AI Workloads Break Traditional FinOps Models

The GPU cluster is idle. The inference bill doubled anyway. Nobody can explain which architectural decision caused it.
That moment — the bill that arrives without a traceable utilization event — is where traditional ai finops loses the thread. Not because FinOps teams aren’t looking. Because the cost was generated before the workload ran. The architectural decision that created the spend was made weeks earlier, by a team that never thought of it as a financial decision. By the time the invoice arrives, the cause is historical.
Traditional FinOps assumed cost followed utilization. AI infrastructure broke that assumption completely — and the industry is still catching up to what that actually means for governance.
What Traditional FinOps Was Optimizing For
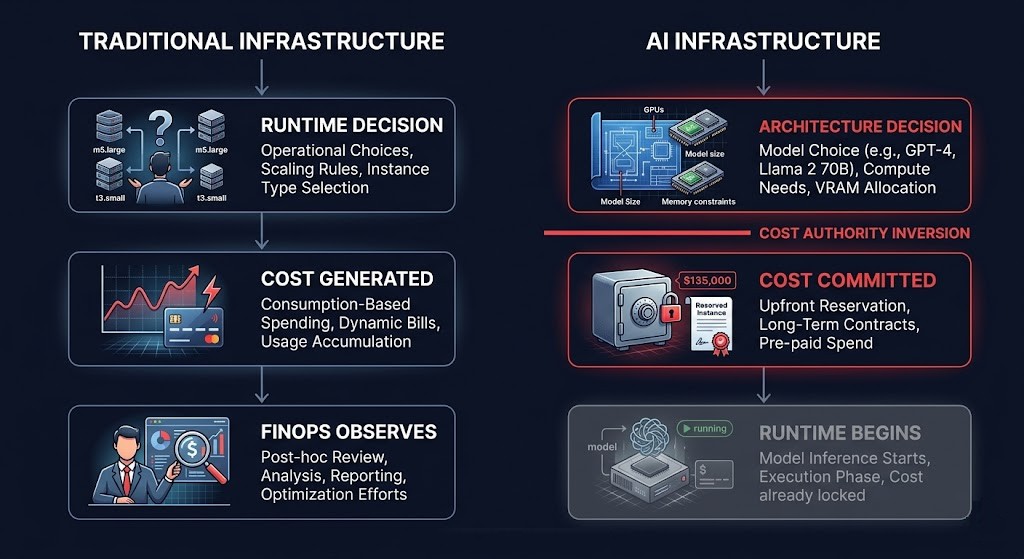
FinOps was built on a coherent economic model. It worked because the underlying infrastructure worked a specific way: compute ran when you needed it, stopped when you didn’t, and the bill reflected that relationship.
THE TRADITIONAL FINOPS CAUSAL CHAIN
01 — OPERATIONS GENERATED COST
Resources ran, cost accrued, teams observed and adjusted. Cost was a lagging signal of runtime decisions.
02 — FINOPS OBSERVED COST
Dashboards, tagging, attribution, show-back, charge-back. The observation layer was close enough to the cause to be useful.
03 — ENGINEERING OPTIMIZED AFTERWARD
Right-sizing, reserved instance matching, idle resource cleanup, auto-scaling. Every lever assumed that reducing utilization reduced cost.
The entire FinOps practice is built on that causal chain. Every optimization lever — reserved instances, spot capacity, right-sizing, auto-scaling — assumes cost is a lagging indicator of utilization, and that cost signals arrive in time to act on them. That model is coherent, well-documented, and completely wrong for AI infrastructure.
The Organizational Assumption FinOps Relied On
FinOps also assumed something about organizations that rarely gets made explicit: the team generating the cost could see the cost, and cost accountability mapped reasonably to team ownership.
In traditional infrastructure, the team that provisioned the servers owned the bill. The relationship between decision and spend was short, traceable, and attributable. FinOps tooling was built around that relationship — tag the resource, find the owner, show them the spend, enable optimization.
That assumption is gone in AI infrastructure. The engineer who chose GPT-4 over a smaller model didn’t think of it as a cost decision — it was a quality decision. The platform team that provisioned the GPU cluster doesn’t own the inference workload running on it. The developer writing the prompt doesn’t see the token bill. The FinOps team sees the bill but can’t trace it to the model selection, the context window size, or the agent fan-out pattern that generated it.
Cost authority — the power to make decisions that create spend — has fragmented across the entire engineering organization. FinOps is observing the output of decisions it had no visibility into and no seat at the table for. This is not a tooling gap. It is a governance gap, and it cannot be closed by adding more dashboards to a model that was never built for it.
