Configuration Drift: Enforcing Infrastructure Immutability
The ClickOps Virus & The Thermodynamics of Drift
Any system that lets in entropy—really, any manual human tweak—starts falling apart sooner or later. It always seems harmless at first. A senior engineer logs in at 2 AM for a hotfix. A junior admin tweaks a firewall rule from the Amazon Web Services (AWS) console. Someone triggers an emergency scale-out right in the Microsoft Azure portal. That leftover memory snapshot in VMware vCenter? Yeah, nobody remembers who left it there.
This is how “ClickOps” spreads—a kind of silent infection. Every time you make a change by clicking through a GUI or typing into a terminal instead of running it through a pipeline, you create a gap between what you think your infrastructure is and what’s actually out there.
Authority vs. Reality (State Physics)
If you want to understand why drift is such a big deal, you have to get the idea of the Authoritative State Boundary.
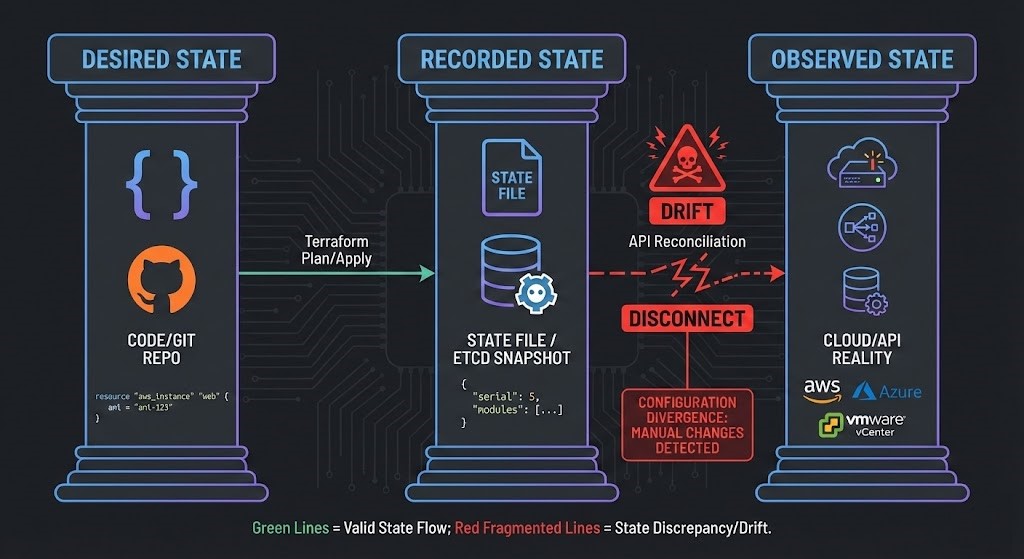
Infrastructure as Code (IaC) is built on three layers of truth:
- Desired State: The code you wrote—Terraform files, Kubernetes manifests, whatever.
- Recorded State: What your tooling keeps track of—
terraform.tfstate, etcd, all that. - Observed State: What’s really running—the actual state in the cloud or on your hypervisor.
State isn’t just configuration. It’s a contract. And when things drift, a simple deployment can turn into a ticking time bomb.
Imagine someone tweaks a load balancer by hand to pass an audit, but never updates the state file. Next time you run a terraform apply, the tool tries to “fix” the difference. Depending on your resource lifecycles, this could mean an in-place update, a forced replacement, or even a full cascade of destruction and recreation. That manual fix? Gone. Dependencies? Broken. Production stability is now at risk. (This exact mess is why we drew such hard lines in our open-source Terraform State Migration Kit).
The Drift Taxonomy
Drift isn’t just one thing. If you want to get rid of it, you have to break it down.
- Type 1: Configuration Drift – Manual tweaks to parameters (changing a security group, memory size, or replica count).
- Type 2: Resource Drift – Creating stuff outside IaC (like orphaned EBS volumes or random VMs nobody’s managing).
- Type 3: Policy Drift – IAM or RBAC changes, or firewall exceptions that were supposed to be temporary but somehow never got cleaned up.
- Type 4: Version Drift – Running different module versions in Dev, Staging, and Production.
Drift as Hidden Technical Debt
Drift isn’t just annoying.
- It is undocumented architecture.
- Cannot be versioned.
- Cannot be tested.
- Cannot be rolled back.
- Cannot be migrated safely.
