Why Your DNS Failover Didn’t Actually Fail Over

The failover was declared at 02:14. The runbook was followed. DNS records updated. Health checks passing on secondary. The on-call engineer closed the incident bridge call at 02:31 with a single line in the ticket: failover complete. At 02:32, a monitoring alert fired. Traffic was still hitting the dead primary.
The DNS record had changed in seconds. The traffic moved 18 minutes later. Only one of those numbers mattered.
This is dns failover testing failure in its most common form — not a misconfiguration, not a vendor bug, not a missed step. Every layer in the stack behaved exactly as designed. The system still failed operationally. It belongs to the same class of failure documented in data protection architecture where the protection plane reports success and the recovery plane produces nothing useful.

What the Runbook Said Was Done
The runbook covered the right things. TTL had been pre-reduced to 60 seconds during the maintenance window two weeks prior. The health check interval on the secondary was 30 seconds. The DNS record update propagated to the authoritative nameservers within 90 seconds of execution. By every documented metric in the disaster recovery and failover playbook, the failover was complete.
The team was not wrong to close the bridge. They were wrong about what “complete” meant.
DNS failover is treated as a discrete event — you change the record, propagation happens, traffic moves. The mental model is a switch: off, then on. The operational reality is a drainage problem. Traffic does not move when the record changes. Traffic moves when every active path that was routing to the old record has expired its cached state and re-resolved. Those are different events, separated by an amount of time that no runbook entry captures.
The Declaration Gap is the period between when the failover is declared complete and when traffic has actually moved. It maps directly to RTA — Recovery Time Actual — the measured gap between when recovery is declared and when the system is genuinely operational again. In this case, the Declaration Gap was 18 minutes. In environments with more caching layers, it can be significantly longer.
The Four Layers That Each Did Their Job
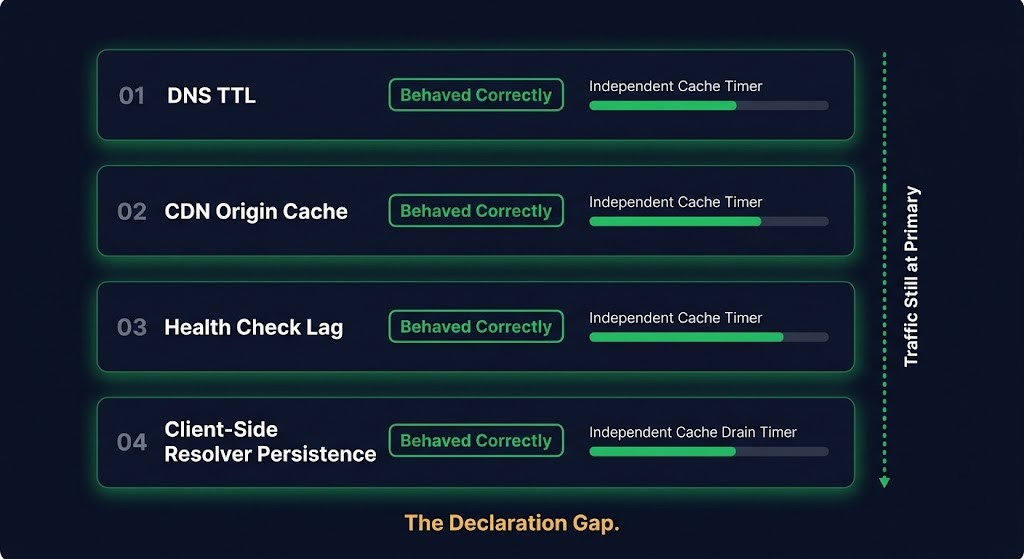
This is the part worth understanding precisely. The failure was not caused by any single layer behaving incorrectly. It was caused by four layers each behaving correctly — and nobody having modelled what that looked like in combination.
01 — DNS TTL
TTL had been pre-reduced to 60 seconds — a deliberate preparation step. Resolvers that re-queried after expiry got the new record immediately. TTL did its job. The problem is that TTL is a floor, not a ceiling. Resolvers are not required to honour TTL exactly, and under load many cache longer than the declared value. The 60-second TTL reduced the blast radius. It did not eliminate it.
02 — HEALTH CHECK LAG
The health check confirmed the secondary was healthy before the failover was declared. That check passed. What it did not model was the transition period — the window between the primary being declared dead and all traffic paths having drained away from it. Health checks measure endpoint state. They do not measure traffic distribution state. Passing health checks on secondary does not mean traffic has moved to secondary.
