Upgrade Physics: Designing for Rolling Maintenance Without Stopping Production
Migration plans end at cutover complete.
Architecture does not.
Rolling maintenance AHV upgrade cycles are the operational layer most migration plans never model. Parts 01 through 04 of this series covered the physics of getting workloads onto Nutanix AHV — execution model translation, controller resource contention, I/O sequencing during the cutover window, and policy reconstruction across placement, availability, and security layers. Those are migration problems. They have a defined endpoint. They are solvable once.
This part covers what happens after the endpoint. The problem that does not have a defined endpoint. The one that repeats on every patch cycle, every AOS release, every hypervisor update for as long as the cluster runs production workloads.
A platform is only as stable as its ability to change without stopping.
Rolling maintenance — patching hypervisors, upgrading storage services, restarting control planes, updating firmware — is the first real stress test of a post-migration environment. Not performance. Not failover. Maintenance under load. Because the migration window was controlled, scheduled, and resourced specifically for the event. The rolling upgrade window is production. There is no second cluster to absorb the load. There is no rollback to VMware.
The physics of that window are what this part maps precisely.
What Rolling Maintenance Actually Is
Most teams enter their first AHV upgrade cycle with a mechanically correct model of what rolling maintenance involves: take a node out of service, apply the upgrade, return it to the cluster, repeat for each remaining node. The workloads stay online. The cluster stays available. The maintenance window closes with production intact.
That model is accurate at the procedure level. It is incomplete at the physics level.
When a node enters maintenance mode, the cluster does not simply pause that node’s workloads and resume them elsewhere. It initiates a chain of distributed system events that overlap, amplify, and interact in ways that steady-state monitoring does not expose. Workloads are live-migrated to remaining nodes, which absorb the evacuated compute and memory load simultaneously. Storage data previously local to the exiting node must be rebalanced across the fabric to maintain replication factor integrity. Controller services restart and temporarily redistribute metadata coordination across fewer peers. All three of these events unfold concurrently, on the same physical resources, while production I/O continues uninterrupted.
Rolling maintenance is not one event. It is a chain reaction of distributed system behavior triggered by a single administrative action.
The reason most teams do not model this in advance is that their VMware experience does not prepare them for it. In a vSphere environment backed by a SAN, maintenance mode evacuates compute workloads, but storage remains on the array — isolated from host-level activity. Rebuild events happen in the array controller, invisible to the hypervisor. The host maintenance is a compute operation. In an HCI platform, storage and compute are coupled on the same hardware. Maintenance on a node is a compute event and a storage event simultaneously.
That coupling is what this part models.
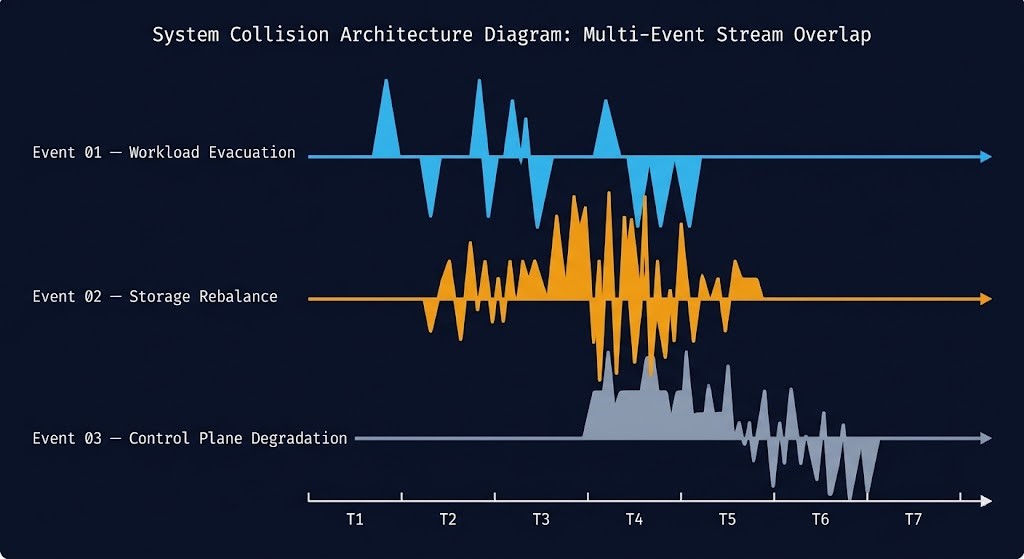
The Three Upgrade Events
Part 03 of this series defined Migration Stutter as the collision of three I/O events inside a cutover window. Upgrade storms are the Day-2 equivalent — the same physics, triggered by a different operational action, recurring on every maintenance cycle. The structure maps directly.
