The Day 2 Operations Debt You Inherited From Terraform
Terraform codebases outlive the teams that wrote them. That is the first thing to understand before you inherit one.
The provisioning worked. The deployment velocity was real. The infrastructure exists, it runs, and the state file says it matches reality. What accumulated silently over two or three years of production operation was something different: an operational authority system nobody designed, running on top of a tool that was never built to be one. You now own that system. The Terraform files are the easy part.

The distinction matters because terraform day 2 operations failure is not a provisioning failure. Terraform’s provisioning story is strong. Reproducibility, deployment consistency, velocity — it delivers all of it. What it does not inherently solve is runtime ownership, recovery sequencing, operational diagnostics, or drift governance. Those problems were left to whoever showed up next. In many organizations, that is now you.
What “Inherited” Actually Means in Terraform
When you inherit a Terraform codebase, you inherit two things that rarely match.
The first is the declared state: the .tf files, the module calls, the provider configurations, and the state file that maps all of it to actual infrastructure. This is the version Terraform describes.
The second is the operational reality: the infrastructure your team actually depends on, including everything that happened between Terraform applies — the console changes that felt too urgent to run through the pipeline, the manual patches applied during an incident at 2am, the resources imported under pressure with placeholder documentation, and the modules left running long after the team that wrote them left the company. That departure risk is not incidental to the debt — it is a primary delivery mechanism. When infrastructure operational knowledge concentrates in two or three engineers, the bus factor on the codebase is as much a governance problem as a personnel one.
The gap between those two versions is where every Day 2 operations problem lives. Teams that do not consciously map that gap discover it during incidents, when the apply they need to run to fix something carries unknown blast radius, or when the module they need to modify has no documented interface and three teams depending on it in ways nobody fully understands.
The state file is the source of truth that nobody fully trusts. That is not a Terraform limitation. That is the operational residue of years of decisions made under pressure by people who are no longer around to explain them.
The Terraform Operational Inheritance Surface
The debt does not arrive as one problem. It arrives as five distinct layers, each one invisible until it produces a failure. Together they form the Terraform Operational Inheritance Surface — the accumulated operational cost of a codebase that was built for provisioning velocity and promoted, quietly, into something it was never designed to be.
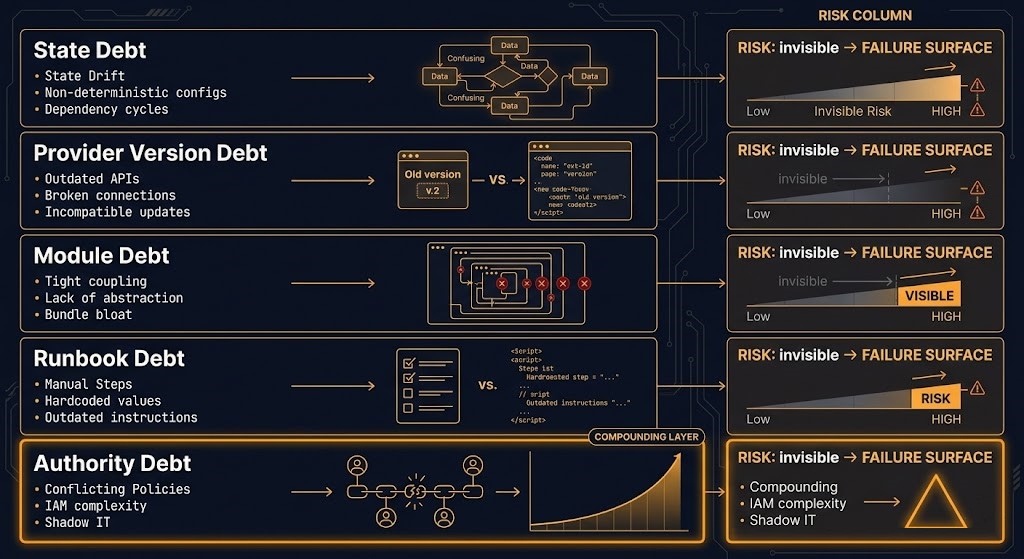
01 — STATE DEBT
State file sprawl, sensitive data embedded without remote backend hygiene, orphaned resources that exist in state but serve no current purpose, and imported resources whose provenance is undocumented. The state file reflects every decision ever made — including the bad ones that were never cleaned up.
