AI Inference Is the New Egress: The Cost Layer Nobody Modeled

You modeled compute scaling. You modeled storage durability. You built egress budgets into your cloud architecture because you learned — the hard way, or from someone who did — that data movement is never free.
You did not model AI inference cost.
Neither did most of the industry. Inference just crossed 55% of total AI cloud infrastructure spend in early 2026, surpassing training for the first time. And most of the teams running those workloads are still treating inference like a feature — something bolted onto an architecture that was designed for something else entirely.
It is not a feature. It is a tax. On every request your system makes.
Inference ≠ Training
The economics are completely different and teams keep conflating them.
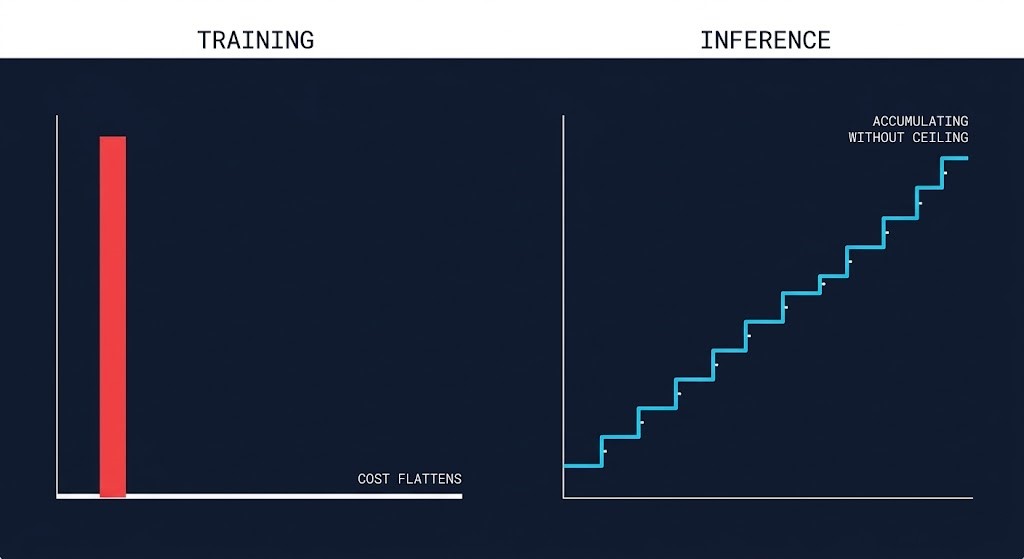
Training is a capital expenditure analog. You rent a large GPU cluster for days or weeks. The bill is large, visible, and bounded. You plan for it. You track it. You feel it once and move on.
Inference is the opposite. It is continuous operational expenditure — every API call, every token, every real-time pipeline invocation adding to the tab. The cost doesn’t come from a single spike. It accumulates through behavior, not provisioning.
That distinction breaks every forecasting model your finance team was using before AI entered the picture. You might budget for 1x compute and ship to production at 4x. The monitoring stack, logging layer, and drift detection running alongside the model often cost as much as the inference itself. None of that shows up in the initial architecture review.
The teams getting blindsided aren’t doing anything wrong operationally. They designed for the wrong cost model. This is the foundational failure that breaks traditional FinOps models — the cost authority moved to architecture time, and FinOps tooling operates at billing time. GTC 2026 formalized this distinction at the hardware level — for the first time, NVIDIA shipped dedicated inference silicon alongside training hardware as separate systems. The architectural implications are mapped in The Training/Inference Split Is Now Hardware.
The Three Cost Drivers Nobody Architected For
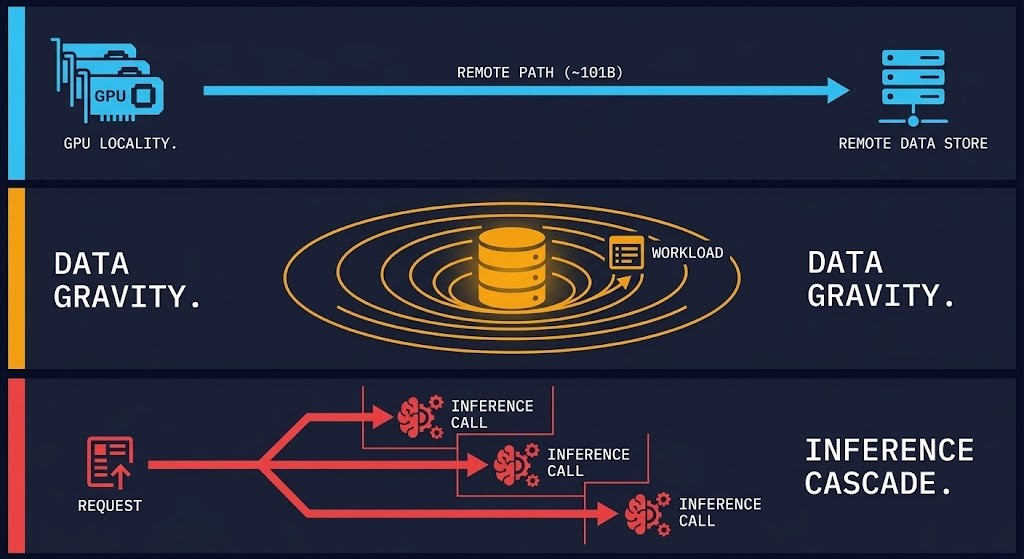
GPU locality. Where inference runs relative to your data is not an afterthought — it is an architecture decision with a direct cost consequence. A model served from a centralized GPU cluster in a region that’s 300ms from your data pipeline is not just slow. Every round trip is a billable event compounding across millions of requests. The AI Inference Saturation Analyzer surfaces where that compounding accelerates — the concurrency knee beyond which each additional request produces disproportionate latency and cost amplification.