Each upgrade event is manageable in isolation. Under correct sequencing, the cluster absorbs each one without visible impact on production workloads. The failure mode is not any single event — it is what happens when they overlap.
Event 01 — Workload Evacuation: The Live Migration Surge
When a node enters maintenance mode, every VM resident on that node must be live-migrated to another host in the cluster before the upgrade can proceed. The evacuation itself is a standard AHV live migration operation — the kind that happens silently during normal scheduler rebalancing. What makes maintenance evacuation different is the concentration: all migrations from a single node, initiated simultaneously, targeting whatever compute and memory capacity remains available on the cluster’s remaining nodes.
The physics are straightforward. Each live migration generates a burst of east-west network traffic as the VM’s memory pages are transferred to the destination host. CPU consumption rises on destination nodes as they absorb both the migrating workload and the migration overhead. Memory pressure increases proportionally as the evacuated VMs’ working sets are re-homed. In a cluster operating at or near steady-state efficiency — which most production clusters are, because N+1 headroom is sized for failure tolerance, not maintenance absorption — the destination nodes experience a transient load spike that vCPU ready time and steal time metrics will surface before the migration completes.
The additional constraint is NUMA locality. In Part 01, we covered how NUMA boundary crossings introduce latency for memory-intensive workloads. Live migration does not guarantee locality-preserving placement on the destination node. Wide VMs that were running within a single NUMA node on the source host may land in configurations that span NUMA boundaries on the destination — particularly when destination nodes are already under load and the scheduler has limited placement flexibility. The performance impact surfaces as increased memory latency on workloads that were performing correctly before the maintenance window opened.
The metrics that matter here are VM migration concurrency, host CPU ready time on destination nodes, and east-west bandwidth utilization across the fabric. The decision rule is to limit concurrent evacuations — not because the migration tool cannot handle more, but because the destination cluster can only absorb so much simultaneous placement pressure before NUMA misalignment and scheduler contention begin affecting production workload performance.
Event 02 — Storage Rebalance: The Data Gravity Shift
While workload evacuation is visible in compute metrics, the storage rebalance that follows is the event most architects fail to model in their upgrade runbooks.
When a node exits the cluster for maintenance, the data previously stored on its local drives no longer contributes to the cluster’s replication factor. AOS must re-establish RF2 (or RF3, depending on the cluster configuration) by replicating that data to other nodes before the maintenance can safely proceed. This is not optional — a node under maintenance with unreplicated data represents a data availability risk that AOS addresses immediately and aggressively.
The rebuild traffic is additive to production I/O. A cluster managing 10TB of active data with a 30% utilization baseline generates meaningful rebuild I/O during a node exit — and that rebuild I/O shares the same storage fabric as production read and write operations. Write latency at P95 and P99 will climb during this window. Read locality shifts as data previously accessed locally now requires traversal to the node holding the rebuilt copy. Replication queue depth increases as the storage layer prioritizes rebuild writes alongside production writes.
The amplification multiplier from Part 03 applies here as well — RF2 means every rebuild write creates two copies, so the effective fabric traffic is roughly double the raw data volume being rebalanced. The rebuild bandwidth consumed per node exit is a function of how much unique data that node held and how aggressively AOS is permitted to rebalance. Tuning the rebuild throttle is one of the most operationally important levers in an upgrade runbook, and it is one of the least documented.