Why Drift Kills Multi-Cloud Strategies
Migration tooling assumes:
- Known resource inventory
- Accurate sizing
- Deterministic dependencies
- Stable security boundaries
Drift invalidates all four.
Migration tools expect your source to be clean and predictable. When drift creeps in, your capacity models don’t work, NUMA planning is off, and network segmentation assumptions break down.
Say someone manually resizes a VM to 16 vCPUs to handle a memory leak. Your migration from vSphere to AHV just picks up that bloated VM and brings it over, making everything less efficient. Or maybe you’ve got orphaned disks outside your state files—your FinOps cost models are already useless.
The Enforcement Loop: Detection vs. Reconciliation
To tackle drift, you need a two-part system.
A. The Detection Layer (Audit Mode)
You can’t fix what you can’t see. The detection layer is all about surfacing unauthorized changes—without blowing things up.
- Terraform Plan Audits: Schedule CI runs that alert you when something’s changed.
- Cloud-Native Auditing: Use tools like AWS Config or Azure Policy to constantly check the real state against what you expect.
But here’s the catch: Detection without enforcement is just theater. You’re watching, but you’re not actually fixing anything.
B. The Reconciliation Layer (Self-Healing Infra)
This is where you get real deterministic infrastructure. With tools like Argo CD or Flux, you move to a GitOps model.
Git becomes authority.
The cluster becomes derivative.
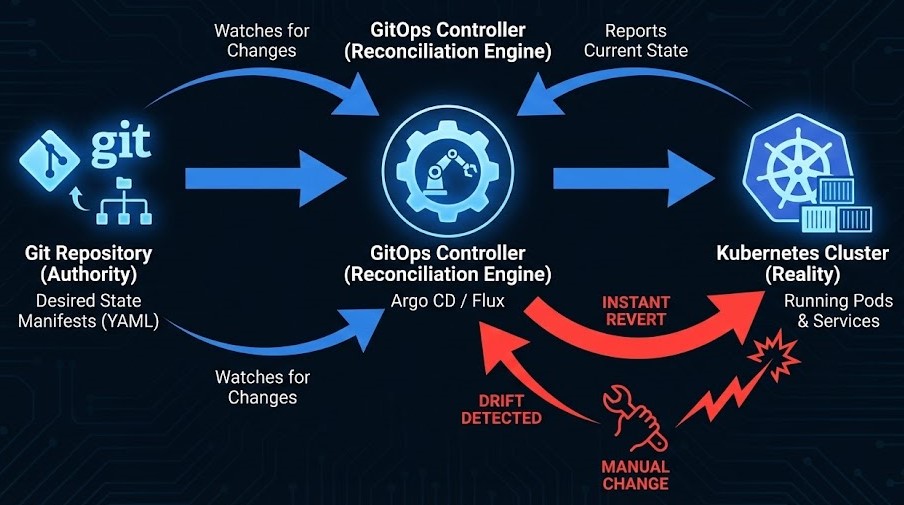
Here is how the math works in a GitOps model:
- Git is your authority.
- The cluster is your reality.
- The controller is your enforcement engine.
If an admin manually scales a deployment up to 10 pods because they are panicking about traffic, but Git says it should be 3, the controller notices the drift instantly and kills those 7 rogue pods. The system heals itself by aggressively enforcing the codebase.
⚠️ The Break-Glass Guardrail: Look, in real enterprise environments, emergency break-glass access has to exist for incident response. But those manual tweaks must be time-bound, aggressively audited, and automatically reconciled back to code the second the incident bridges close.
Blast Radius Modeling
Drift doesn’t just happen; it happens somewhere. The risk depends entirely on where that “somewhere” is.
- Development: Nuisance. You delay some local testing.
- Staging: Integration Risk. You get false positives when trying to validate for production.
- Production: Outage Risk. The application goes down.
- Shared Network/Compute Layer: Systemic Collapse. You take down multiple tenants.
