Policy Translation: Mapping VMware DRS, SRM, and NSX to Nutanix Flow
Parts 01 through 03 of this series covered the physics of migration — execution model translation, controller resource contention, and I/O sequencing during cutover.
Those layers are measurable. Failures are visible in telemetry. Recovery protocols are deterministic.
This part covers the layer that is none of those things.
VMware environments accumulate policy logic over years of operation. DRS affinity rules. SRM recovery plans. NSX micro-segmentation. Storage policies. Host maintenance automation. These policies were authored incrementally — by architects who have since moved on, during incidents that created exceptions, and through compliance reviews that layered constraints on top of constraints.
The result is a policy stack that quietly encodes architectural intent nobody fully remembers.
When teams migrate off VMware, they move compute and storage. They verify the application boots. They confirm network connectivity. What they rarely verify — until the first real failure or DR test — is whether the behavioral logic of the platform migrated with it.
This is the vmware policy migration problem. It is quieter than a stutter event. It does not produce an immediate alert. But it is the reason environments that migrated cleanly continue to have incidents for months afterward.
Policy translation is the process of reconstructing the behavioral intent encoded in VMware DRS, SRM, and NSX configurations and re-expressing that intent using the equivalent mechanisms in the Nutanix platform. Translation is not feature mapping. The objective is not to find a Nutanix checkbox for every VMware checkbox. The objective is to preserve what the policy was designed to guarantee — placement integrity, failover sequence, and security boundary — using whatever mechanism the target platform provides to enforce that guarantee.
VMware Policy Is an Architecture Language
Before anything can be translated, the policy stack must be understood for what it actually is.
VMware policy is not configuration. It is accumulated architectural decision-making expressed in UI fields. Every DRS rule, every SRM plan, every NSX security group represents a decision someone made about how the environment should behave — often in response to a failure, a compliance requirement, or a performance constraint.
These layers are not independent. SRM boot order depends on which VMs are grouped together. NSX security groups depend on which VMs are in which tiers. DRS anti-affinity rules affect which nodes are eligible during HA failover. Remove one layer incorrectly and the others produce unpredictable behavior under failure conditions.
The architectural trap is treating vmware policy migration as a checklist task — exporting a DRS rule list and finding equivalent fields in Prism. That approach transfers configuration. It does not transfer intent. The distinction determines whether the environment holds together under failure.
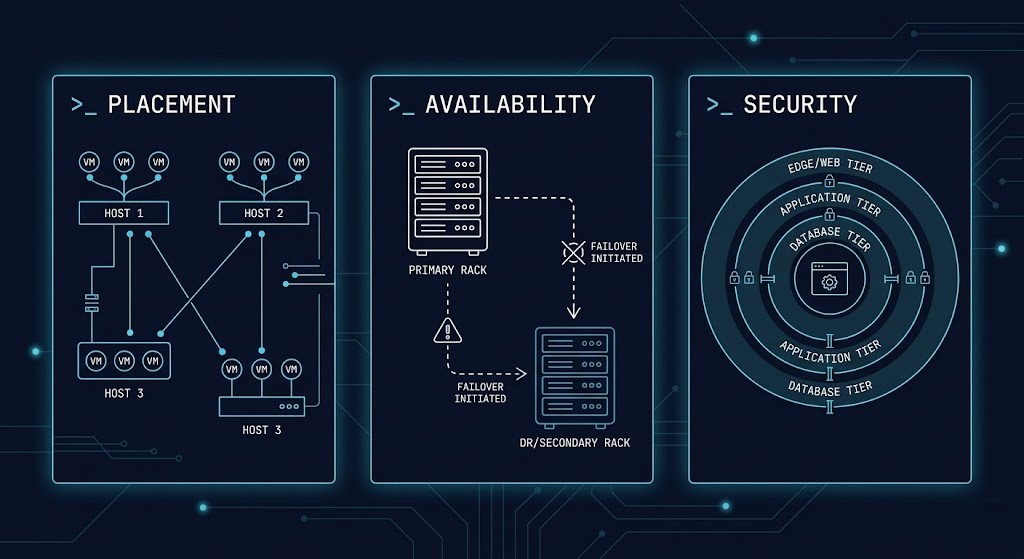
| Policy Layer | What It Encodes | Primary Tools |
|---|---|---|
| Placement | Where workloads run and which workloads may share resources | DRS affinity / anti-affinity |
| Availability | What happens during failure and in what order recovery proceeds | HA + SRM recovery plans |
| Security | Which workloads may communicate with which | NSX security groups + micro-segmentation |
DRS Affinity Rules — Translating Placement Intent
DRS rules in VMware fall into three categories. Each encodes a different type of architectural constraint and carries a different translation risk.
