The Retry Storm Is a Self-Inflicted DDoS

THE RECOVERY ENGINEERING SERIES
A downstream dependency degrades for ninety seconds. Your monitoring catches it. Your on-call rotation catches it. The dependency recovers. Your dashboards turn green. And your platform stays down for another forty minutes.
This is not a monitoring failure. It is not a missed alert. It is the moment ten thousand clients — each one quietly retrying for ninety seconds with the same exponential backoff and no jitter — hit the recovering service simultaneously. The first wave crushes it. The second wave crushes the recovery. By the time anyone realizes what is happening, the original fault is irrelevant. The retry logic is the outage.
A retry storm is what happens when recovery becomes a denial-of-service event against your own infrastructure. It is one of the most common architecture failure modes in distributed systems and one of the most consistently misdiagnosed. Teams treat the secondary collapse as a new incident. It is not a new incident. It is the first incident finishing what it started — using your own client logic as the weapon.
What a Retry Storm Actually Is
A retry storm is a self-amplifying traffic surge generated by client-side recovery logic responding to a transient failure. The shape is consistent across every distributed system that has experienced one: a brief degradation creates a backlog of failed requests, every client independently retries, the retries stack against a service whose capacity assumptions did not include simultaneous reconnect from its entire client population, and the recovery itself becomes the failure event.
The math is simple enough to be deceptive. Ten thousand clients running a default SDK retry policy of five attempts produces fifty thousand requests in the first second of recovery — not the fifty thousand requests per second the service was sized for, but fifty thousand requests in a single tick, against a service whose connection pools, thread pools, and downstream dependencies were sized for steady-state traffic. The capacity number that mattered was never peak QPS. It was peak <em>simultaneous</em> reconnect, and almost no one models for it.
This pattern is invisible during normal operations. The retry logic is doing exactly what it was written to do. The clients are doing exactly what their SDKs do by default. The service is recovering on schedule. And yet the system fails — because the failure mode lives between the components, in the timing assumptions that nobody owns. This is the same category of architectural fragility that produces silent Kubernetes Day-2 failures — the kind that traditional monitoring is structurally incapable of catching.
Why Retries Become Traffic Amplifiers
Retries are not a bug. They are a deliberate resilience pattern that compensates for transient network failures, brief service hiccups, and the natural noise of distributed communication. The problem is not that retries exist. The problem is that retry logic is written by individual teams, in individual services, with no awareness of the retry logic running everywhere else in the call chain. Each layer adds a multiplier. The system’s true retry behavior is the product, not the sum.
Three architectural patterns turn retries from resilience into amplification. They almost always appear together, which is why retry storms feel inevitable once they begin.
Thousands of clients fail at the same wall-clock moment, then retry on the same timer. Without jitter, every retry attempt becomes a coordinated wave hitting the recovering service at exactly the same instant.
A single user request can trigger retries at the SDK, mesh, gateway, application, ORM, connection pool, and job queue layers — each unaware of the others. One user click becomes six requests against the failing service.
Most retry policies cap attempts per request but have no system-wide budget. The service can be degraded, the dependency saturated, the recovery actively in progress — and clients keep firing because no signal exists to make them stop.
Exponential backoff is sometimes proposed as the answer. It is not. Pure exponential backoff without jitter does not disperse retries — it synchronizes them onto predictable wave fronts. Every client failing at T=0 retries at T=1s, then T=2s, then T=4s. Each wave hits the service at exactly the same time. The third wave is usually the one that takes the recovery down, because by T=4s the service has begun accepting connections again and now has to absorb the entire stacked queue at once.
The fix is not backoff alone. It is backoff with jitter — ideally decorrelated jitter, where each retry interval is randomized within a bounded range derived from the previous interval. This converts the synchronized wave into a smooth distribution of retry attempts across a window. The math is unglamorous and the implementation is trivial. The reason it is so frequently absent is that nobody owns retry policy as an architecture concern. Each team writes their own loop, copies a pattern from a stale blog post, and ships. Multiply that across a service mesh with hundreds of services and the retry behavior of your platform is whatever the median engineer wrote in 2021.