That fragmentation has a parallel problem at the execution layer — when no defined identity boundary governs what an agent can invoke, cost authority and control plane authority collapse together. That failure mode is documented in The Model Answered. Nobody Asked Who Authorized That.
THE COST AUTHORITY TEST
“Who can approve the architectural decision that creates the spend — and who owns the bill after it exists?”
If those are different teams, your AI cost governance is already fragmented. The gap between those two teams is where uncontrolled AI spend lives.
The Four Ways AI Breaks the FinOps Model

The fourth failure mode is the most consequential because it compounds the other three. You can’t right-size a reservation you can’t see being used. You can’t enforce execution budgets on token consumption paths you can’t instrument. You can’t optimize architecture-time decisions when you can’t trace the bill back to them. Invisibility is the multiplier that makes every other AI cost problem harder than it would otherwise be. Inference observability covers the specific instrumentation layer that breaks this invisibility — the prerequisite before any other governance control can work. Cost visibility alone doesn’t fix the governance gap — observation without enforcement is reporting, not control.
The Cost Authority Inversion
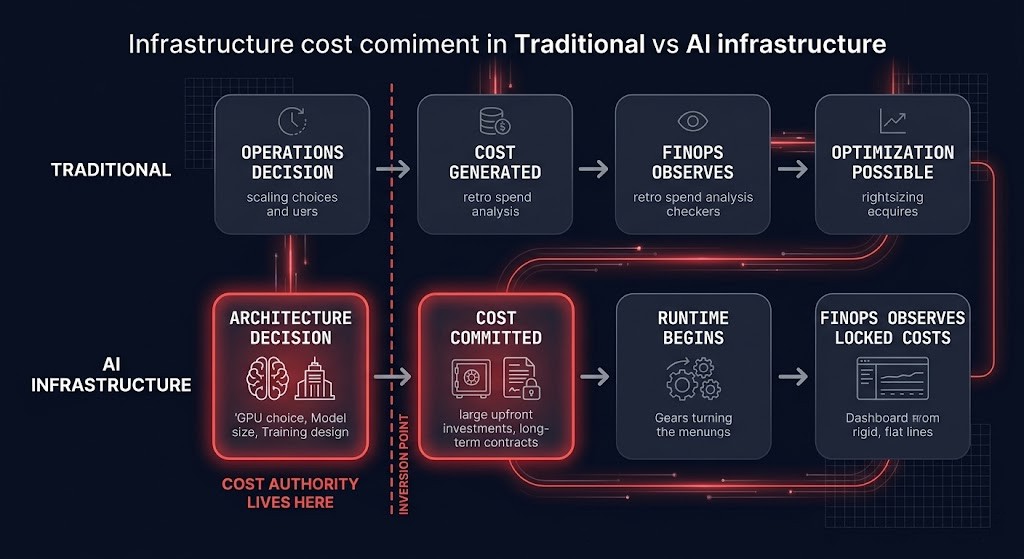
The named framework for what AI does to the FinOps model is not about cost magnitude — AI costing more than traditional infrastructure. It is about the movement of cost authority earlier in the lifecycle.
THE COST AUTHORITY INVERSION
| Stage | Traditional Infrastructure | AI Infrastructure |
|---|---|---|
| Cost authority | Operations teams — runtime decisions | Architecture teams — design decisions made weeks before runtime |
| Cost signal | Lagging — arrives after utilization, in time to optimize | Locked — committed at architecture time, visible after the window closes |
| Optimization lever | Reduce utilization → reduce cost | Change the architecture → change the cost structure |
| FinOps role | Observe → attribute → optimize | Observe a bill it cannot trace to decisions it could have influenced |
| Governance gap | Reactive — but correction is possible | Structural — the cost was committed before governance had a seat at the table |
The Cost Authority Inversion is not just a billing mechanics problem. It carries organizational and governance implications that compound over time. When cost authority moves earlier, the team that needs to govern cost changes. When cost is committed at architecture time, the governance window moves earlier too. When FinOps continues operating at the billing layer of a system where costs are locked at the design layer, it is governing the wrong moment in the lifecycle.
This connects directly to the Ownership Topology framework — a cloud bill, including an AI inference bill, is a map of who actually controls spend decisions. In AI infrastructure, that map points to architecture decisions made weeks before the invoice, by teams who were optimizing for model quality and system design, not cost structure. If those teams don’t have cost governance embedded in their decision-making process, the FinOps team is the last to know and the last to be able to do anything about it.
