MICROSERVICES ARCHITECTURE
The practitioner guide to microservices architecture — service boundary design, data ownership, consistency models, failure isolation, and the honest operational reality.
Microservices architecture is not about splitting applications into smaller pieces. It is about isolating failure and ownership boundaries so that one team’s decision cannot cascade into another team’s incident.
That distinction matters architecturally. Most microservices failures — the distributed monoliths, the shared database anti-patterns, the cascading timeouts — trace back to treating decomposition as a technical exercise rather than an organizational and operational commitment. You can split a monolith into fifty services and end up with a system that is harder to operate, slower to change, and more expensive to run than the monolith you replaced. The split is not the point. The boundaries are.
A cloud native architecture done correctly gives you independent deployability — the ability to change, test, and release one service without coordinating with every other team. It gives you failure containment — the ability to degrade one capability without taking down the system. It gives you data ownership — the ability for each service to evolve its persistence model independently without a shared schema becoming the bottleneck. These are the outcomes microservices exist to produce. The service count is a side effect.
This guide covers service boundary design, data ownership, consistency models, communication patterns, failure isolation, observability, operational cost, and the honest decision framework for when microservices are the right architecture — and when they are not.
What Microservices Actually Are
Microservices are defined by architectural discipline, not service count.
The term is misleading. “Micro” suggests size. The relevant property is not how small a service is — it is how independently it can be owned, deployed, and failed. A single-function service that shares a database with five other services is not a microservice. It is a monolith with extra network hops. A service with ten thousand lines of code that owns its data, exposes a versioned API, and can be deployed without coordination is a microservice.
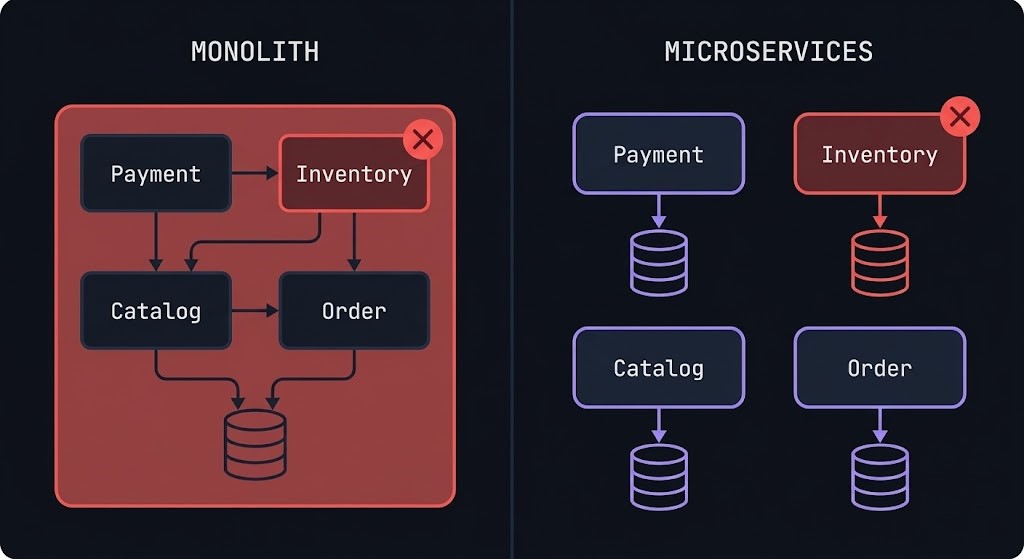
Monolith vs Microservices Comparison Table
The monolith is not the enemy. It is often the right starting point. The decision to decompose is a function of organizational scale, change frequency, and operational maturity — not architectural ideology.
Service Boundary Design
Where you draw the boundary determines everything.
A microservices boundary drawn in the wrong place produces a distributed monolith — the worst of both worlds. Services that are technically separate but logically coupled: they share databases, they make synchronous calls to each other in every request path, and they cannot be deployed independently because a change to one requires a coordinated release of several others. The operational overhead of microservices without the independence benefits.
Domain-Driven Design (DDD) provides the conceptual framework for boundary design. The core concept is the bounded context — a logical boundary within which a domain model has a consistent, unambiguous meaning. Inside a bounded context, “Order” means one specific thing with one specific data model. Outside that boundary, “Order” may mean something different in a different context. The boundary prevents that semantic ambiguity from leaking across services.