Where the Storm Forms
The retry layers in a modern distributed system are not a single decision. They are a stack of independently configured policies, each one written at a different time by a different team for a different reason. Most teams cannot enumerate them on demand. The first useful exercise in any retry storm investigation is to write the layers down — because the storm forms wherever the layers compound without coordination.
| Layer | Retry Source | Storm Risk |
|---|---|---|
| Client SDK | Built-in retries — often hidden defaults in vendor SDKs | HIGH |
| Service mesh / sidecar | Envoy or Istio retry policy at the proxy layer | HIGH |
| API gateway | Gateway-level retry on 5xx responses | MED |
| Application code | Manual try/catch retry loops written per-service | HIGH |
| Database / connection pool | ORM retries plus connection pool reconnect logic | HIGH |
| Background job queue | Job framework retry policy (Sidekiq, Celery, BullMQ) | MED |
A single user request can produce six retry attempts across stacked layers — each one unaware of the others. The database layer is the one most teams underestimate. App code retries the failed query, the ORM retries inside the driver, the connection pool reconnects, and the pool itself retries the reconnect — four retries fired into a single degraded database from one transaction. Multiply by every active connection in the pool, by every pod in the deployment, by every region in the failover topology, and the math becomes catastrophic before anyone has finished writing the incident channel announcement.
The mesh layer is the second-most-common amplifier. Service mesh retry policies are usually configured once at platform onboarding and never revisited. They sit in YAML that nobody re-reads, retrying transparently on behalf of services whose own application code is also retrying, transparently, on behalf of clients whose SDKs are also retrying. The policy is correct. The combination is a storm.
The Recovery Cliff
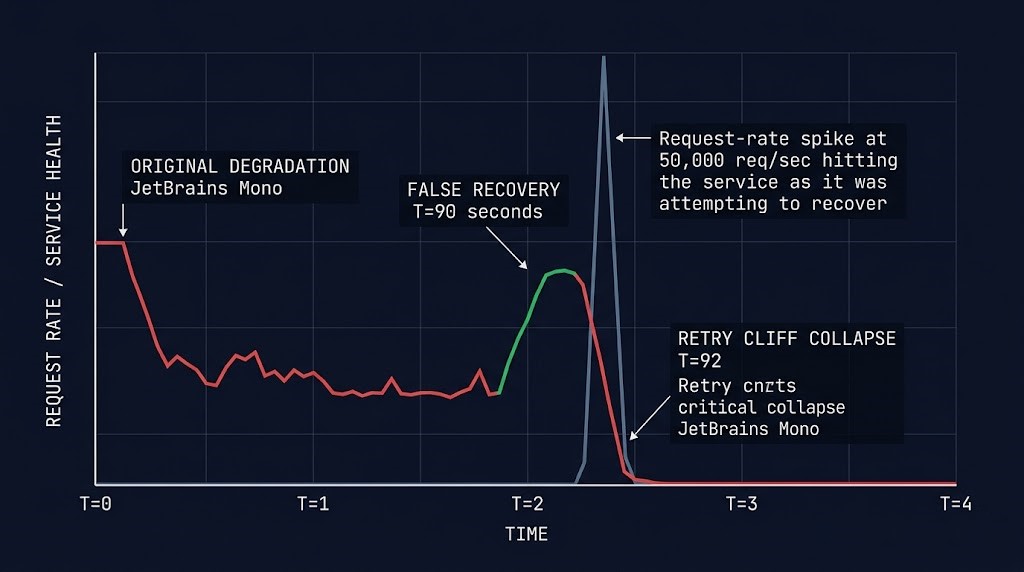
This is the moment the entire failure mode pivots on. The original dependency is back. The fault is gone. The dashboards are green. And the system is about to fail again, harder, for reasons that have nothing to do with the original problem.
When a service degrades, every client that fails begins a retry timer. Those timers run in parallel, against a wall clock, with no awareness of one another. While the service is down, the retries are absorbed by load balancer 503s, mesh-level circuit breakers, or simple connection refusals — none of which apply pressure to the service itself because the service is not accepting traffic. The retry queue grows silently, distributed across every client, every layer, every region.
