Veeam vs Commvault: How Enterprise Backup Platforms Fail Differently
Veeam vs Commvault is not a feature comparison. I’ve seen both of these platforms fail in production — not in the way vendor docs describe, but in the way systems actually break at scale, under pressure, at 2 AM when recovery is the only thing that matters.
Veeam and Commvault don’t fail the same way. They fail at different layers of the system. And which failure mode your team can operate through is the real decision — not the feature matrix, not the benchmark, not the renewal quote.
The Mental Model: Where Backup Platforms Actually Break
Backup platforms don’t prove themselves when everything works. Every platform looks good in a demo environment with 50 VMs, clean jobs, and no concurrent restores.
They prove themselves — or fail — in three specific conditions: scale, incidents, and recovery. A platform that handles all three cleanly for your environment is the right platform. A platform that fails at the layer your team is least equipped to handle is the wrong one.
Veeam and Commvault have fundamentally different architectures. Those architectures produce fundamentally different failure signatures. Understanding the failure signature before you commit is the decision.
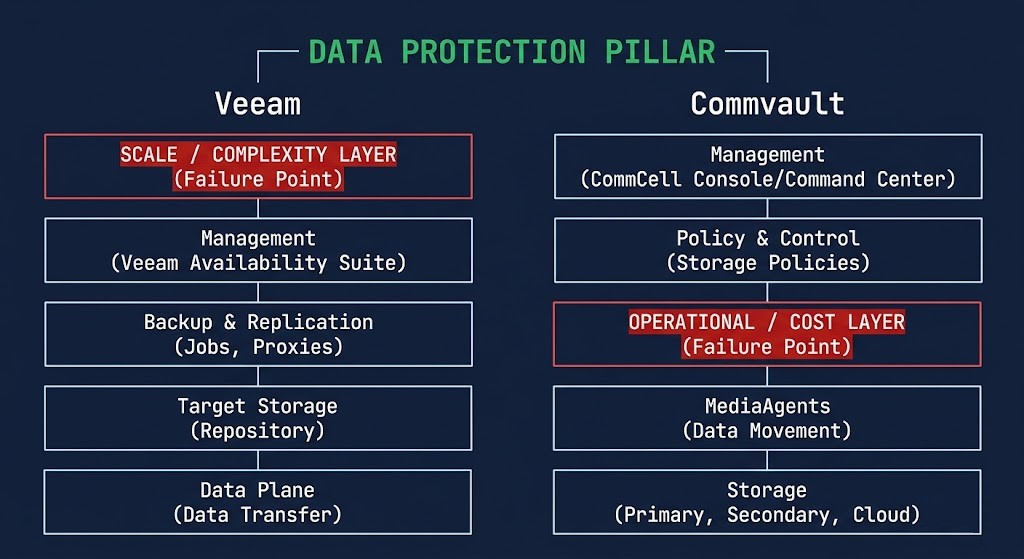
Veeam vs Commvault: The Architecture Difference
Veeam was built for simplicity and speed. The architecture is transparent — you can see what it’s doing, trace what failed, and fix it without a Commvault-certified engineer on the phone. Deployment is fast. The learning curve is shallow. For teams that need to be operational quickly and don’t have deep backup specialization on staff, that transparency is a genuine operational advantage.
Commvault was built for depth and control. The platform is deeply integrated — it handles complex policies, multi-site topologies, and compliance workflows that Veeam requires significant scripting to approximate. The abstraction layers that make it powerful are also what make it opaque. When something goes wrong, the troubleshooting path is longer and more operator-dependent.
Neither architecture is wrong. They produce different failure modes — and different operational requirements to manage through them.
Veeam Failure Modes
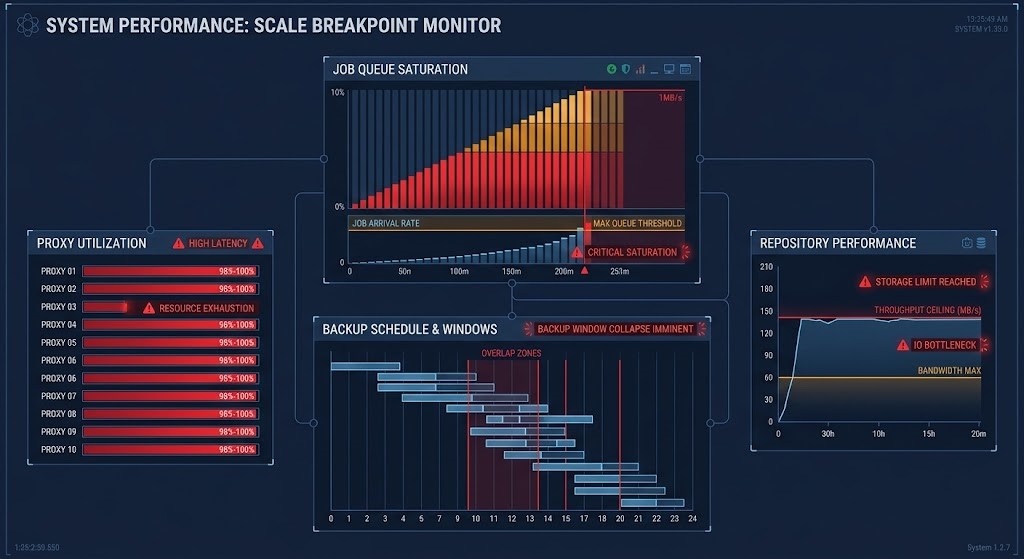
Scale Breakpoint
Veeam works cleanly — until it doesn’t. In environments under a few hundred VMs with manageable job counts, the platform is reliable and predictable. As environments grow — more jobs, more proxies, more repositories, more concurrent operations — the cracks appear.