The metrics to watch are storage rebuild bandwidth, P95 and P99 read and write latency, and replication queue depth. The decision rule is categorical: do not proceed to the next node until the rebalance stabilizes. The temptation to advance the upgrade sequence before rebalance completes is the single most common cause of upgrade storms in production environments.
Event 03 — Control Plane Degradation: Services Under Stress
The third event is the least visible in standard monitoring dashboards and the most consequential when it compounds with Events 01 and 02.
During AOS upgrades, the Controller VM on the node under maintenance restarts. This is expected. What is less well understood is the ripple effect across the remaining CVMs in the cluster. Cluster metadata must be redistributed among the remaining controllers. Quorum and coordination layers adjust to operate with one fewer peer. Distributed operations that previously balanced across N controller nodes must now balance across N-1 — until the upgraded node rejoins the cluster and its CVM returns to service.
The practical consequence is that CVM CPU and memory consumption on the remaining nodes increases during the upgrade interval. For a cluster that was correctly sized with CVM headroom for production load, this increase is absorbed without visible impact. For a cluster running CVMs at 60–70% CPU under normal production conditions — which describes many production clusters that were sized for efficiency rather than operational headroom — the reduction in controller count pushes the remaining CVMs toward their performance ceiling.
Controller latency increases as CVM CPU saturates. Metadata operations slow. API response times for storage operations extend. The effect is not a storage outage — data remains available. The effect is a sustained increase in storage write acknowledgement latency that production databases and transactional workloads will surface as lock timeouts and transaction retries before any infrastructure alert fires. This is the same cascade described in the CVM saturation section of Part 03, triggered not by migration traffic but by control plane redistribution during maintenance.
The metrics are CVM CPU and memory utilization per remaining node, metadata operation latency, and service health timeout rates. The decision rule is to establish a CVM baseline ceiling before initiating maintenance. If any remaining node’s CVM is above 60% CPU at T-60 minutes before the maintenance window opens, the cluster does not have the control plane headroom to safely absorb the redistribution load.
Upgrade Storms and the Headroom Model
In Part 03, Migration Stutter was the term for a cascading I/O contention event caused by overlapping cutover operations. The Day-2 equivalent is an Upgrade Storm.
An Upgrade Storm is a cascading resource contention event caused by overlapping maintenance operations across nodes — specifically the condition where Event 02 from one node is still actively rebuilding when Event 01 from the next node begins. The fabric carries simultaneous rebuild I/O and evacuation I/O. Destination nodes absorb both migrating workloads and elevated storage latency from the ongoing rebalance. CVM CPU on surviving nodes is already elevated from the first node’s controller redistribution when the second node’s CVM restarts and redistributes again.
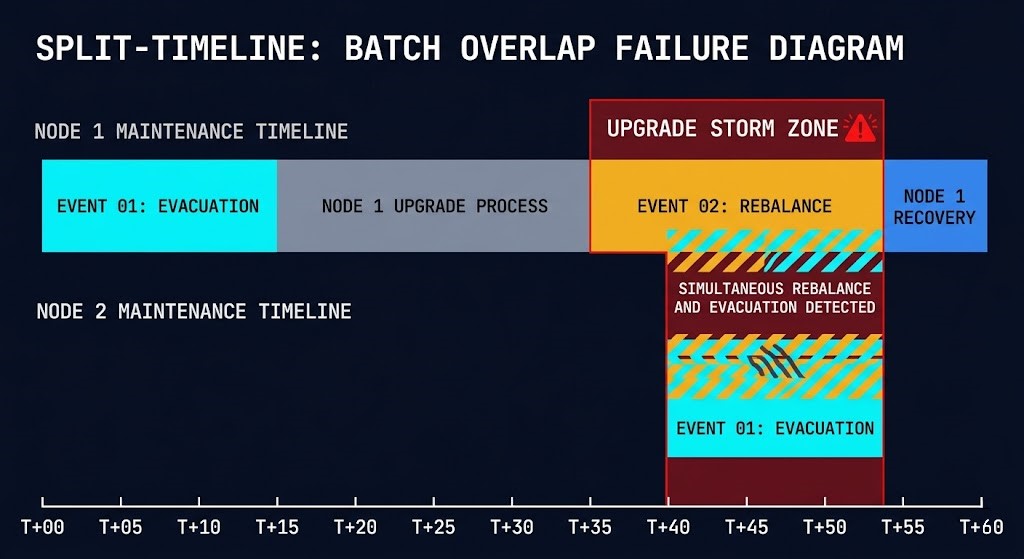
The failure mode is deterministic. It is not caused by hardware failure, software bug, or unexpected load. It is caused by advancing the upgrade sequence faster than the cluster can absorb the previous node’s event chain.
