Cloud Cost Is Now an Architectural Constraint
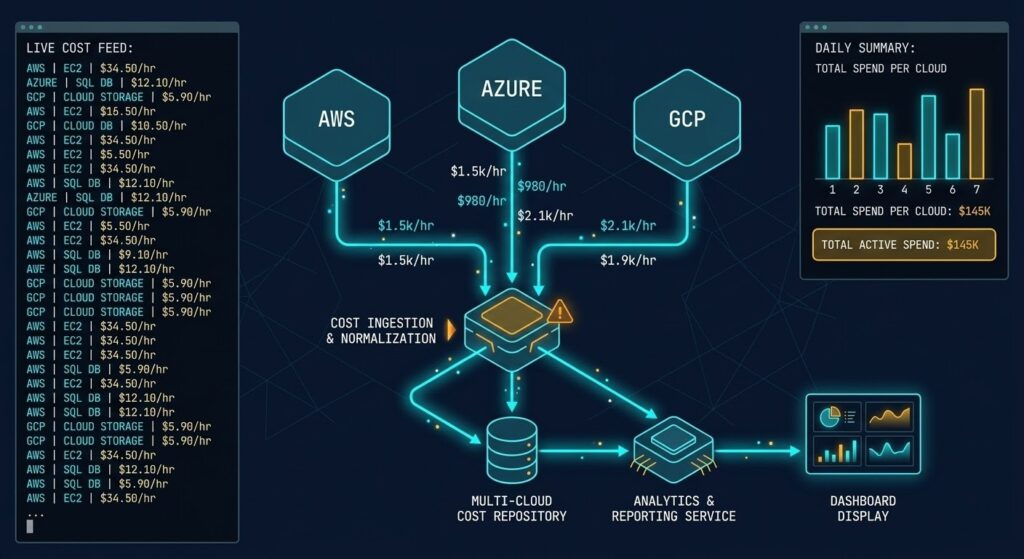
FinOps architecture used to mean dashboards. Cost reports. Monthly reviews where someone explained why the AWS bill was higher than forecast and promised to tag resources better next quarter.
That model is over.
The State of FinOps 2026 report marks the inflection point clearly: 78% of FinOps practices now report into the CTO or CIO organization — up 18% from 2023. FinOps teams are participating in vendor negotiations, workload placement decisions, and cloud provider selection. They are not reporting on spend. They are shaping it before it happens.
The shift has a name in the industry: shift-left costing. The principle is the same as shift-left security — catch the problem at design time, not after the bill arrives. In practice, it means cloud cost is now a design constraint that gets evaluated alongside latency, resilience, and compliance — not after them.
This post is the architectural read on what that shift actually requires.
The Structural Shift From Reporting to Governance
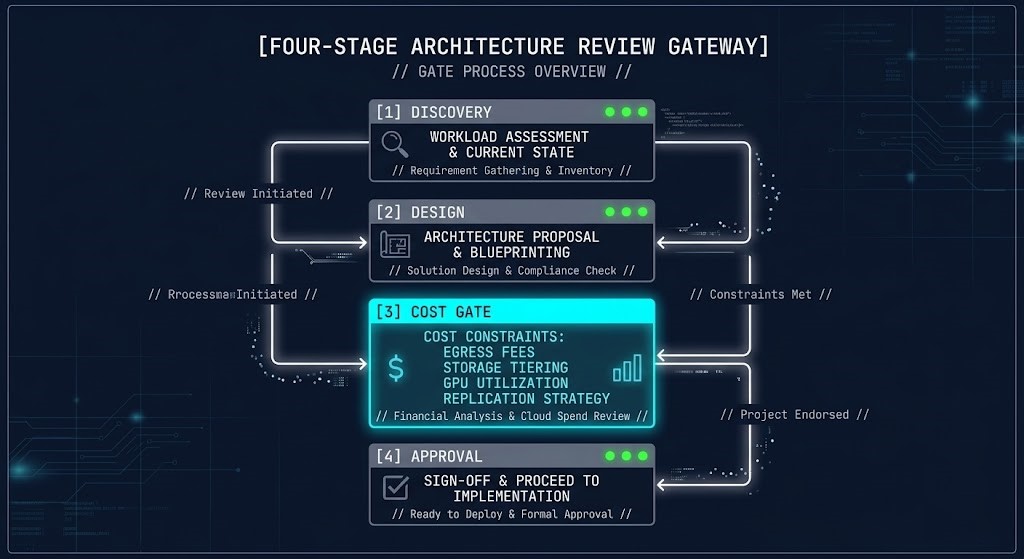
FinOps architecture is not abstract governance. It surfaces as four specific design constraints that determine whether an architecture is cost-sustainable at scale.
The old FinOps model was reactive. Teams provisioned infrastructure, workloads ran, bills arrived, and FinOps practitioners explained the variance. Optimization happened after the fact — rightsizing idle VMs, cleaning up orphaned snapshots, negotiating reserved instance coverage.
