Kubernetes Requests vs Limits: The Scheduler Guarantees One Thing. The Kernel Enforces Another.
You set requests. You set limits. The pod still gets throttled — or killed. Not because Kubernetes is broken. Because most teams have the wrong mental model of what these two fields actually do.
When you configure kubernetes resource requests vs limits, the assumption is a simple min/max pair — requests reserve resources, limits cap them. That framing is intuitive. It is also wrong in ways that matter. Requests and limits operate at two completely different layers of the stack, enforced by two completely different systems, under two completely different conditions. Getting that distinction wrong is how production workloads develop latency problems nobody can explain, and how memory-hungry containers disappear without warning at 3am.
This post breaks down what actually happens — at the scheduler, at the kubelet, and at the kernel — and maps the failure modes that follow when the configuration doesn’t match the workload.
Kubernetes Resource Requests vs Limits: The Mental Model Most Teams Are Running
Most engineers treat resource requests and limits as a simple min/max pair. Requests are what the pod reserves. Limits are the maximum it can use. That framing is intuitive. It is also wrong in ways that matter.
Requests are not reservations in the traditional sense. Setting a request of 500m CPU does not mean 500 millicores are held exclusively for that pod on the node. It means the scheduler will only place the pod on a node where 500m CPU is available in its accounting ledger — whether or not that capacity is actually idle. The node can be under real CPU pressure while the scheduler considers it eligible. The request is a placement signal, not a performance guarantee.
Limits are not maximums in the traditional sense either. For CPU, a limit is a throttle ceiling enforced by cgroups — the pod continues running, just slower. For memory, a limit is a hard wall enforced by the kernel’s OOM killer — the container is terminated when it crosses the line. These are not equivalent behaviors. One degrades silently. The other kills without warning.
Here is the thesis that the rest of this post proves: requests and limits are not resource settings. They are scheduling signals and runtime failure triggers. The scheduler uses one. The kernel enforces the other. And they never interact.
Two Layers, Two Systems, Zero Coordination
The confusion about requests and limits comes from treating the Kubernetes control plane as a single system. It isn’t. Placement and enforcement are handled by different components with different information and different responsibilities.
Ignores: limits entirely
Enforces: at runtime under pressure
The scheduler runs once at pod creation time. It looks at pending pods, evaluates node capacity against resource requests, and makes a placement decision. After that, the scheduler is done. It does not monitor the pod. It does not intervene if the node becomes overloaded. It does not know what limits are set.
The kubelet runs continuously on every node. It monitors container resource usage against configured limits and works with the kernel’s cgroup subsystem to enforce those limits at runtime. The kubelet does not know what the scheduler decided. It does not factor requests into its enforcement logic. It watches usage against limits and reacts when thresholds are crossed.
These two systems share no state. A pod can be perfectly placed by the scheduler — requests satisfied, node capacity adequate — and still be throttled or killed at runtime because the limit configuration doesn’t match the workload’s actual behavior. The placement was correct. The enforcement was correct. The configuration was wrong.
CPU vs Memory: The Critical Difference
CPU and memory are both resource types in Kubernetes, but they are not equivalent from an enforcement standpoint. The distinction matters more than most documentation makes clear.
CPU is a compressible resource. When a container exceeds its CPU limit, the kernel throttles it via cgroups — reducing the time slices allocated to that container’s processes. The container keeps running. The application keeps executing. But it runs slower, and the slowdown can be severe enough to cause latency spikes that look like application bugs rather than infrastructure constraints. CPU failures are silent. They degrade performance without generating obvious error signals. A container hitting its CPU limit produces no log entry, no Kubernetes event, no OOMKilled status. It just gets slower.
Memory is a non-compressible resource. There is no way to throttle memory usage the way CPU usage is throttled. When a container exceeds its memory limit, the kernel’s OOM killer terminates the process. The container exits. Kubernetes records the OOMKilled status. The pod restarts if its restart policy allows. Memory failures are hard and immediate. The application does not slow down first — it disappears.