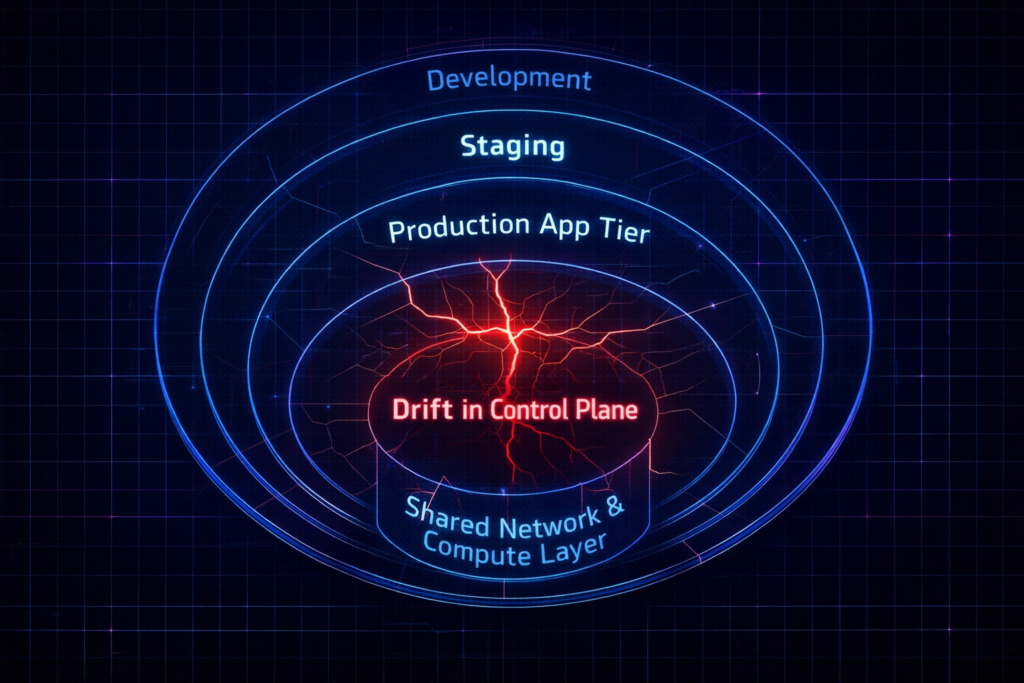
Think about that shared compute layer. If someone manually changes memory reservations on a big database VM, they throw off the host’s physical capacity. That hidden drift can trigger swap storms—something we dig into in Resource Pooling Part 2: The Physics of Memory Overcommit. Manual vCPU changes? They silently wreck your scheduler, spiking %RDY metrics (see Part 1: CPU Ready vs CPU Wait).
Whenever your underlying infrastructure gets out of sync, you’ll see performance tank across the board.
The Law of Production Immutability
If you let people make manual changes in production, you don’t have Infrastructure as Code. You just have “Infrastructure as Suggestions.”
The Law of Production Immutability:
- If you allow any mutation in production outside your pipeline, you’ve lost reproducibility.
- And when reproducibility is gone, well, you might as well be flying blind.
Drift Maturity Model
Drift isn’t binary. Organizations don’t jump from chaos to determinism overnight. They progress through predictable maturity stages — each reducing entropy and increasing architectural integrity.
| Level | Behavior | Risk |
|---|---|---|
| Level 0 | Full ClickOps | Unbounded entropy |
| Level 1 | IaC exists but manual edits allowed | High drift probability |
| Level 2 | Detection only | Delayed failure |
| Level 3 | Detection + Reconciliation | Deterministic infra |
| Level 4 | Immutable production + enforced pipelines | Architectural integrity |
The Architect’s Verdict
Stop logging into production to fix things. Lock down write access to the control plane. Emergency break-glass access must be time-bound, audited, and automatically reconciled back to code. Force every single change, no matter how small, through a pull request and a pipeline.
It will feel slow for the first two weeks. After that, 3 AM outages become explainable, reproducible, and resolvable — not mysterious.
Closing the Loop
To build this capability into your engineering teams, start with our Modern Infrastructure & IaC Learning Path. For senior teams ready to enforce these boundaries at scale, review the Modern Infrastructure & IaC Strategy Guide.
Finally, stop guessing what your reality looks like. Use the mathematical sizing and modeling tools available in our Custom Apps & Deterministic Tools hub to measure your physical infrastructure before you code it.
Additional Resources
- HashiCorp Docs: Managing State and Drift – The definitive guide on how Terraform calculates the delta between recorded and observed state.
- Argo Project: Argo CD Architecture – Deep dive into GitOps reconciliation loops and self-healing clusters.
- AWS Documentation: AWS Config Rules – Setting up continuous audit boundaries in the public cloud.
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