What Actually Works for AI FinOps
Three architectural governance mechanisms. Not billing controls. Not dashboards. Not optimization techniques applied after the bill arrives.
Model routing as a cost authority layer. Not all requests need your best model. A routing layer that directs simple queries to smaller, cheaper models and reserves large models for complex tasks is a cost governance decision built into the architecture — before cost materializes, not after. The routing logic is where cost authority is exercised in real time. Cost-aware model routing covers the specific routing architectures that keep inference spend deterministic across multi-model environments. Inference placement decisions determine whether routing even has the architectural flexibility to execute cost-aware decisions. The cluster scheduling layer is where cost authority decisions become structurally enforceable at runtime — where quota governance, admission control, and resource policy translate architecture-time decisions into operational constraints. That layer is covered in the Runtime & Cluster Orchestration stage of the AI Architecture Learning Path.
Execution budgets as a circuit breaker. Token caps, step limits, fan-out controls. The cost governance that traditional FinOps applies retroactively — after observing the bill — needs to be enforced at runtime in AI systems, before the agentic workflow consumes its 100× cost path. Budget limits are not a FinOps feature. They are an architecture constraint, and they need to be designed into the system before the first production request runs. Execution budgets cover step caps, token ceilings, and fan-out limits in full. Steady-state inference cost explains why permanent inference residency makes rightsizing irrelevant — the cost structure is architectural, not operational.
Observability at the inference layer. Not application performance monitoring. Not infrastructure monitoring. Instrumentation at the model call layer that decomposes the cost chain of every request: which model, how many tokens, which tool calls, which retries, which embeddings. Without this, the 37-operation request looks like one data point in the FinOps dashboard — and the Cost Authority Inversion remains invisible. Inference observability covers the specific metrics layer that makes cost chain decomposition possible before the invoice lands.
ARCHITECTURAL NOTE
None of these controls operate at the billing layer. They operate at the architecture layer — before cost materializes. That is the only layer where AI cost governance can actually work.
These three mechanisms address AI cost governance at the architecture layer. The broader strategic failure — why cloud cost reduction programs fail even when individual controls work — is covered in Why “Cheaper Cloud” Strategies Fail Without Architecture Changes. AI inference behaves structurally like egress cost — unpredictable, invisible until it hits, and generated by architectural decisions made weeks before the bill arrives.
The Organizational Fix
Two structural changes that address the Cost Authority Inversion directly — not workarounds, but repositioning of where cost governance happens.
Bring cost authority into architecture decisions. Model selection, context window defaults, agent design patterns, and routing logic are cost decisions. They should be treated as such at the time they’re made — not discovered as cost events three weeks later in a billing dashboard. This means FinOps representation in AI architecture reviews, not just in monthly cost reporting cycles. The governance window is at the design table, not the invoice.
Assign ownership to the decision, not the bill. Traditional cost attribution assigns spend to the team running the infrastructure. AI cost attribution needs to reach the team that made the architectural decision that created the spend. The engineer who chose the model owns the cost profile of that choice. The team that designed the agent owns the cost of its execution pattern. The Platform Team Became a Finance Team post (May 26 — pending) covers the organizational model required to make decision-level cost ownership operational at scale — and why platform teams are the teams most likely to be holding cost authority they don’t recognize as such.
Architect’s Verdict
Traditional FinOps doesn’t fail on AI workloads because it’s wrong. It fails because it was designed for a cost model that AI inverts. The economic assumptions — cost follows utilization, optimization happens after observation, accountability maps to the team running the infrastructure — are all valid for on-demand compute. None of them hold when cost was committed at architecture time, when utilization and spend have no reliable correlation, and when the team that generated the cost never saw a budget number.
The Cost Authority Inversion is not a billing problem. It is a governance problem. The authority to create spend moved earlier in the lifecycle — into architectural decisions made by teams who were optimizing for model quality and system design, not cost structure. Closing that gap requires treating model selection, execution budgets, and inference routing as cost governance decisions at the time they are made, not forensic exercises after the invoice arrives.
The infrastructure that generates your AI bill is not the infrastructure running today. It is the architecture your team approved last month.
The governance architecture that defines who holds execution authority over those decisions — which team owns the runtime, who controls the routing policy, and what constitutes Runtime Authority Vacuum when cost authority and control plane authority are both undefined — is the subject of Governance & Runtime Control (A6) in the AI Infrastructure Architecture Path.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session