Then the service recovers. The first health check passes. Load balancers reopen the pool. Connections accept. And the entire queued retry backlog — which has been growing for the duration of the outage — collides with the service in the first second of restored capacity. The service, which was sized for steady-state traffic with normal variance, now has to absorb a request volume that may be ten or twenty times its provisioned ceiling. It fails. The clients see the failure. The retry timers fire again. The cycle becomes self-sustaining.
The misdiagnosis happens at this point. The on-call engineer sees the original dependency green, the platform red, and concludes that a new failure has occurred. Triage begins from scratch. The failure is treated as unrelated to the first incident. By the time anyone identifies the secondary collapse as retry-driven, the system has been down long enough that the second outage isn’t a new incident — it is the first incident finishing what it started, using the architecture’s own recovery logic as the mechanism. This is the same class of slow-motion architectural drift that produces silent system collapse long before any single component fails outright. The cliff is invisible until you are over it.
What Stops a Retry Storm
Retry storms are stopped by retry discipline, not retry intelligence. The systems that recover cleanly are not the ones with the smartest retry logic. They are the ones that have decided, at the architecture level, that retries are a bounded resource — and have enforced those bounds at every layer where retries can originate. Five patterns, applied together, eliminate the storm.
Decorrelated jitter as the default — every retry interval randomized within a bounded range. Converts synchronized waves into a smooth distribution. The single highest-impact change you can make.
Token-bucket retry quotas per client and per service. When the budget is exhausted, retries stop voluntarily — regardless of whether the request itself completed. Bounds the worst case at design time.
Open the circuit on sustained failure. Fail fast instead of retrying. The breaker holds clients off the service long enough for actual recovery to complete before traffic returns.
Reject excess load while the service is restoring capacity, not just while it is failing. Most teams shed load during outages and stop shedding the moment the health check turns green — exactly when shedding matters most.
Services tell clients when to come back. Clients obey. The Retry-After header is a contract — and most clients ignore it because their retry libraries do not implement it. Honoring it converts an uncontrolled retry into a coordinated reconnect.
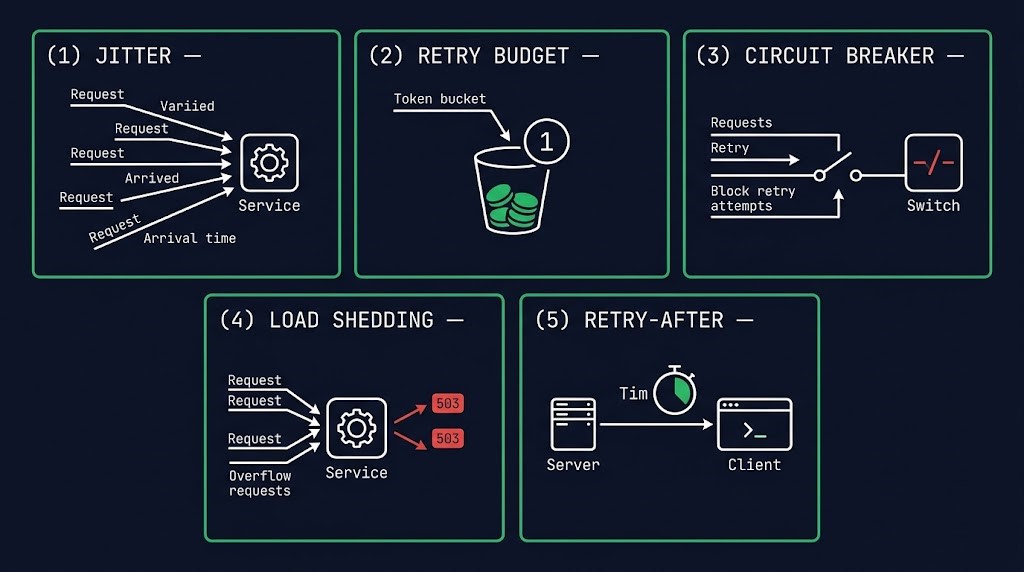
These patterns are not novel. They are well-documented and broadly available in every modern service mesh, SDK, and gateway. The reason they fail to prevent retry storms in practice is that they are applied unevenly — jitter at one layer, circuit breakers at another, retry budgets nowhere — and the layer without the discipline is the layer that produces the storm. Retry policy has to be architectural, not tactical. Anything less leaves the cliff in place.