02 — PROVIDER VERSION DEBT
Provider versions pinned at whatever was current when the codebase was written, deprecated resources still in use because nobody wanted to trigger the migration, and upgrade risk compounding with every quarter that passes. A security patch that requires a provider upgrade becomes a multi-week project. The pinning that protected stability has become the constraint that blocks it.
03 — MODULE DEBT
Internal modules written once, never maintained, and used by multiple teams with no documented interface contract. The module worked when it was written. Its behavior under the current provider version, with the current variable inputs from three different calling configurations, is something nobody has tested. Modifying it requires reverse-engineering intent from code written by someone who is no longer available to ask.
04 — RUNBOOK DEBT
Apply procedures, break-glass patterns, destroy sequencing, and rollback steps — all undocumented, wrong, or both. The runbook says “run terraform apply.” It does not say which workspace, in which order, with which variables, after confirming which downstream dependencies are safe to disrupt. That knowledge lived in the previous team’s heads and left with them.
05 — AUTHORITY DEBT
Nobody knows which changes are authoritative anymore. Console overrides accepted as permanent. Emergency manual patches applied during incidents and never reconciled. Multiple CI systems with apply capability, each with its own service account. Imported resources with unknown provenance. Modules bypassed operationally because the overhead of updating them was higher than just fixing the resource directly. This is the layer that makes everything else worse — because even if you clean up the state, pin the providers, and document the modules, you still don’t know whether Terraform is the authority or just one of the things that sometimes changes infrastructure.
This is the same failure pattern platform teams hit when they build an internal developer platform on top of Terraform, expecting it to resolve authority debt automatically: IDPs Don’t Solve the Ownership Problem. They Defer It. — centralizing the interface doesn’t assign the ownership Terraform’s authority layer was already missing.
Authority debt is the layer most teams discover last and underestimate most. It is the direct precursor to what the Shadow Control Plane post will describe in detail: the console access, the manual overrides, the emergency paths that accumulate outside the declared governance model until they become the actual operating model. Terraform becomes one input among several — the declared one, but not necessarily the authoritative one. At the GitOps layer, this authority erosion has a second expression: the pipeline enforces policies whose original justification has expired, producing governance failures that look like clean reconciliation — the failure mode Framework #133 — Policy Intent Drift names.
Where the Debt Surfaces: Three Failure Patterns
Operational inheritance debt does not surface uniformly. It surfaces through specific failure patterns that are recognizable once you know what you are looking at.
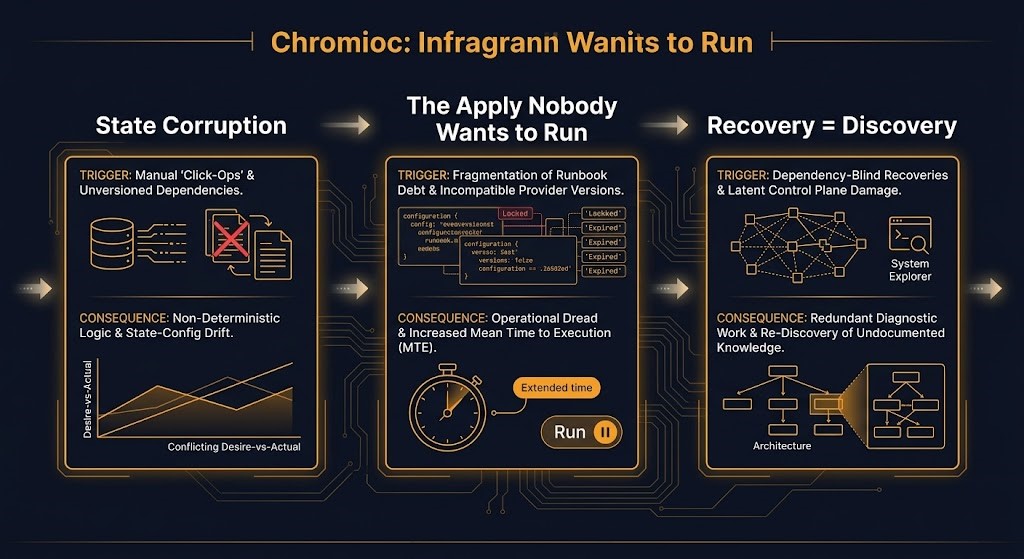
State Corruption Under Concurrent Apply
This is the failure pattern that the remote backend with state locking was designed to prevent — and it still happens, because state locking only works if every path that can modify infrastructure uses it. The second CI system with apply capability, the engineer who runs a local apply to “just fix one thing,” the automation job that bypasses the pipeline during an incident: each one is a concurrent write risk. State corruption does not announce itself. It accumulates as drift — resources that exist in infrastructure but not in state, state entries that point to resources that no longer exist, and planned changes that include destruction of things that should not be destroyed because the state does not reflect current reality.