The practical heuristic for boundary design: a service boundary should align with a team boundary. If the same team owns two services, they are probably one service with extra deployment complexity. If two teams share ownership of one service, the boundary is in the wrong place. Conway’s Law — systems tend to mirror the communication structure of the organizations that build them — is not a warning. It is a design principle. Design your service boundaries to match your organizational communication structure, and the architecture will follow.
High coupling across service boundaries is the leading indicator of a boundary drawn in the wrong place. Symptoms: a change to Service A requires a coordinated release of Services B and C. Service A makes synchronous calls to Service B on every request. Service A and Service B share a database table. Any of these indicates that the boundary needs to be redrawn — either by merging the services or by re-decomposing around a different domain boundary.
The Strangler Fig pattern provides the operational approach for redrawing boundaries in production systems without a big-bang rewrite.
Data Ownership
The shared database is where microservices go to die.
The most common microservices failure pattern: correct service decomposition at the API layer, with all services reading from and writing to a single shared database. The services are independently deployable in theory. In practice, a schema change for Service A requires coordination with every other service that reads the same tables. The shared database becomes the coupling point that microservices exist to eliminate.
The rule is absolute: each service owns its own data store. No other service reads directly from another service’s database. Data is exposed only through the owning service’s API. This constraint is operationally uncomfortable — it eliminates the JOIN across service boundaries that developers reach for naturally — but it is the constraint that makes independent deployability real.
Polyglot persistence is the corollary: because each service owns its data store, each service can choose the persistence model that fits its domain. The order service uses a relational database for transactional consistency. The product catalog uses a document store for flexible schema evolution. The recommendation engine uses a graph database for relationship traversal. The session store uses Redis for sub-millisecond access. Each service selects the right tool for its specific access patterns rather than being constrained by a single shared schema.
The data patterns that microservices require:
API Composition — when a request requires data from multiple services, the data is assembled by making API calls to each owning service and composing the result in an orchestration layer or the calling service. No cross-service database joins.
Event Sourcing — service state is stored as an immutable sequence of events rather than current state. Other services can subscribe to the event stream and maintain their own read models derived from those events. This enables eventual consistency without tight coupling.
CQRS (Command Query Responsibility Segregation) — the write model and the read model are separated. Commands modify state through the owning service. Queries against aggregated data use read-optimized views maintained by consuming services from event streams. This pattern is particularly valuable when read performance requirements differ significantly from write requirements.
Consistency & Transactions
Microservices trade consistency for independence. If you do not design for that trade, the system will fail unpredictably.
In a monolith with a shared database, a multi-step operation — debit account, reserve inventory, create order — executes in a single ACID transaction. If any step fails, the database rolls back all changes atomically. The system is always consistent.
In a microservices architecture, those three steps span three services with three separate databases. There is no distributed transaction that can provide ACID guarantees across all three. If the inventory reservation succeeds but the order creation fails, the system is in an inconsistent state — and no rollback can fix it automatically.
Distributed transactions are the wrong answer. Two-Phase Commit (2PC) provides distributed atomicity, but at the cost of tight coupling, blocking locks, and a coordinator that becomes a single point of failure. At scale, 2PC introduces exactly the coupling that microservices exist to eliminate. Avoid it.
The Saga Pattern is the correct approach. A saga is a sequence of local transactions — one per service — where each step publishes an event that triggers the next step, and each step has a compensating transaction that can undo it if a subsequent step fails.
Eventual consistency is the operating model for data that must be shared across service boundaries. Service A updates its data store and publishes an event. Service B consumes the event and updates its own read model. For a window of time — milliseconds to seconds under normal conditions — Service B’s view of that data is stale. This is acceptable if the business domain tolerates it. Most domains tolerate more eventual consistency than engineers initially assume.
Service Communication & Coordination
Every service call is a potential failure point. Design for it.
Synchronous communication — REST and gRPC — is the natural model for request/response interactions where the caller needs an immediate answer. REST over HTTP is the default for external-facing APIs and inter-service calls that are latency-sensitive. gRPC provides better performance and strongly-typed contracts through Protocol Buffers — preferred for internal service-to-service communication in performance-sensitive paths. The Kubernetes ingress and Gateway API migration covers the routing layer that handles synchronous service traffic at the cluster boundary.
Synchronous communication creates temporal coupling: the caller cannot proceed until the callee responds. Timeouts, retries, and circuit breakers are the operational response to this coupling — not optional patterns but foundational requirements for any synchronous service call in production.