What makes this operationally dangerous is that it is entirely preventable with the right headroom model — and entirely invisible without one. A cluster can enter an upgrade storm while every individual metric appears within acceptable range, because storm conditions emerge from the combination of simultaneous events rather than the magnitude of any single one.
The Headroom Rule is the architectural countermeasure. A cluster must be able to lose one node and continue operating at peak production load without any metric exceeding its operating threshold. This means reserving capacity that will never be used under normal conditions — capacity that exists specifically to absorb the transient inefficiency of maintenance operations.
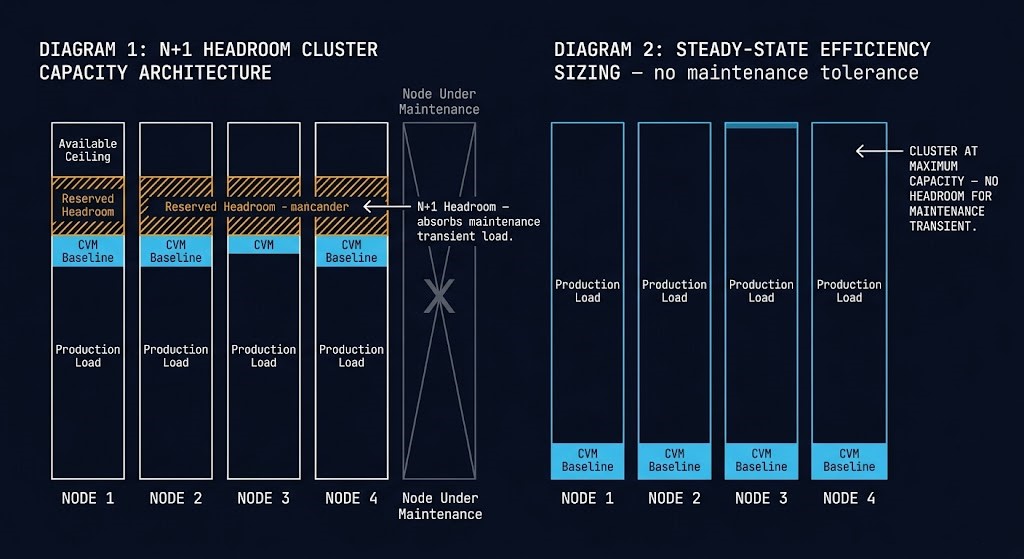
The practical targets are: N+1 compute capacity at minimum with CVM CPU baseline below 60% on all nodes before the maintenance window opens, storage fabric utilization below 50% at baseline to provide rebuild bandwidth headroom, and east-west network utilization below 40% to absorb the evacuation traffic without crowding production I/O. Migration bandwidth must be explicitly throttled — not left at maximum — to prevent the evacuation burst from monopolizing fabric capacity that the storage rebalance requires simultaneously.
Most clusters are sized for steady-state efficiency. Rolling maintenance requires transient inefficiency tolerance. The difference between those two sizing philosophies is the difference between a clean upgrade cycle and an upgrade storm at 2am.
The Upgrade Sequencing Model
The three events unfold in a predictable sequence when the cluster is correctly sized and the upgrade is paced correctly. Modeling that sequence explicitly — before the maintenance window opens — is what separates a controlled upgrade from a reactive one.
The following timeline describes the event chain for a single node entering maintenance on a correctly sized cluster. It is the baseline against which actual maintenance windows should be measured.