The Apply Nobody Wants to Run
This is the most recognizable signal of Terraform operational maturity failure. Every team has one — an apply that nobody will run without a full team callout, a maintenance window, and several hours of pre-work. The plan output is unpredictable. Provider drift means the resource schema may have changed since it was last applied. Module behavior under the current configuration is uncertain. The destroy implications are unknown because the dependency graph was never documented. State uncertainty has accumulated long enough that the blast radius of any apply is genuinely unclear.
The apply still gets run, eventually — because something breaks and there is no other path to fix it. That is when the debt collection begins.
⚠ FAILURE SIGNAL
If your team discusses “who should run the apply” before running it — not for approval reasons, but because everyone is hoping someone else takes the risk — the apply is already a failure mode. The social friction is the diagnostic. The technical debt is what created it.
The Recovery Operation Becomes the Discovery Operation
This is the most expensive pattern. During an incident, the team needs to understand the current infrastructure topology to make a recovery decision. They open the Terraform configuration. It does not match what is running. The state file has entries for resources that were decommissioned manually. The module that manages the failing component was last applied fourteen months ago against a provider version that has since been upgraded twice. The apply output shows changes nobody intended.
The recovery operation becomes the discovery operation. The team is learning what the infrastructure actually is at the same moment they need to be fixing it. The outage window extends not because the fix is complex, but because the team cannot establish the baseline needed to apply it safely.
This pattern is what makes Terraform Day 2 operations debt a resilience problem, not just a hygiene problem. The debt you defer in normal operations becomes the constraint that limits your recovery speed under pressure. It is the same class of accumulated operational fragility described in The Control Plane Problem in VMware Alternatives — invisible in stable operation, catastrophic when the environment demands a clear source of operational authority.
The Audit You Should Run Before You Touch Anything
The correct response to inheriting a Terraform codebase is not to start refactoring. It is to understand what you actually have. Refactoring before visibility produces the apply nobody wants to run at larger scale.
The audit is a visibility exercise. Run it first, change nothing, and build a picture of the Operational Inheritance Surface before you touch any of the layers.
Pre-Touch Audit Checklist
- State file inventory — how many state files exist, where are they stored, are they in remote backends with locking enabled, are there local state files in the repo
- Provider version map — which providers are in use, at which versions, what is the current release, and what breaking changes have accumulated in the gap
- Module dependency graph — which modules are called from where, which modules have multiple callers, which have no documented interface
- Last-applied timestamps — which workspaces have not been applied in more than 90 days; these are the highest-risk applies
- Drift surface — run
terraform planon each workspace without applying; document every change it proposes as a map of where declared state has diverged from runtime reality
The fifth item is the most important. The plan output without an apply is your current ground truth on drift. Every proposed change is a gap between what Terraform thinks is deployed and what is actually running. Some of those gaps are intentional. Most are not. None of them are documented.