Timeout configuration is the most commonly neglected synchronous communication concern. Every service call must have a timeout. A service call without a timeout can hold a thread indefinitely, exhausting the caller’s thread pool and causing cascading failures that look unrelated to the downstream slowness that caused them. Timeouts must be set at every layer of the call chain and must be shorter upstream than downstream to prevent timeout storms.
Retry logic with exponential backoff and jitter prevents thundering herd problems when a downstream service recovers from a failure. Idempotency is the prerequisite for safe retries: an operation is idempotent if executing it multiple times produces the same result as executing it once. Non-idempotent operations — creating an order, processing a payment — must be made idempotent through idempotency keys before retries are safe.
Circuit Breakers prevent cascading failures from propagating through the service graph. When a downstream service is failing or slow, a circuit breaker opens — short-circuiting calls to that service and returning a fallback response immediately. The service mesh vs eBPF architecture covers how circuit breaking and traffic policy can be enforced at the network layer through Istio, Linkerd, or Cilium — without application code changes.
Failure Domains & Blast Radius
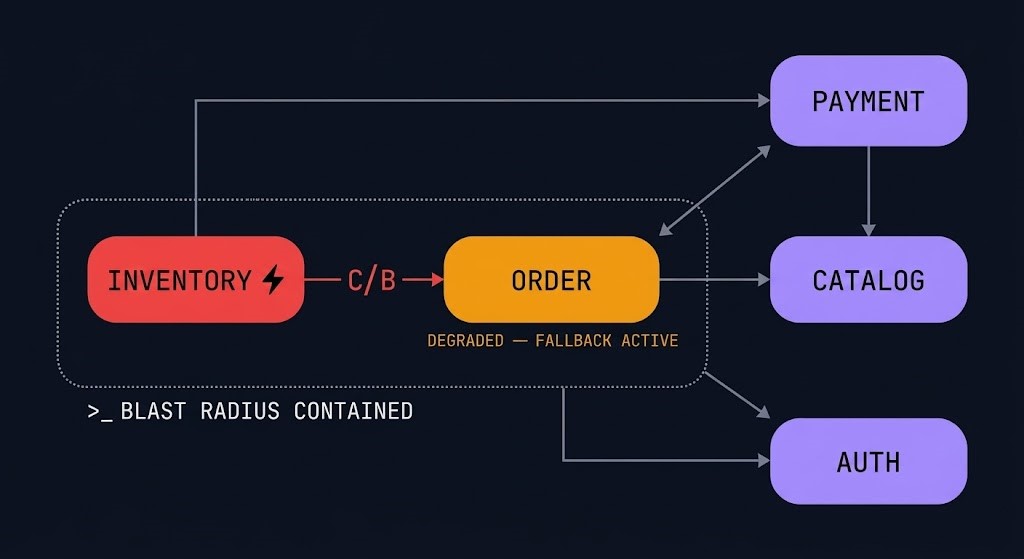
A microservices architecture that does not contain failures is more fragile than the monolith it replaced.
The promise of microservices is that a failure in one service does not bring down the system. That promise requires explicit design. Without it, the interconnected network of service calls creates a failure surface that is larger and more complex than a monolith’s single process boundary.
Blast radius is the measure of how much of the system is affected when a specific service fails. Correctly bounded blast radius means that the payment service failing degrades checkout but does not affect product search, user authentication, or order history. The Kubernetes Day-2 failure patterns document exactly how blast radius failures surface in production clusters — and why the symptom layer is almost always misleading.
Bulkheads partition service resources to prevent one service’s failures from consuming resources needed by other services. Thread pool isolation: give each downstream dependency its own thread pool. When the inventory service is slow and its calls are timing out, the threads blocked waiting for inventory do not consume the threads available for payment calls.
Graceful degradation is the operational contract that makes blast radius containment real. When the recommendation service is unavailable, the product page renders without recommendations rather than returning an error. When the inventory service is slow, the add-to-cart flow continues with optimistic inventory rather than blocking the user. The system defines, for each service dependency, what the degraded behavior looks like — and ensures that degraded behavior is acceptable rather than failing.
Timeout budgets across the service call chain must be coordinated. If Service A calls Service B which calls Service C, and A’s timeout is 100ms, B’s timeout must be less than 100ms, and C’s timeout must be less than B’s timeout. Staggered timeout budgets with appropriate margin at each layer prevent cascading timeout storms.
Observability & Debugging
Microservices fail in ways monoliths do not. You cannot debug a distributed system with logs from one service.