>_ SINGLE NODE MAINTENANCE — CLEAN SEQUENCE
T+00 Node enters maintenance mode
T+02 VM evacuation begins — Event 01 peaks
[East-west traffic at maximum, destination CPU climbing]
T+05 Storage rebalance begins — Event 02 initiates
[AOS detects under-replicated extents, rebuild I/O starts]
T+10 CVM/services redistribute on remaining nodes — Event 03 initiates
[Controller metadata redistributes, CVM CPU elevates]
T+15 VM evacuation completes
[All workloads confirmed healthy on destination nodes]
T+20 Storage rebalance reaches peak rebuild bandwidth
T+30 Rebalance traffic stabilizes — Event 02 subsiding
T+40 Node upgrade completes
T+45 Node rejoins cluster, CVM restarts and resynchronizes
T+55 CVM metadata rebalances across full node count
T+60 Cluster returns to steady state — all events cleared
[SAFE TO INITIATE NEXT NODE]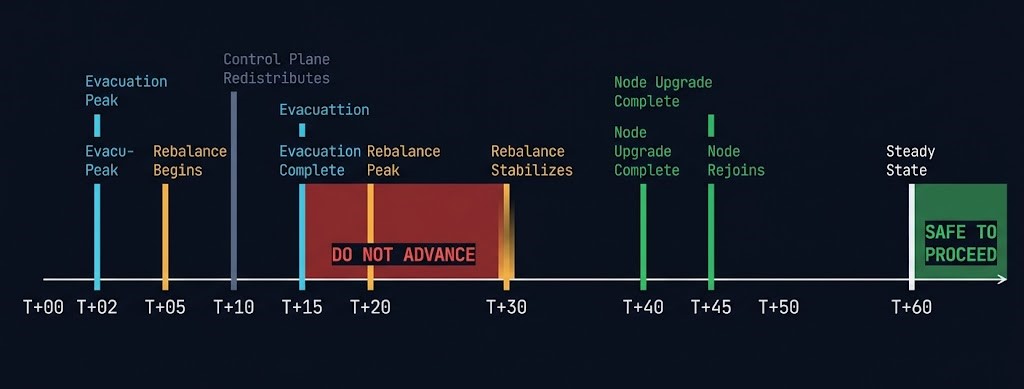
The critical interval is T+30 to T+60. This is the window most upgrade runbooks collapse. The node upgrade itself completes at T+40. The cluster has not yet cleared Events 02 and 03. The instinct — particularly during business-hours maintenance windows where schedule pressure is real — is to proceed to the next node at T+40 because the upgrade task is done.
Starting the next node at T+40 instead of T+60 means the next node’s Event 01 begins while the previous node’s Event 02 is still active. The fabric carries overlapping rebuild I/O and evacuation I/O simultaneously. Two controller redistributions are in progress concurrently. The cluster has no headroom for the combination. Latency climbs. The upgrade storm begins.
The rule: never allow more than one upgrade event to peak simultaneously across nodes. The maintenance window extends. That is acceptable. A production latency incident caused by overlapping maintenance events is not.
Policy Interaction During Maintenance
Part 04 covered the risk of policy gaps in the post-migration environment. During rolling maintenance, those gaps surface in ways that are operationally more acute than under normal operations — because maintenance creates constrained placement conditions that the policy layer was never designed to navigate.
Anti-affinity rules are the primary interaction risk. An anti-affinity policy that keeps two domain controllers on separate nodes functions correctly when the cluster has four available nodes. When node 1 is under maintenance and node 2 is the evacuation target, the anti-affinity rule may prevent the placement of a VM that must evacuate — because the rule correctly identifies that its anti-affinity pair is already resident on the target node. The scheduler has nowhere to place the VM. The evacuation stalls. The maintenance window breaks.
This is not a policy failure. The policy is doing exactly what it was configured to do. It is a headroom failure — the cluster does not have a viable placement target that satisfies both the anti-affinity constraint and the maintenance requirement simultaneously. The correct resolution is not to disable the anti-affinity policy during maintenance. It is to verify, as part of the pre-maintenance runbook, that every policy-constrained VM has at least two valid placement targets available after the maintenance node is removed from the eligible set.