The audit’s most important question is not technical — it is operational: where does authority actually live?
AUTHORITY AUDIT
“Which systems can mutate this infrastructure outside of Terraform? Which teams bypass the pipeline? Which applies require tribal knowledge that is not in the codebase? Which resources were imported under pressure and never fully documented?”
These questions identify the authority debt layer — the gap between Terraform as declared governance and the actual operational reality your team is inheriting. Until you map it, you cannot assess the real blast radius of any change.
The Terraform Feature Lag Tracker gives you a concrete view of provider version drift — where your pinned versions sit relative to current releases and what breaking changes are queued in the gap. Run it against your provider inventory as part of the audit. Provider lag is the debt layer with the most predictable escalation path: it compounds silently until a security patch or a required feature forces an upgrade under pressure.
The Sovereign Drift Auditor addresses the next layer — operational divergence between declared and runtime state across your infrastructure boundary. If your audit surfaces significant authority debt, the drift auditor gives you a structured methodology for mapping it before you start reconciling it.
What Survivable Terraform Operations Actually Looks Like
There is a version of this conversation that turns into a best-practices essay about Terraform hygiene. That is not what this section is. Hygiene arguments miss the point. The problem is not that teams wrote messy Terraform. The problem is that they promoted Terraform into an operational authority system without designing it as one.
Survivable Terraform operations are not elegant. They are legible. A team member who did not write the codebase can pick it up at 2am during an incident and make a safe decision about what to apply and what to leave alone. That is the standard. Everything below it is debt.
The minimum viable characteristics of a Terraform codebase that achieves that standard:
Remote state with locking enforced across every apply path. Not just the primary CI pipeline. Every path that can write to state — local applies, break-glass procedures, secondary automation — uses the same remote backend with locking. A state conflict during incident recovery is not a Terraform problem. It is an operational design problem.
Explicit provider version constraints with a documented upgrade path. Not pinned-forever. Not unpinned. Constrained to a range with a defined process for testing and incrementing. The Modern Infrastructure & IaC Architecture pillar covers the full governance model for provider version management — including how the IaC Control Plane Model handles version authority across multi-team environments.
Module interfaces documented as contracts. The module’s inputs, outputs, expected behavior, and known limitations — written down, versioned, and updated when the module changes. A module without a documented interface is a liability, not a reusable component.
Apply runbooks that exist and are accurate. Not general Terraform documentation. Specific procedures for this codebase, in this environment, including the apply order for dependent workspaces, the pre-apply checks required, the variables that must be verified, and the rollback path if something goes wrong.
A single defined authority. Terraform is the authority, or it is not. If it is, console changes are reconciled back into state or into .tf files within a defined window. Manual patches during incidents are tracked and resolved before the next apply. If Terraform is not the authority — if the real answer is that it is one of several systems that can modify infrastructure — then that fact needs to be acknowledged, documented, and modeled. Operating as though Terraform is authoritative when it is not is how authority debt becomes catastrophic.
The goal is not elegance. The goal is survivable operations.
Architect’s Verdict
Terraform did not create your Day 2 operations problem. Your organization promoted Terraform into an operational authority system it was never designed to be, and then operated it as though the provisioning guarantees extended to operational clarity. They do not.
The Terraform Operational Inheritance Surface — state debt, provider version debt, module debt, runbook debt, and authority debt — is not a failure of the tool. It is the accumulated cost of years of provisioning-first decisions made by teams who had no reason to think about who would inherit the codebase or what that person would need to operate it safely under pressure. The debt is structural. It does not go away when the team changes. It transfers.
The teams that survive Terraform inheritance are not the ones with the cleanest codebases. They are the ones who mapped the debt before they touched it, defined where authority actually lives, and built for the 2am recovery scenario rather than the demo environment. The apply nobody wants to run is a diagnostic. The recovery operation that becomes a discovery operation is the consequence of ignoring it.
Terraform codebases outlive the teams that wrote them. Whether they outlive the next production incident is an operational design decision, not a provisioning one.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