In a monolith, a single request execution trace exists in one process. The call stack is visible. The log output is sequential. In a microservices architecture, a single user request may touch fifteen services, generate log entries in fifteen separate logging systems, and fail at service seven with a symptom that surfaces at service two. Without distributed tracing, diagnosing that failure means correlating log entries across fifteen systems manually — an operational exercise that does not scale.
Distributed tracing is the observability capability that makes microservices debuggable. A trace is a complete record of a request’s journey across service boundaries. A span is one step in that journey. Correlating spans into traces across service boundaries requires a trace context header that each service passes to downstream calls. The containerd Day-2 failure patterns cover how runtime-layer failures propagate upward — and why distributed tracing is the only way to see the full failure chain.
OpenTelemetry is the standard for distributed tracing instrumentation — vendor-neutral APIs, SDKs, and a collector that receives telemetry data and exports it to tracing backends (Jaeger, Zipkin, Tempo, Datadog, Honeycomb). OpenTelemetry’s adoption across languages and frameworks means that instrumentation is consistent regardless of the technology stack of each service.
Correlation IDs are the minimum viable tracing requirement. Every request that enters the system receives a unique identifier. Every service logs that identifier with every log entry. The correlation ID provides the join key to correlate log entries across all services that handled the request.
Partial failures are the hardest class of microservices failures to diagnose. The system is not down. Some users are experiencing errors. Some requests are slow. Distributed tracing catches partial failures because it records individual request traces including the failed ones — allowing you to query for the failures and see exactly where in the service graph they diverged.
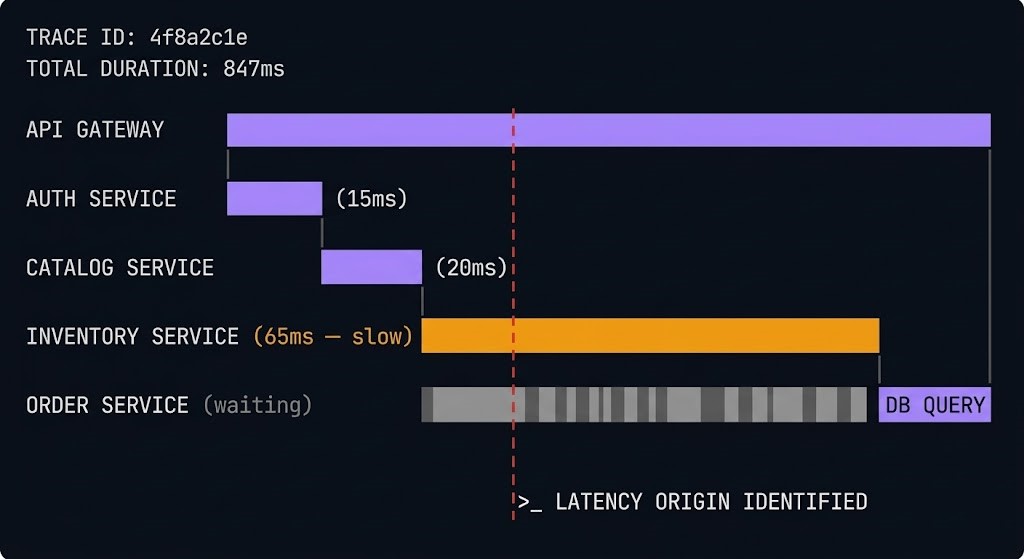
Operational Overhead & System Complexity
Microservices increase operational complexity. This is not a warning that can be engineered away — it is a fundamental property of the architecture. The platform investment required to manage that complexity — golden paths, internal developer portals, self-service infrastructure — is covered in the Platform Engineering Architecture pillar.
Cost Physics
Microservices can be cheaper than monoliths at scale. They are almost always more expensive at small scale.
The break-even point — where microservices cost model improves over monolith — is approximately where selective scaling savings exceed observability and platform overhead. In practice, this is around ten to twenty services with meaningfully heterogeneous load patterns. The same economics that make microservices cost-efficient at scale apply to AI inference workloads — bin-packing and selective scaling compound more dramatically when GPU resources are involved.