The problem with reactive FinOps is that the most expensive architectural decisions — where workloads live, how data moves between regions, what storage tier gets used for what class of data — are made at design time. By the time the bill arrives, the architecture is deployed, the contracts are signed, and the cost structure is locked in.
Shift-left FinOps architecture addresses this by embedding cost as a constraint in the design phase. Pre-deployment costing is now a top practitioner request in the 2026 data — teams want the ability to model the cost of an architectural decision before it gets approved, not after it gets deployed.
For infrastructure architects, this changes what a design review looks like. A complete architecture proposal in 2026 includes not just availability zones, replication topology, and compute sizing — it includes an egress cost model, a storage tier decision matrix, and a GPU placement rationale if AI workloads are involved. The full decision framework for where workloads belong lives in the Cloud Architecture Learning Path.
The Four Constraints Where Cost Enters the Design
Data movement between cloud regions, availability zones, and out of the cloud entirely carries costs that compound at scale. An architecture that replicates 10TB across regions for DR may look sound on paper — until the egress bill arrives. The question is not whether cross-region replication is necessary — it is whether the architecture minimizes the data movement required to achieve the resilience objective.
Active-active multi-region architectures carry significantly higher replication costs than active-passive designs. The resilience difference may be measurable in seconds of RTO improvement. The cost difference is measurable in thousands of dollars per month. That tradeoff belongs in the design review, not the post-mortem.
Cloud storage pricing is not flat. Object storage, block storage, archive tiers, and retrieval fees create a cost surface that varies by orders of magnitude depending on access patterns. An architecture that lands all data in a single storage tier consistently overpays. FinOps architecture requires a storage tier decision matrix: what data class goes where, based on access frequency, retrieval latency tolerance, and retention requirements.
AI workloads have introduced the most volatile cost variable in enterprise infrastructure. GPU instance costs are an order of magnitude higher than general compute, and idle GPU time is one of the most expensive forms of cloud waste. The architectural question is not just where the model runs — it is how utilization is maintained above the threshold where cloud GPU costs are economically rational versus on-premises alternatives.
Before the architecture gets approved, model the egress cost. The Cloud Egress Calculator benchmarks data transfer costs across AWS, Azure, and GCP — so the cost constraint enters the design review, not the monthly bill review.
→ Model My Egress Cost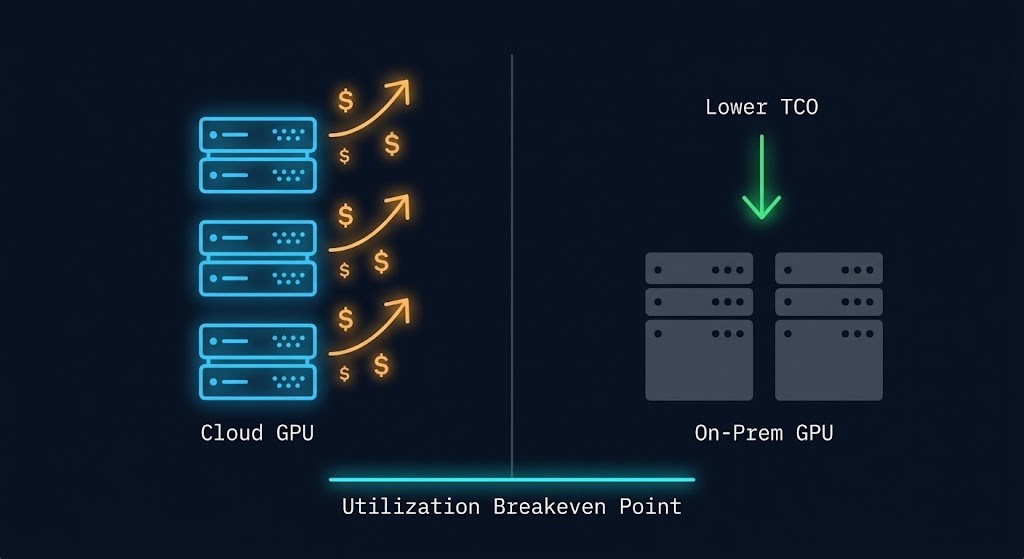
When the Cost Constraint Points On-Prem
The logical endpoint of shift-left FinOps architecture is repatriation analysis. When cost is a design constraint evaluated at the beginning of an architecture decision — not after deployment — the question of where workloads should run becomes an economic calculation rather than a default assumption.
Cloud has a platform tax. Egress fees, reserved instance commitments, cross-region replication costs, and GPU instance pricing all accumulate into a total cost of ownership that, for specific workload classes, exceeds the equivalent on-premises infrastructure within a defined payback window. The full breakdown of what that platform tax looks like in practice is covered in the Physics of Data Egress.
