Autonomous Systems Don’t Fail. They Drift Until They Break.
Autonomous systems drift before they fail. Software fails loudly. A service crashes. An API returns 500. A pod restarts. The alert fires. You respond.
Autonomous systems don’t work that way.
They degrade quietly. They drift. They accumulate small deviations — a few extra tokens here, one more model call there, a retry loop that fires slightly more often than it should. None of it triggers an alert. None of it looks wrong in isolation. And then one morning your inference bill is double what it was last quarter, your latency has crept from 200ms to 800ms, and nobody can point to the commit that caused it.
Because there wasn’t one.
Drift doesn’t trigger alerts. It triggers your quarterly bill.
Picture three systems running in production right now:
A recommendation engine that started making one model call per user request. Six weeks later it’s making 1.4 — because a retrieval step was added to “improve accuracy” and nobody removed the fallback path.
A retrieval pipeline that was designed to fetch three context chunks. It now fetches five, because someone bumped the top_k parameter during a quality review and the default was never reset.
An agent that was built to retry failed tool calls once. It now retries twice — because an engineer added a second retry “just to be safe” during an incident, and the change shipped quietly in a config update.
Nothing broke. No alerts fired. No incidents were declared.
Until the cost doubled.
And when you go looking for the cause, you won’t find a single breaking change. You’ll find three reasonable decisions made by three different engineers, none of whom knew what the others had done.
That’s drift.
Autonomous Systems Drift vs Failure — Why the Distinction Matters
When a system fails, the feedback loop is immediate. Something breaks, you fix it, you move on. The blast radius is bounded by the incident.
When a system drifts, the feedback loop is broken by design. The system keeps working. It keeps producing outputs that look correct. It keeps passing your health checks. The only signal is in the numbers — and only if you’re watching the right numbers at the right granularity.
Most teams aren’t.
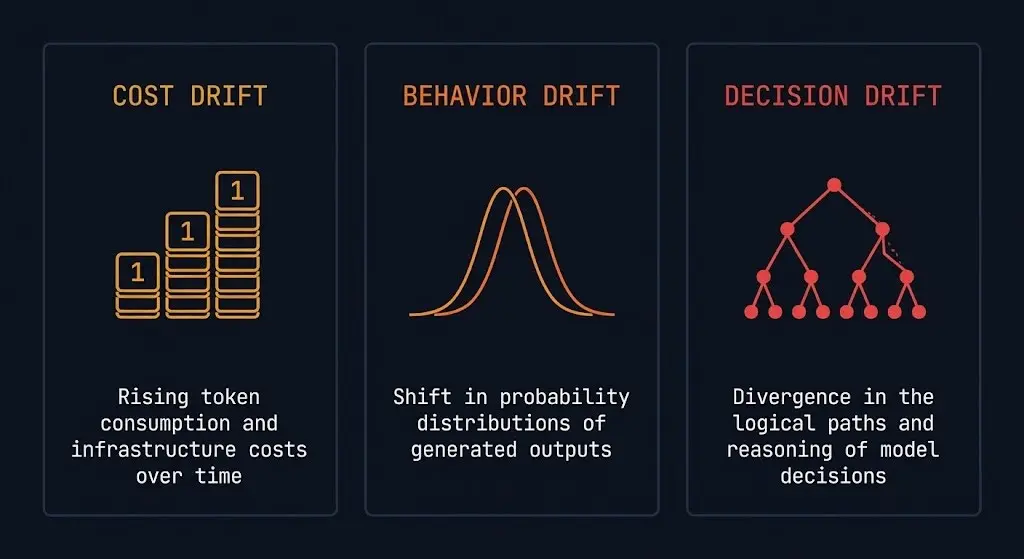
There are three categories of drift that matter in autonomous AI systems:
Cost drift is the most visible — eventually. Token consumption creeps up. Model call counts increase. Retrieval costs compound. The signal is in your cloud bill, which most engineers don’t see in real time and most FinOps teams don’t understand at the model level. The full cost architecture is mapped in the AI Infrastructure strategy guide.
Behavior drift is harder. The system’s outputs change in ways that are subtle enough to pass automated quality checks but meaningful enough to affect user experience. A recommendation system that slightly over-indexes on engagement signals. A summarization pipeline that gets progressively more verbose. A classifier that shifts its confidence threshold over time.
Decision drift is the most dangerous and the least discussed. Autonomous agents make sequences of decisions. When the parameters that govern those decisions shift — context window utilization, retry logic, tool selection heuristics — the downstream consequences compound across every subsequent decision in the chain. The agent isn’t broken. It’s just making subtly different choices than it was designed to make. When that shift originates from what’s reaching the model — not from internal config changes — you’re looking at a boundary enforcement problem, not a drift problem. That’s the gap Kubernetes Is Not an LLM Security Boundary covers.