Migration Strategy — The Strangler Pattern
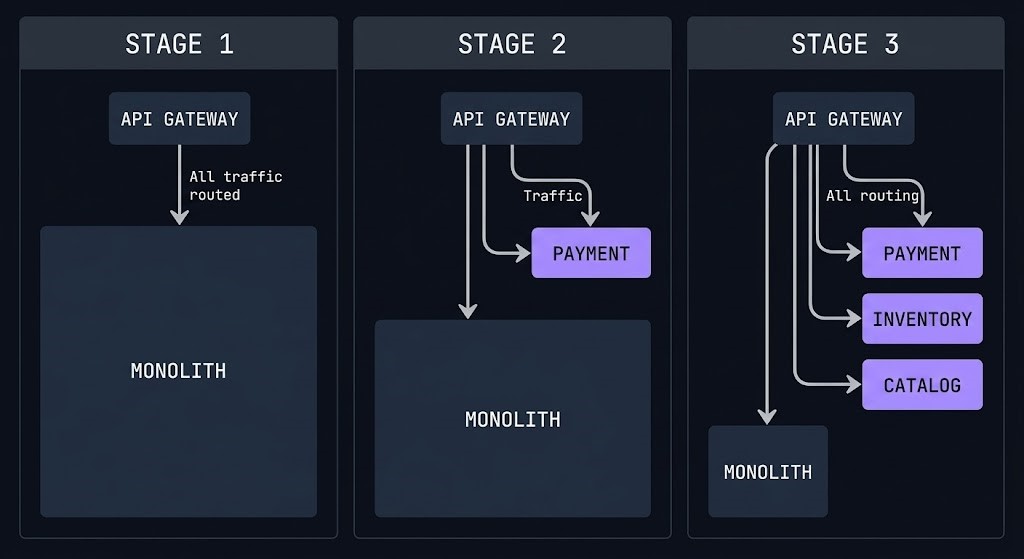
Do not rewrite. Strangle.
The big-bang microservices rewrite — stop development on the monolith, spend eighteen months rebuilding everything as services, deploy — is the most reliable path to project failure. The Strangler Fig pattern provides the alternative: incrementally extract functionality from the monolith into services, routing traffic to the new service as each extraction completes, until the monolith is empty.
For teams making the transition from VM-based monoliths, the Kubernetes VMware exit ramp covers the architectural approach to running extracted services on Kubernetes while the legacy VM estate continues on its own schedule.
The five-step extraction sequence:
Step 1 — Identify the extraction candidate. Choose functionality with a clear boundary, stable API, and moderate internal coupling. Start with a read-heavy capability that does not require distributed transactions.
Step 2 — Build the service alongside the monolith. The new service is built and tested while the monolith continues to run. No user traffic routes to the new service yet. No production risk.
Step 3 — Deploy an API façade or gateway in front of the monolith. Initially passes everything through to the monolith unchanged. When the new service is ready, routes relevant traffic to the new service.
Step 4 — Migrate data ownership. The new service needs its own data store. The monolith’s data migrates through dual writes during transition, through event sourcing, or through a one-time migration with a cutover window.
Step 5 — Decommission the monolith functionality. Once the new service handles all traffic for the extracted domain, the corresponding code in the monolith is removed. The monolith gets smaller. Repeat.
Workload Decision Table
When Microservices Architecture Is the Right Call
When organizational structure already has clear team ownership of distinct business capabilities, microservices align the architecture with the organization. Conway’s Law works in your favor — design your service boundaries to match your communication structure.
When multiple teams need to release independently — when the catalog team cannot wait for the payment team’s release cycle — microservices provide the independence that makes that possible. The break-even appears where release coordination becomes the bottleneck to delivery velocity.
When different parts of the system have materially different load profiles — search is CPU-intensive and spiky, checkout is latency-sensitive and bursty — selective scaling in a microservices architecture reduces infrastructure cost relative to scaling a monolith for the combined peak.
For systems that will evolve over years, independently evolvable service boundaries allow domain models to change without cascading refactoring across the entire codebase. The independence compounds over time — the longer the system runs, the more the independent evolvability pays off.
When to Consider Alternatives
A team of five engineers building a single product with stable requirements does not need microservices. The platform engineering overhead costs more in engineering time than the independence benefit returns. Start with a well-structured monolith. Decompose when the pressure requires it.
If you do not know where the domain boundaries are — if the business capabilities are still being discovered — you will draw the wrong service boundaries. Wrong boundaries in a microservices architecture are expensive to fix. Draw them when you know where they belong.
Microservices amplify operational capability. They do not create it. Without established CI/CD practices, without distributed tracing, without observability culture — microservices add complexity faster than they add velocity. Build operational discipline first.
Domains where strong transactional consistency is a hard requirement across multiple business capabilities — financial ledgers, inventory systems with zero-tolerance for overselling — are difficult fits. Identify the consistency requirement before the decomposition, not after.