Job contention becomes the primary symptom. Backup windows start overlapping. Proxy saturation causes jobs to queue. Repository throughput limits surface under concurrent load that never existed in the smaller environment. The platform didn’t break — it hit a scale ceiling that its architecture wasn’t designed to handle gracefully.
The failure mode is insidious because it doesn’t present as an error. It presents as performance inconsistency and missed backup windows — problems that look like infrastructure issues before they look like platform limitations.
Complexity Leakage
Veeam’s simplicity at small scale becomes manual overhead at large scale. The same transparency that makes it easy to understand creates a management burden when the environment grows: job sprawl, scripting requirements, policy drift across hundreds of manually configured jobs.
What started as a clean, legible backup environment becomes a web of scripts, exceptions, and undocumented configuration decisions made by engineers who are no longer on the team. The complexity didn’t come from Veeam — it leaked in through the gaps the platform doesn’t fill natively.
Recovery Bottlenecks
Backup is easy. Restore at scale isn’t. Veeam’s restore performance under concurrent recovery scenarios — multiple VMs, multiple repositories, multiple datastores simultaneously — exposes throughput limits that are invisible during normal backup operations.
The failure surfaces exactly when it is most costly: during a ransomware recovery or a datacenter failover, when every hour of recovery time has a measurable business impact. Repository throughput limits and proxy contention don’t show up in the backup report. They show up in the recovery window.
Commvault Failure Modes
Operational Opacity
Commvault’s abstraction layers are its greatest strength and its most consistent failure mode. The system is working — but you don’t always know why. When something goes wrong, the troubleshooting path runs through multiple abstraction layers, hidden dependencies, and configuration interactions that require platform expertise to navigate.
The symptom isn’t failure — it’s duration. Incidents that should take 30 minutes to diagnose take three hours because the system’s complexity obscures the root cause. Teams without deep Commvault expertise consistently report that the platform works until it doesn’t, and when it doesn’t, finding the failure requires a level of platform knowledge that most organizations don’t maintain internally.
Cost Ambiguity
Commvault’s licensing model is powerful and genuinely difficult to forecast. Feature bundling, capacity tiers, and module-based pricing combine to produce renewal quotes that consistently surprise organizations that didn’t model the full cost at purchase.
The failure isn’t in the platform — it’s in the financial predictability. Environments that grow, add workload types, or expand into new protection scenarios find themselves in licensing conversations they didn’t anticipate. The cost ambiguity is a feature of the model, not a bug — and it creates budget risk that Veeam’s simpler licensing structure doesn’t produce.
Configuration Fragility
Highly configurable means highly breakable. Commvault’s depth of configuration is a genuine advantage for complex environments — and a genuine risk for environments that don’t have the operational discipline to manage that complexity carefully.
Misconfiguration risk is higher than in simpler platforms. Unintended interactions between policies, schedules, and storage targets surface as failures that are difficult to attribute and difficult to reproduce. The same flexibility that enables sophisticated data protection workflows enables sophisticated misconfiguration.
Recovery Complexity
Commvault recoveries work — but they require expertise. Multi-step workflows, operator-dependent procedures, and platform-specific recovery sequences mean that recovery under pressure is slower and more error-prone than the platform’s technical capabilities suggest.
Recovery drills that run smoothly with a trained Commvault engineer on-site fail under incident conditions when that engineer isn’t available. The platform’s power doesn’t simplify the recovery workflow — it adds complexity that must be managed through operator skill rather than platform transparency.
The Real Decision
The feature matrix doesn’t answer the question. The benchmark doesn’t answer the question. The question is: which failure mode can your team operate through under pressure?
| Environment Profile | Better Fit | Failure Mode to Own |
|---|---|---|
| Lean team, fast deployment, <500 VMs | Veeam | Scale breakpoint as environment grows |
| Mid-market, mixed workloads, growing estate | Veeam + immutability layer | Complexity leakage requiring scripting discipline |
| Large enterprise, complex compliance, multi-site | Commvault | Operational opacity requiring platform expertise |
| FinServ / HealthCare, regulatory, audit-driven | Commvault | Cost ambiguity requiring proactive licensing model |
Backup doesn’t fail when it runs. It fails when you need it.