Audit Your Stack
Most teams have three or four retry layers active in production and cannot enumerate them on demand. The first audit step is not configuration — it is enumeration. Walk the stack and write down every place a retry can originate. Order matters: the same order as a request travels. Client SDK first, then mesh, then gateway, then application, then ORM and pool, then job queue.
At the client SDK layer, look for vendor defaults. AWS SDKs use a retry_mode configuration with three modes — legacy, standard, and adaptive — and most teams have never set it explicitly. Google Cloud client libraries embed retries in the transport layer with policies that vary by service. The retries are happening; they are not visible in your application code.
At the service mesh layer, the configuration lives in VirtualService retry blocks for Istio or retry_policy blocks in Envoy listener configuration. Look at how many attempts are configured, what the per-try timeout is, and whether jitter is enabled — most defaults are not.
At the application layer, search the codebase for try/catch loops, decorator-based retry libraries (Tenacity in Python, Polly in .NET, Retry4j in Java), and feature flags governing retry behavior. These are the easiest to find and the hardest to bound, because they are written per-service and rarely follow a shared standard.
At the database and connection pool layer, inspect ORM retry settings (SQLAlchemy pool_pre_ping and reconnect behavior, Hibernate connection retry config) and the pool itself (HikariCP retry, PgBouncer reconnect logic). This is where the biggest invisible amplifier usually lives. App retries plus ORM retries plus pool reconnect retries can fire four attempts into a degraded database from one transaction without anything in your code looking suspicious.
At the job queue layer, check the framework’s default retry count, backoff strategy, and dead-letter behavior. Background jobs that retry indefinitely become the slowest, most persistent retry storm — they continue firing for hours after the original failure and quietly extend the outage envelope long after the synchronous traffic has stabilized. This is also why Mean Time to Declare matters — the longer a dependency stays degraded, the larger the retry backlog waiting to hit the recovery path. Monitoring built for steady-state operation will not show you any of this until the storm is already in progress.
Why This Breaks Recovery
Retry storms are why disaster recovery plans that worked in the runbook collapse in production. The DR sequence is correct — primary fails, traffic shifts, secondary region absorbs. The failover succeeds. Clients reconnect. Retries surge. The recovery region — sized for steady-state traffic, not for simultaneous reconnect from the entire client population — collapses under the reconnection wave. Teams misdiagnose this as a failed DR plan. It is not. The DR plan worked. The retry math didn’t. How far a system can degrade before the recovery path itself becomes structurally compromised is what The Degradation Ladder models.
This is the same architectural pattern that turns multi-region failover into a cascading outage and the same reason the restore path is the most neglected part of recovery design. Recovery is not the absence of failure. Recovery is not the absence of failure. Recovery is its own load profile. Architectures that survive their first outage are the ones that planned for the cliff — and accounted for the downstream cascade that follows when a recovery event propagates through dependent systems. That propagation pattern is what The Continuity Cascade models: the chain of second and third-order failures that begin after the primary service restores.
Architect’s Verdict
The retry storm is not a code bug. It is an architecture failure mode. It cannot be fixed by writing better retry loops in individual services because the storm is generated by the interaction of retry logic across layers — and no individual layer owns that interaction. The teams that prevent retry storms are the ones that have made retry policy a first-class architectural concern, enforced through platform standards, mesh defaults, SDK wrappers, and review practice.
If you cannot enumerate every retry source in your stack, bound each one with jitter, retry budgets, and circuit breakers, and confirm that recovery-time load shedding is actually engaged when health checks transition, your recovery path is your next outage. The system that recovers cleanly is not the one with the smartest retry logic. It is the one with the strictest retry discipline. Discipline is architectural. Smarts are not.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session