The 93% signal is not a rejection of cloud. It is a maturation of FinOps architecture thinking — organizations that have deployed at scale, accumulated cost visibility, and shifted costing left are now making deliberate placement decisions based on economic modeling rather than architectural defaults.
For high-utilization AI inference workloads, storage-intensive data pipelines, and latency-sensitive applications with predictable compute profiles, the FinOps architecture analysis increasingly points toward private infrastructure or hybrid deployment models. Not as ideology. As arithmetic. For the sovereign infrastructure angle on private deployment — where regulatory constraints combine with cost constraints — see the Sovereign Infrastructure Strategy.
The repatriation decision framework — when on-prem beats cloud on a per-workload basis — is covered in detail in the Cloud Repatriation Calculus. The architectural read on which workloads should never leave the cloud is covered in Which Workloads Should Never Leave the Cloud.
What FinOps Architecture Actually Requires
Embedding cost as an architectural constraint requires a governance model — not a dashboard. The distinction matters. A dashboard shows what has already been spent. A governance model shapes what is about to be deployed.
A functioning FinOps architecture governance model has four components.
Pre-deployment cost gates. Architecture proposals above a defined spend threshold require a cost model before approval. Egress model, storage tier plan, compute sizing rationale, and GPU utilization assumption are the minimum inputs. For teams running DR across regions, the Cloud Disaster Recovery Plan Guide covers how to model recovery architecture without defaulting to the highest-cost replication topology.
Workload placement criteria. A documented decision matrix that defines which workload classes belong in public cloud, which belong on private infrastructure, and which belong in a hybrid model — based on utilization profile, data gravity, latency requirement, and cost structure.
Cost attribution at the architecture level. Every deployed workload has an owner and a cost envelope. Attribution is the mechanism that makes engineers accountable for the cost outcomes of their architectural decisions. FinOps teams with executive-level engagement show two to three times greater influence over technology selection decisions than those operating at the director level only.
AI spend governance. AI workloads have moved from experimental to near-universal — 98% of organizations now manage AI spend as part of their FinOps scope, up from 31% in 2024. AI infrastructure cost requires the same pre-deployment cost gating as any other workload class — with additional scrutiny on GPU utilization assumptions and inference versus training placement decisions. For the infrastructure architecture behind AI workloads, see the AWS Lambda GenAI Architecture Guide.
What This Means for Design Reviews
The practical implication of FinOps architecture becoming infrastructure governance is that design reviews need to change.
A design review that approves an architecture based solely on availability, performance, and security — without a cost model — is incomplete. Not because cost is more important than resilience or security. Because an architecture that is economically unsustainable will eventually be changed under pressure, and changes made under cost pressure after deployment are where availability and security incidents actually happen.
Every architecture proposal should answer four cost questions before approval: What is the egress cost model at projected throughput? What storage tier strategy is in place for each data class? What is the GPU utilization assumption, and at what threshold does on-premises become the better economic choice? What is the cross-region replication cost at scale, and is the resilience benefit proportionate to the ongoing cost commitment?
These are not FinOps questions. They are architecture questions that FinOps discipline has forced into scope. The shift is permanent. Cloud cost visibility is now table stakes. Cost governance at design time is the next baseline. For the full cloud strategy framework that this governance model sits inside, see the Cloud Strategy pillar.
Q: What is FinOps architecture?
A: FinOps architecture is the practice of embedding cloud cost as a design constraint during the architecture phase — before infrastructure is deployed. It shifts cost governance from reactive bill review to proactive design control, covering egress modeling, storage tier decisions, GPU placement, and workload placement criteria.
Q: How does FinOps relate to cloud architecture decisions?
A: FinOps principles now directly influence architecture decisions including where workloads run, how data moves between regions, which storage tiers are used, and whether AI workloads belong in cloud or on private infrastructure. Cost is evaluated alongside latency, resilience, and compliance — not after them.
Q: What is shift-left costing in FinOps?
A: Shift-left costing applies the shift-left principle from software engineering to cloud financial governance — catching cost problems at design time rather than after deployment. It requires pre-deployment cost models as part of architecture approval workflows.
Q: When does cloud repatriation make economic sense from a FinOps perspective?
A: Repatriation makes economic sense when the total cost of ownership for on-premises infrastructure falls below the equivalent cloud cost within a defined payback window. High-utilization AI inference workloads, storage-intensive data pipelines, and latency-sensitive applications with predictable compute profiles are the most common repatriation candidates.
Q: How does AI spend change FinOps architecture requirements?
A: AI workloads introduce GPU cost volatility that standard FinOps governance models were not designed for. GPU instance costs are an order of magnitude higher than general compute, and the economics of cloud GPU burst versus private GPU clusters shift rapidly based on utilization. AI spend governance requires pre-deployment cost gating with explicit GPU utilization assumptions and inference versus training placement decisions.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