Data gravity. Your data already lives somewhere. It has gravity — it pulls workloads toward it, and it penalizes workloads that run far from it. Cloud-native architectures built around regional redundancy and geographic distribution were not designed around AI data gravity. When your inference pipeline is constantly pulling training context, retrieval augmentation, and feature data across zones, you are paying egress rates on AI infrastructure that has no budget line for egress.
Cross-zone and cross-cloud inference cascades. Agentic architectures — AI systems that trigger additional inference calls as part of their execution — don’t produce a single cost event. One request can cascade into many. An agent that calls a retrieval service in one zone, a scoring model in another, and an output formatter in a third has turned a single user action into a distributed cost event that no static budget line captures.It’s also why Kubernetes is not an LLM security boundary — by the time a cascade reaches your infrastructure, the enforcement window has already closed.
This is the core problem: AI inference cost emerges from behavior, not provisioning. You cannot govern it the way you governed EC2 spend. Once inference reaches production, it becomes a permanent operational floor — not a workload you can scale down between usage spikes. Inference steady state cost explains why warm capacity, concurrency reservation, and serving infrastructure create a residency footprint that never decays naturally.
Why Cloud-Native Architectures Break Here
Traditional cloud architecture was built for a specific set of assumptions: human-initiated requests, deterministic execution paths, cost that scales predictably with load. Those assumptions held for over a decade. They do not hold for inference workloads.
Chatty AI workloads. A single agentic task can trigger dozens of inference calls — retrieval, reasoning, validation, output formatting. Each one is a discrete billable event. The architecture doesn’t see a workload; it sees traffic. The bill sees something entirely different.
Real-time pipelines. Low-latency inference pipelines sitting on cloud infrastructure designed for variable, bursty traffic are paying reserved-instance rates for continuous, predictable load — exactly where on-premises economics flip. Cloud is optimal for experimentation and spikes. When GPU usage becomes continuous and predictable, the math reverses.
Stateless autoscaling assumptions. Kubernetes and container orchestration were designed to scale stateless workloads horizontally. Inference workloads are not stateless. KV-cache state, model context windows, and active session memory mean that spinning up a new pod doesn’t just add capacity — it resets state, breaks context, and forces cold-path inference at exactly the moment your architecture was trying to scale.
The architecture worked. For a different problem.
What the Architect Models Instead
The fix is not a different cloud provider. It is a different architectural model — one that treats inference cost as a first-class runtime property, not a billing report you review after the fact.
Inference placement is a design constraint. Where a model runs — cloud region, edge node, on-premises cluster — should be determined by a latency/cost/volume matrix, not by where your existing compute happens to live. Latency-sensitive, high-volume, continuous workloads belong closer to data. Variable, experimental, bursty workloads belong in elastic cloud. The decision needs to happen at architecture time, not after the first unexpected invoice. Increasingly that decision is also a capacity question, not just a cost one — the placement matrix assumes the GPU capacity you’re routing toward is actually available on the timeline your workload needs, and that assumption is exactly what’s breaking as reservation queues stretch into quarters.
Cost-aware routing at the model layer. Not every inference call requires the most capable model. Routing low-complexity requests to smaller, cheaper models — and reserving premium compute for high-value decisions — is an architectural pattern, not a FinOps afterthought. Teams that build this in from day one report dramatically different cost trajectories than teams that add it reactively — and the reason reactive FinOps fails on AI workloads is structural, not operational.
Execution budgets, not just instance budgets. Static project budgets don’t govern autonomous systems. The architecture needs execution budgets — constraints on how much work an agent or pipeline can perform, enforced at token, step, or time boundaries during runtime. If the budget enforcement lives only in a billing dashboard, it is already too late.
Observability at the inference layer. You cannot optimize what you cannot attribute. Inference-level observability — tracking token usage, model selection, context size, and invocation frequency per agent or workflow — is the prerequisite for every other cost control. Visibility is not control, but without visibility at the decision layer, control is impossible. Teams that implement this consistently report improved ability to tie AI spend to business outcomes rather than treating it as opaque overhead. The operational infrastructure that makes inference-layer observability sustainable at scale — cost governance signals, runtime drift detection, and LLMOps tooling — is the architectural layer covered in Operations & LLMOps Architecture.
Architect’s Verdict
Egress cost was the last hidden tax that caught cloud architects off guard at scale. The industry learned to model it — eventually. Budget lines got built. Architecture reviews started asking egress questions. The bill became predictable.
AI inference cost is the same lesson, arriving faster.
The teams that will control it are not the ones running tighter FinOps processes on their existing architecture. They are the ones who redesigned how they think about cost — from a provisioning problem to a behavior problem, from a billing report to a runtime constraint.
Inference is not a feature. It is the new egress. Model it like one.
The AI Infrastructure pillar covers GPU placement strategy, inference architecture, and the cost decisions most teams make too late. Start with the full pillar overview.
Explore AI Infrastructure →Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session