Sovereignty: When your data isn’t allowed to cross the fence, Edge AI links up perfectly with the isolation strategies we covered in our Rubrik vs. Veeam Sovereign Estate analysis.
- Fleet Management: Pushing updates to thousands of sensors that might never phone home demands real discipline. You need a rock-solid Modern Infrastructure & IaC foundation, or you’ll drown in configuration drift.
The Architect’s Bottom Line
Real resilience isn’t about how fast your edge can talk to the cloud. It’s about how well it can keep going when the cloud’s gone. The architects who nail disconnected, resilient edges today are the ones who’ll pull off real-time generative AI tomorrow.
External References for the Edge Architect
- Hugging Face Quantization Guide: The mathematical foundation of shrinking large models (8-bit and 4-bit quantization) to fit onto ruggedized edge hardware.
- NVIDIA Edge Computing Architecture: Reference designs for deploying accelerated compute outside the data center.
- NIST SP 800-213 (IoT Device Cybersecurity): Federal standards for securing disconnected and edge-deployed sensors.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
This architectural deep-dive contains affiliate links to hardware and software tools validated in our lab. If you make a purchase through these links, we may earn a commission at no additional cost to you. This support allows us to maintain our independent testing environment and continue producing ad-free strategic research. See our Full Policy.