Segmentation policies create a second interaction surface. Flow micro-segmentation policies that depend on category membership function correctly when VMs are migrated to new nodes — category membership is metadata, not host-relative. But migration paths in segmented environments pass through the same network fabric as policy enforcement traffic. During high-evacuation-rate windows, the combination of migration traffic and policy enforcement overhead on the distributed firewall layer can produce transient latency spikes in East-West flows that appear in application logs as intermittent connection timeouts rather than storage metrics.
DR policies introduce a third consideration. Nutanix protection policies and recovery plan configurations must account for the temporary reduction in available nodes during maintenance. A protection policy with a tight RPO that relies on synchronous replication across specific nodes may temporarily degrade during maintenance if the replication path is affected. Verify replication health as part of the post-node-upgrade validation steps — before proceeding to the next node — rather than assuming replication status carries over automatically.
The pre-maintenance policy audit is not a one-time migration task. It is a recurring maintenance preparation step.
The Upgrade Runbook
The sequencing model is the theory. The runbook is how it operates in production. The following framework mirrors the structure of the pre-cutover checklist in Part 03 — extended to cover the full maintenance cycle rather than a single migration window.
Pre-Maintenance Verification
01 — Cluster Headroom
Confirm compute headroom: no node above 70% CPU at P95 over the prior 7 days
Confirm CVM baseline: all CVMs below 60% CPU at T-60 minutes
Confirm storage fabric: below 50% utilization
Confirm east-west bandwidth: below 40% utilization
02 — Rebalance Status
Confirm no active rebuild jobs before opening the window:
ncli pd list | grep -i rebuild
A cluster mid-rebuild before maintenance begins has zero headroom
for the additional rebuild load generated by the first node exit.
03 — Policy Pre-Validation
For every anti-affinity-constrained VM, verify at least two valid
placement targets remain after removing the maintenance node
from the eligible set.
Identify any protection policies with synchronous replication
paths that traverse the maintenance node — note expected
degradation and establish monitoring alert thresholds.
04 — Rollback Criteria (define before the window opens, not during it)
Maximum acceptable P99 storage latency: ___ms (recommended: 5ms for databases)
CVM CPU ceiling to pause next node: 70%
Maximum rebalance bandwidth to advance sequence: 20% of peak fabric
Maximum window extension before escalation: ___ minutesDuring Maintenance
05 — Node Entry
Initiate maintenance mode on one node at a time.
Do not use automated simultaneous multi-node maintenance.
Monitor evacuation progress in real time — do not step away from
the console during the T+00 to T+15 window.
06 — Event Monitoring
Watch these metrics continuously from T+00 to T+60:
allssh "top -bn1 | head -5" — CVM CPU per node
ncli host list — node status
nutanix_storage_controller_outstanding_io — queue depth
nutanix_cluster_storage_rebuild_io_bandwidth_MBps — rebuild rate
Pause the sequence if CVM CPU on any surviving node exceeds 80%.
The upgrade waits. Production latency incidents do not.
07 — Stabilization Gate
Before initiating the next node, confirm ALL of the following:
☐ Rebuild bandwidth below 20% of peak fabric bandwidth
☐ P99 storage latency at or below pre-maintenance baseline
☐ CVM CPU below 60% on all nodes
☐ Outstanding I/O queue depth normalized
☐ Anti-affinity policies validated for next node's evacuation targetsPost-Maintenance Validation
08 — Cluster Health
After all nodes complete:
ncli cluster info — cluster health status
ncli pd list — protection domain integrity
nutanix_cvm_cpu_usage_percent — CVM baseline restored
09 — Policy Integrity
Confirm anti-affinity policies are enforced across the post-upgrade
cluster topology. New node placements that occurred during evacuation
may have temporarily violated constraints — verify VMs are back on
their intended hosts or explicitly accept the new placement.
Confirm Flow segmentation categories are intact on all migrated VMs.
Confirm protection policy replication status on all protection domains.