03 — CDN ORIGIN CACHE
The CDN layer sitting in front of the application had its own origin resolution cache with a TTL independent of the DNS TTL. When the DNS record changed, the CDN did not immediately re-resolve the origin. It served from its cached origin record for the remainder of its own TTL window. Traffic transiting the CDN continued to reach the old origin until the CDN’s internal cache expired — a separately timed event that nobody had factored into the RTO calculation.
04 — CLIENT-SIDE RESOLVER PERSISTENCE
Enterprise clients behind corporate recursive resolvers, browsers with internal DNS caches, and mobile devices with persistent resolver state all maintained their own cached records independently of what the authoritative nameserver was serving. When the record changed, these clients did not immediately re-resolve. They continued routing to the cached record until their own TTL — or their own cache logic — expired it. Every one of these clients honoured its own caching logic correctly. The system still failed operationally.
This is the same structural failure class as the retry storm — every component executes its designed behavior correctly, and the combination of correct individual behaviors produces a system-level failure nobody modelled. The failure is not in any layer. It is in the assumption that layers coordinate. The same failure class appears at the replication layer in Cross-Region Replication Is Not Resilience — where replication reports success while the recovery plane produces nothing operationally useful.
What DNS Failover Testing Actually Needs to Measure
Most dns failover testing validates the wrong thing. A test that confirms the DNS record updated and the health check passed has validated the protection plane. It has not validated the recovery plane — whether traffic actually moved, when it moved, and what the distribution looked like during the transition window. This is precisely the gap documented in restore path design applied to a different layer: success on the write side proves nothing about the read side.
This failure mode has a close relative in Azure Private Endpoint DNS resolution — environments where DNS behaves correctly at every individual hop while producing the wrong outcome at the traffic layer. The mechanism differs; the diagnostic principle is identical.
DIAGNOSTIC QUESTION
“How do you know traffic moved — and how long after declaration did you check?”
A test that surfaces the Declaration Gap needs to measure traffic distribution, not DNS state. It needs to run active traffic against the production path — including CDN-transited requests and enterprise resolver-cached clients. It needs to timestamp when the DNS record change executes and when traffic distribution on the secondary crosses a defined threshold. The gap between those two timestamps is the real RTO contribution from DNS failover. That number belongs in the RTO model, not a TTL assumption.
Pre-reducing TTL before a planned failover is necessary but not sufficient. The CDN cache TTL needs its own pre-reduction step — most CDN providers allow origin cache TTL configuration independently of DNS TTL. Ignoring this makes the CDN the binding constraint on traffic movement regardless of how aggressively the DNS TTL was tuned.
Monitoring during the failover window needs to watch traffic distribution at the application layer, not DNS propagation at the nameserver layer. The question the on-call engineer needs to answer in real time is not “has the record changed” — it is “what percentage of traffic is hitting the secondary right now.” The incident recovery process depends on being able to answer that question with data, not inference.
The Transferable Principle
DNS failover is not complete when the record changes. It is complete when traffic distribution changes.
That distinction rewrites the RTO model for any architecture that depends on DNS-based failover. The RTO contribution from a DNS failover event is not the TTL value. It is the time required for all active traffic paths to drain their cached state and re-resolve to the new record. These drainage events happen independently, on different timers, with no coordination signal between them.
The TTL is a floor on propagation speed. The actual Declaration Gap is determined by whichever caching layer takes longest to drain. In most environments that layer is either the CDN origin cache or the enterprise recursive resolver — neither of which is controlled by the TTL set on the DNS record.
Testing needs to validate this explicitly — not as a one-time exercise, but on the same cadence as the RTO it is supposed to guarantee. An architecture with a 15-minute RTO commitment that has never measured its Declaration Gap does not have a 15-minute RTO. It has a 15-minute aspiration and an unknown operational reality.
The record changed in seconds. The traffic moved 18 minutes later. Only one of those numbers mattered.
Architect’s Verdict
DNS failover testing that validates record propagation is not failover testing. It is nameserver testing. The operational requirement is different — traffic must move, not just resolve differently — and the gap between those two events is determined by caching layers that operate on independent timers with no coordination between them.
The Declaration Gap exists in every DNS-based failover architecture. TTL behaves correctly. Health checks behave correctly. CDN caches behave correctly. Client-side resolvers behave correctly. The failure is architectural — nobody modelled what the combination of correct individual behaviours produces at the traffic distribution layer during a failover transition.
RTO commitments anchored to DNS TTL values rather than measured Declaration Gap data are not commitments. They are assumptions that have never been tested against the actual drainage physics of the environment they are supposed to protect.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session