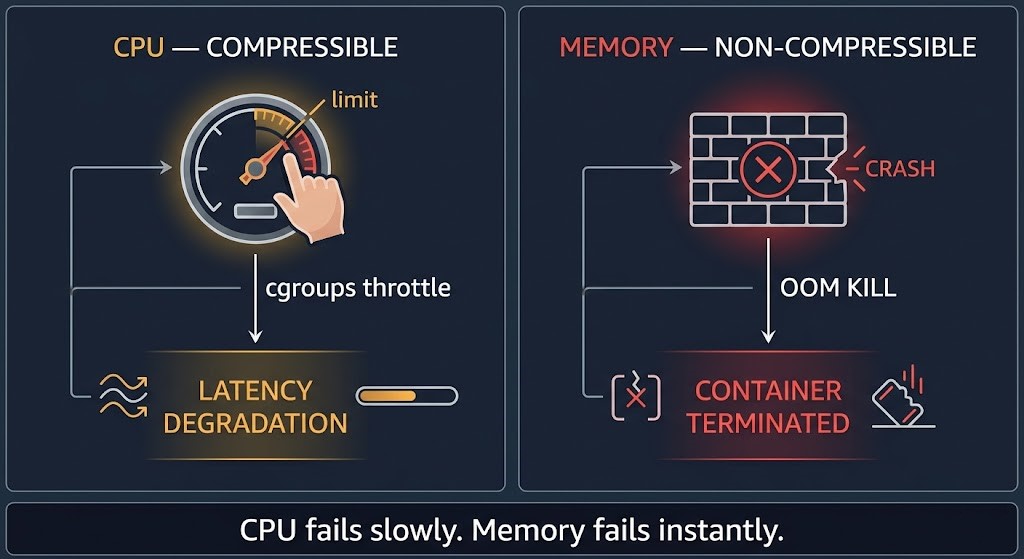
This distinction drives different configuration strategies. CPU limits can be set conservatively and tuned upward as latency data accumulates — the failure mode is observable. Memory limits require more careful initial sizing because the failure mode is binary. A container that routinely approaches its memory limit is one memory allocation away from termination. Tools like the Vertical Pod Autoscaler in production exist precisely because right-sizing memory limits is an ongoing operational problem, not a one-time configuration decision.
QoS Classes: What They Are and What They Actually Control
Kubernetes assigns every pod a Quality of Service class based on how requests and limits are configured. This isn’t just a label — it directly controls eviction priority when a node comes under memory pressure. Most documentation treats QoS as a classification system. It’s better understood as a failure sequencing system.

The practical implication is that QoS class is determined by your configuration choices, not by explicit assignment. A team that skips requests and limits thinking they’re simplifying the configuration has actually placed their pods at maximum eviction risk. Under node memory pressure, the kubelet evicts BestEffort pods first, then Burstable pods sorted by how far their usage exceeds requests, then Guaranteed pods as a last resort. The ordering is deterministic. The decision was made at configuration time, not at eviction time.
The VPA vs HPA decision intersects directly with QoS: VPA adjusts requests to match actual usage, which directly affects QoS class assignment and eviction risk. Autoscaling decisions and resource configuration decisions are not independent.
Where It Breaks: The Four Failure Patterns
Most Kubernetes resource failures trace back to four configuration patterns. None of them are bugs. All of them are predictable consequences of the two-layer model described above.
A Practical Configuration Framework
The right configuration strategy follows from the workload type and the acceptable failure mode — not from a universal rule about always setting requests equal to limits or always allowing burst headroom.
For latency-sensitive and stateful workloads — databases, cache layers, critical API services — set requests equal to limits to achieve Guaranteed QoS. The resource overhead is real but the eviction protection and performance predictability justify it. These workloads cannot absorb the behavior variability that comes with Burstable class.
For variable workloads with bursty patterns — batch processors, CI runners, event-driven consumers — allow requests to be lower than limits to achieve Burstable QoS. This enables the workload to use spare node capacity during spikes without holding resources during idle periods. Size requests from observed steady-state usage, not peak. Size limits from observed peak with a safety margin.
Never skip requests. There is no valid production argument for BestEffort class on workloads that matter. Skipping requests doesn’t save resources — it removes scheduler visibility and places the pod at maximum eviction risk. The apparent simplicity of omitting configuration fields is hiding a decision: you’ve chosen unpredictable placement and first-eviction priority. See the Kubernetes cluster orchestration guide for how request configuration fits into broader cluster capacity planning.
For ongoing right-sizing, the operational model matters as much as the initial configuration. Static limits set at deployment time drift from reality as workloads evolve. The VPA in-place resize capability addresses this directly — adjusting requests without pod restarts for supported workloads. The Kubernetes Day-2 failure patterns that emerge from static configurations are well-documented and largely preventable with active resource management.
Architect’s Verdict
Requests and limits are not a resource reservation system. They are a two-layer signaling and enforcement model where the scheduler and the kernel operate independently, with no shared state and no coordination between placement and runtime behavior.
CPU fails slowly through throttle. Memory fails instantly through OOM kill. QoS class determines eviction order under pressure. None of these behaviors are accidents or edge cases — they are the designed behavior of a system built to run workloads at scale across heterogeneous nodes. The teams that understand this model configure for it deliberately. The teams that treat requests and limits as a min/max resource pair discover the difference during incidents.
Set requests from observed steady-state usage. Set memory limits with enough headroom to absorb peak behavior. Set CPU limits understanding that the failure mode is latency, not termination. Match QoS class to workload criticality. And revisit the configuration as the workload evolves — because static limits on dynamic workloads is where most of the production incidents in this space actually originate.
Resource configuration at the workload level is the foundational input to everything above it in the scheduling stack — and the scheduling stack is an authority execution system. Which system is permitted to resize a workload, under what conditions, and whether that was an explicit architectural decision or an inherited default is the question Autoscaling Is an Authority System, Not a Capacity System answers.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session