10 — Synthetic Workload Test
Run a representative I/O profile against the storage layer before
marking the maintenance window complete. The goal is to confirm the
cluster returns to its pre-maintenance P95 and P99 latency baseline —
not just that the infrastructure shows healthy in the dashboard.The Real Risk: Deferred Maintenance
There is a pattern in post-migration environments that is worth naming directly, because it is the operational failure mode that undoes otherwise clean migrations.
Teams that go through a difficult migration cycle — where cutover windows ran long, where Migration Stutter events required recovery protocols, where the policy translation work in Part 04 consumed more time than planned — arrive on the other side with a functional platform and an understandable reluctance to disturb it. The cluster is running. Production is stable. The upgrade notification from Nutanix LCM sits in the queue. The maintenance window gets pushed to next quarter.
This is how environments accumulate AOS version debt, hypervisor version debt, and firmware debt simultaneously — and then face a compounded upgrade sequence where multiple layers require updating in a specific order, the LCM compatibility matrix constrains the path, and the required cluster headroom for each individual upgrade is no longer available because the cluster has grown into its N+1 capacity over the intervening months.
The risk is not performing rolling maintenance.
The risk is running a platform that cannot be safely upgraded — because the operational hesitation to maintain it has allowed the gap between the current version and the required version to grow wide enough that the path forward is itself a project.
Security exposure is the most visible consequence. AOS releases carry CVE remediation. Hypervisor updates carry kernel-level security patches. A cluster running three AOS versions behind the current release is running with known vulnerabilities that Broadcom’s post-acquisition licensing changes prompted the migration specifically to eliminate. The irony of migrating off VMware to avoid Broadcom’s security support decisions and then running an unpatched AHV cluster is not subtle.
Performance degradation is the less visible consequence. Nutanix engineering ships meaningful I/O path optimizations in AOS releases. CVM efficiency improvements. Scheduler refinements. Storage fabric improvements that directly affect the P95 and P99 latency metrics this series has used as the health signal throughout. An environment deferred from upgrade by two or three AOS versions is not running the platform at its current capability — it is running a progressively more dated version of the platform it migrated to.
The unsupported configuration risk is the operational consequence that surfaces in support escalations. Nutanix support commitments operate within defined version compatibility windows. A cluster running an out-of-support AOS version with a support contract is not the same as a cluster running a supported version — the support organization’s ability to diagnose and remediate issues against an outdated codebase is materially constrained.
The correct operating model is a defined upgrade cadence — not a reactive one triggered by support escalations or security incidents. LCM upgrade notifications are not optional maintenance requests. They are the platform’s version management interface. Treating them as such, and building the cluster headroom model that makes acting on them operationally safe, is the difference between a production platform that ages gracefully and one that accumulates technical debt until the next forced migration event. Nutanix publishes detailed guidance on rolling maintenance AHV upgrade sequencing and LCM compatibility requirements in the Nutanix Upgrade Guide and the Life Cycle Manager documentation — both should be reviewed before opening any production maintenance window.
Architect’s Verdict
Migration success is temporary.
Operational stability is continuous.
Parts 01 through 04 of this series covered the physics of getting to the other side of a post-Broadcom migration. This part covers what the other side actually requires to remain stable — the maintenance discipline, the headroom model, the sequencing rigor, and the policy awareness that distinguish a production platform from a migration project that never fully completed.
A platform that cannot handle rolling maintenance without performance degradation is not production-ready — regardless of how clean the migration was. The upgrade window is not a risk to minimize. It is an operational capability to build.
The teams that run clean upgrade cycles are not the ones that got lucky with timing or cluster sizing. They are the ones that modeled the event chain before the window opened, built the headroom the model required, and held the sequencing discipline when the schedule pressure was real.
Build the platform. Then maintain it.
You know the risk of carrying forward architectural debt. Now, we tear down the mechanics. Track the series below as we map the exact physical changes required for a deterministic migration.
Skip the wait. Download the complete Deterministic Migration Playbook (including the Nutanix Metro Cluster Implementation Checklist) and get actionable engineering guides delivered via The Dispatch.
SEND THE BLUEPRINTContinue the Architecture
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session