Where Both Fail
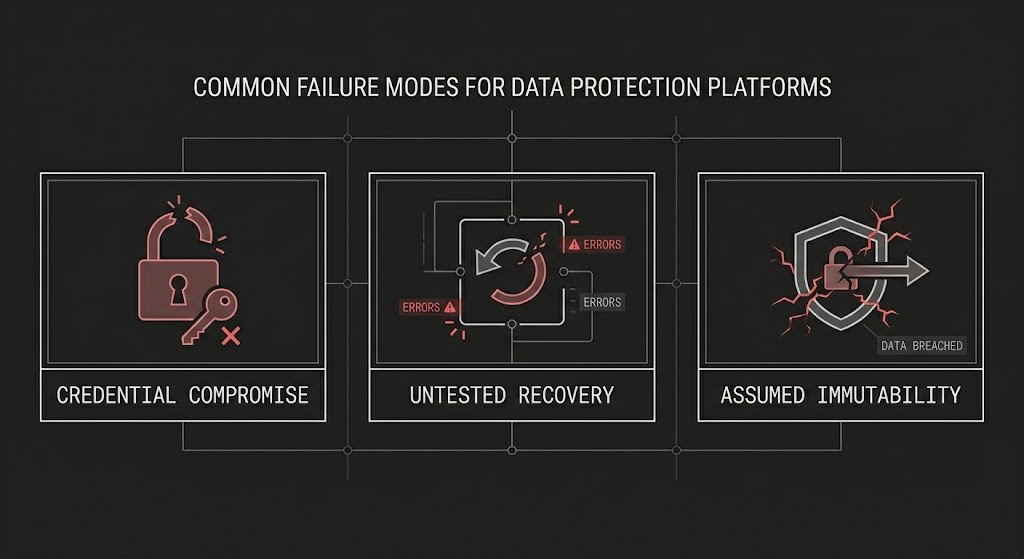
Veeam and Commvault share three failure modes that have nothing to do with platform architecture — and everything to do with operational discipline.
Credential compromise. Both platforms store credentials for every system they protect. A compromised backup administrator account is a compromised backup environment — regardless of platform. Neither Veeam nor Commvault protects against this failure mode natively. It requires external controls: privileged access management, MFA on backup console access, and separation of backup administration from infrastructure administration.
Untested recovery. The most common backup failure mode in enterprise environments is not a platform failure — it is a recovery that was never tested. Backup jobs that complete successfully for three years and restore nothing successfully when needed are a failure of operational discipline, not platform capability. The platform cannot fix this. Scheduled recovery testing can.
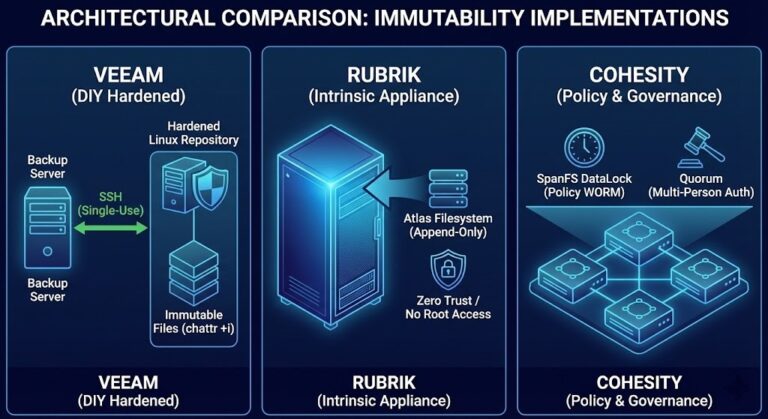
Assumed immutability. Both platforms support immutable backup targets. Neither enforces immutability by default. Organizations that assume their backup environment is ransomware-resistant because they are running Veeam or Commvault — without explicitly configuring and validating immutable targets — are wrong. The immutable backup architecture post covers what immutability actually requires at the storage layer and why Object Lock configuration alone is not enough.
Architect’s Verdict
Veeam and Commvault are both mature, capable enterprise backup platforms. The question is never which platform is better — it is which failure mode your team is equipped to manage.
Veeam fails at scale and architectural complexity. If your environment is growing, if your team is lean, and if you don’t have the scripting discipline to manage job sprawl and policy drift, you will eventually hit the scale breakpoint. Plan for it before you need to recover through it.
Commvault fails at operational clarity and cost transparency. If your team doesn’t have deep platform expertise, if your troubleshooting capacity is limited, and if your finance team needs predictable renewal costs, the abstraction layers and licensing model will create friction at exactly the wrong moments.
You are not choosing a backup tool. You are choosing which failure mode you are willing to own — and building the operational discipline to manage through it.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session