Decision Framework
You’ve covered microservices architecture — decomposition patterns, inter-service communication, and the operational tradeoffs at scale. The pages below cover what surrounds it: the orchestration layer that runs your services, the security model that governs them, and the mesh that connects them.
Architect’s Verdict
Microservices are not a solution to a technology problem. They are a solution to an organizational problem — the problem of teams that cannot move independently because the system does not allow it.
Done correctly, microservices give you independent deployability, selective scaling, bounded failure blast radius, and the ability for each team to evolve their domain without coordinating every change with every other team. Done incorrectly — with shared databases, incorrect boundaries, insufficient observability, and no platform investment — they give you all the operational overhead of distributed systems with none of the independence benefits.
The boundary is everything. Draw it in the wrong place and you have built a distributed monolith that is harder to operate than the original. Draw it correctly — aligned with domain ownership, with each service controlling its own data and exposing it only through versioned APIs — and you have built a system where one team’s incident cannot become every team’s incident.
The test is not the service count. The test is independent deployability: can you release one service without touching another? If the answer is yes, the boundaries are right. If the answer is no, the boundaries are wrong — regardless of how many services you have.
You’ve Designed the Services.
Now Audit What Actually Runs in Production.
Service boundaries, inter-service communication patterns, distributed tracing, and failure isolation — microservices that look correct in design reviews fail in production for different reasons. The triage session audits your specific architecture against real failure modes.
Microservices Architecture Audit
Vendor-agnostic review of your microservices architecture — service boundary design, inter-service communication patterns, failure isolation mechanisms, observability coverage, and the decomposition decisions that are creating operational debt rather than reducing it.
- > Service boundary and domain model review
- > Inter-service communication and circuit breaker audit
- > Distributed tracing and observability gap analysis
- > Failure isolation and blast radius assessment
Architecture Playbooks. Every Week.
Field-tested blueprints from real microservices environments — decomposition failures, distributed tracing blind spots, service mesh adoption patterns, and the inter-service communication anti-patterns that turn microservices into a distributed monolith.
- > Service Decomposition & Domain Design
- > Distributed Observability & Tracing Patterns
- > Service Mesh & Communication Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is the difference between microservices and a monolith?
A: A monolith is a single deployable unit where all functionality is packaged and released together. A microservices architecture decomposes that functionality into independently deployable services, each owning its own data and exposing its capabilities through versioned APIs. The operational difference is deployment independence — in a monolith, releasing one feature requires releasing everything. In a microservices architecture, each service releases on its own schedule. The cost of that independence is operational complexity: distributed tracing, API versioning, eventual consistency management, and platform engineering overhead that a monolith does not require.
Q: Do microservices always require Kubernetes?
A: Kubernetes cluster orchestration is the dominant platform for production microservices and the platform that most tooling assumes. Microservices can run on other platforms — serverless functions, managed container services, traditional VMs with service discovery. But the scheduling, scaling, health checking, and service discovery capabilities that Kubernetes provides align closely with what microservices require operationally. In practice, production microservices at scale run on Kubernetes or a Kubernetes-compatible platform.
Q: What is the biggest mistake teams make when adopting microservices?
A: Sharing a database. The shared database eliminates the data ownership that makes independent deployability real. Services that share a database cannot evolve their data models independently, cannot be deployed without coordinating schema migrations, and cannot achieve the blast radius containment that microservices exist to provide. The rule is absolute: each service owns its own data store, and exposes data only through its API.
Q: When should you not use microservices?
A: When the organizational and scaling pressure that microservices solve does not exist. Small teams building single products with stable requirements do not need the platform overhead that microservices require. Unknown domain boundaries drawn prematurely become expensive structural debt. Teams without CI/CD practices and observability culture will find that microservices add complexity faster than they add velocity.
Q: How do you handle transactions across microservices?
A: With the Saga pattern — a sequence of local transactions where each step publishes an event triggering the next step, and each step has a compensating transaction that can undo it if a subsequent step fails. Distributed transactions (Two-Phase Commit) provide atomicity across services but introduce tight coupling and a coordinator single point of failure that is architecturally incompatible with microservices independence.
Q: What observability do microservices require?
A: Distributed tracing with OpenTelemetry is the non-negotiable minimum. Logs from individual services cannot be correlated across service boundaries without a trace context. Complement with metrics (Prometheus) for aggregate performance visibility and structured logs with correlation IDs for event-level context. Without distributed tracing, debugging production failures in a microservices architecture is a manual, multi-system investigation that does not scale.