Why Monitoring Doesn’t Catch It
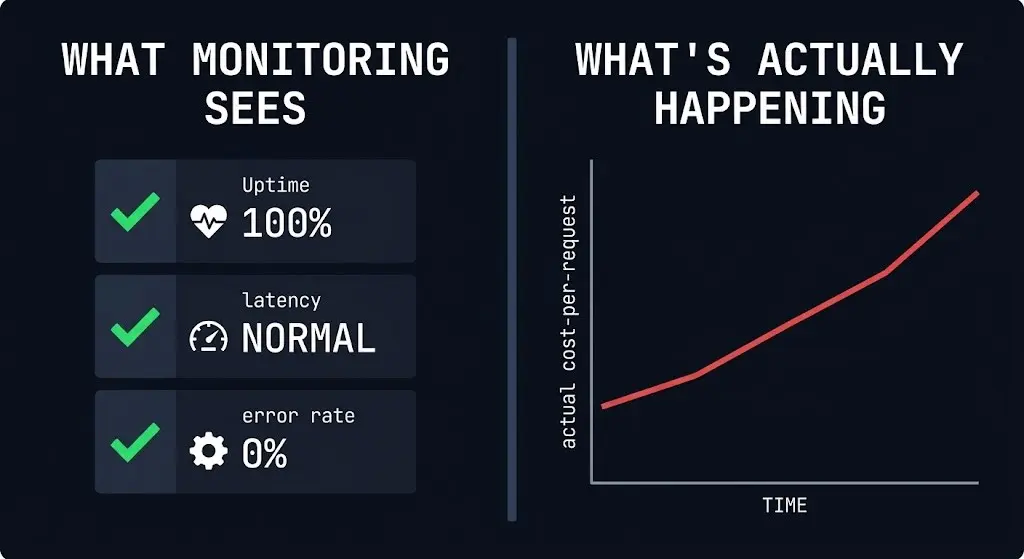
Standard monitoring is built for failure detection, not drift detection. The instrumentation most teams have in place answers: Is the system up? Is it responding? Is latency within SLA?
None of those questions catch drift.
Drift detection requires different instrumentation entirely:
- Per-request token consumption tracked over time, not just in aggregate
- Model call counts per workflow, not just total API spend
- Retry rate trends by agent and by tool
- Context utilization percentages across request cohorts
- Output characteristic distributions — length, confidence scores, retrieval chunk counts
Most teams don’t have this instrumentation. And even the teams that do often aggregate it at the wrong level — total spend per day instead of cost per request per workflow, which hides the drift signal inside volume noise.
If your inference spend went up 40% last month and your traffic went up 30%, most teams would call that normal scaling. It might be drift.
Why FinOps Doesn’t Control It
Traditional FinOps was built for a world of predictable infrastructure costs. Reserved instances. Savings plans. Right-sizing compute. The model was: provision resources, measure utilization, optimize allocation.
AI inference breaks that model completely.
The cost driver isn’t resource allocation — it’s behavior. How many tokens your agent consumes depends on what it decides to do, which depends on the context it receives, which depends on the retrieval configuration, which depends on parameters that engineers change without thinking of them as cost controls.
A FinOps team looking at your inference spend sees a number going up. They can’t tell you whether it’s because traffic increased, because someone changed max_tokens, because your RAG pipeline is fetching more chunks, or because your retry logic is firing twice as often. That distinction requires instrumentation at the workflow level, not the billing level.
This is the gap that execution budgets fill. Not as a cost-cutting measure — as an architectural constraint that makes drift visible before it becomes a crisis. Operational visibility at the workflow level — the instrumentation that surfaces drift as a signal rather than a billing anomaly — is the domain of Operations & LLMOps Architecture. That stage covers the observability and LLMOps governance layer where drift detection has to live.
The Architecture Implication
Autonomous systems need runtime constraints built into the architecture from day one — not added after the bill arrives.
An execution budget isn’t a spending limit. It’s a contract between the system and the infrastructure it runs on. It says: this workflow is allowed to consume X tokens, make Y model calls, and retry Z times. Anything outside those bounds is a signal that something has changed — either intentionally, in which case the budget should be updated explicitly, or unintentionally, in which case you’ve just caught drift before it compounded.
Without that contract, drift is invisible until it’s expensive. With it, every deviation from expected behavior surfaces as a measurable event rather than a mystery you investigate after the quarterly bill. The cluster and scheduling layer is where enforcement contracts become structurally enforceable. Placement policy, admission controls, and resource quotas are the architectural primitives that make those contracts binding — covered in the Runtime & Cluster Orchestration stage of the AI Architecture Learning Path.
The teams that will win on AI infrastructure cost are not the ones with the best FinOps dashboards. They’re the ones that designed their systems so that drift can’t hide. If you’re building that foundation from scratch, the AI Architecture Learning Path maps the full sequenced reading order.
Architect’s Verdict
Autonomous systems don’t announce when they’ve gone wrong. They keep running, keep producing output, keep passing health checks — while quietly consuming more than they should, deciding differently than they were designed to, and compounding those deviations across every request in the queue.
The failure mode isn’t a crash. It’s a slow accumulation of reasonable decisions that nobody reviewed together.
The architectural response isn’t better monitoring after the fact. It’s enforcement at runtime — execution budgets, call count constraints, retry limits, and token ceilings that make drift structurally impossible to hide.
Build the constraints in from day one, or spend quarter-end explaining why the bill doubled.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session