Keeps specific VMs on the same host. Used for latency-sensitive tiers, clustered applications requiring co-location, and licensing arrangements dependent on shared physical resources.
Keeps specific VMs on separate hosts. The canonical use case is availability — domain controllers, database replicas, and clustered nodes that must survive a single host failure.
Pins specific VMs to specific hosts or host groups. Used for software licensing tied to physical hardware, compliance isolation requirements, NUMA locality, and hardware-specific workloads.
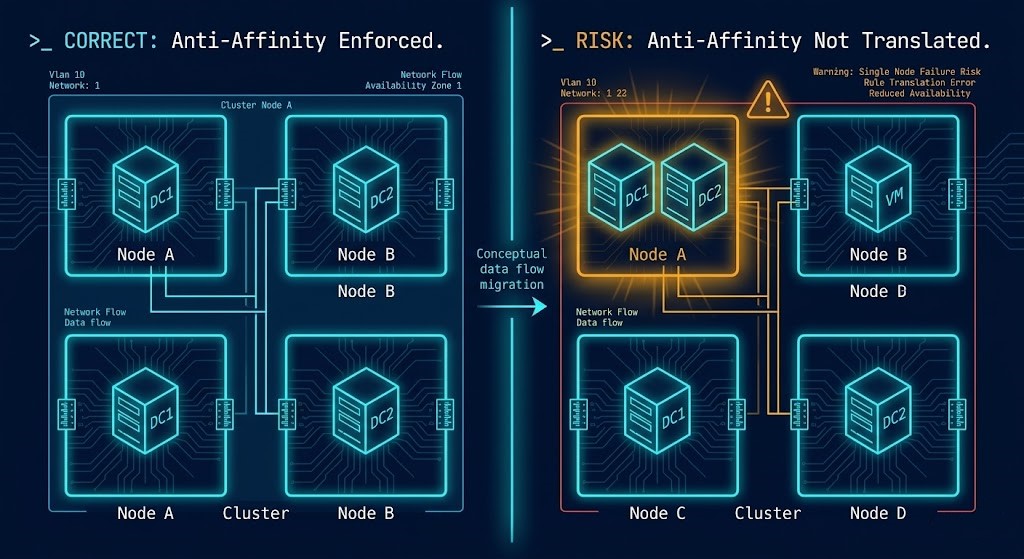
The most common DRS translation failure is not a misconfigured rule — it is the absence of a rule that was present in VMware and assumed to carry over implicitly.
Nutanix AHV’s scheduler is capacity-aware and locality-optimized. Under normal operating conditions it makes good placement decisions. Under a host failure at 2am, the absence of an explicit anti-affinity rule for domain controllers produces two simultaneous domain controller outages. The environment gave no warning. There was nothing wrong with the migration. The rule simply was not there.
The anti-affinity gap is also one of the primary risk vectors covered in the Architecture of Migration — the foundational framing for this series.
Do not assume default scheduler behavior equals previous policy intent. Every VMware DRS rule must be explicitly audited, intentionally translated, or explicitly retired. Implicit translation is not translation — it is a gap waiting for a failure event to expose it.
SRM Recovery Plans — Rebuilding Failover Logic
SRM is the policy layer that migration teams most consistently underestimate.
The surface-level SRM function is VM replication — ensuring that copies of production VMs exist at the recovery site. Teams migrate off VMware, configure Nutanix replication, verify the replicas exist, and mark DR as complete. That is not DR. That is replication. DR is the orchestration logic that determines what happens when you invoke a failover.
A three-tier application does not simply require all three VMs to exist at the recovery site. It requires the database to be fully initialized before the application tier attempts a connection, and the application tier to be healthy before the web tier begins accepting traffic. SRM plans encode these dependencies explicitly. Without them, failover produces VMs that boot in the wrong order, timeout waiting for dependencies, and leave the application in a failed state despite the infrastructure appearing healthy.
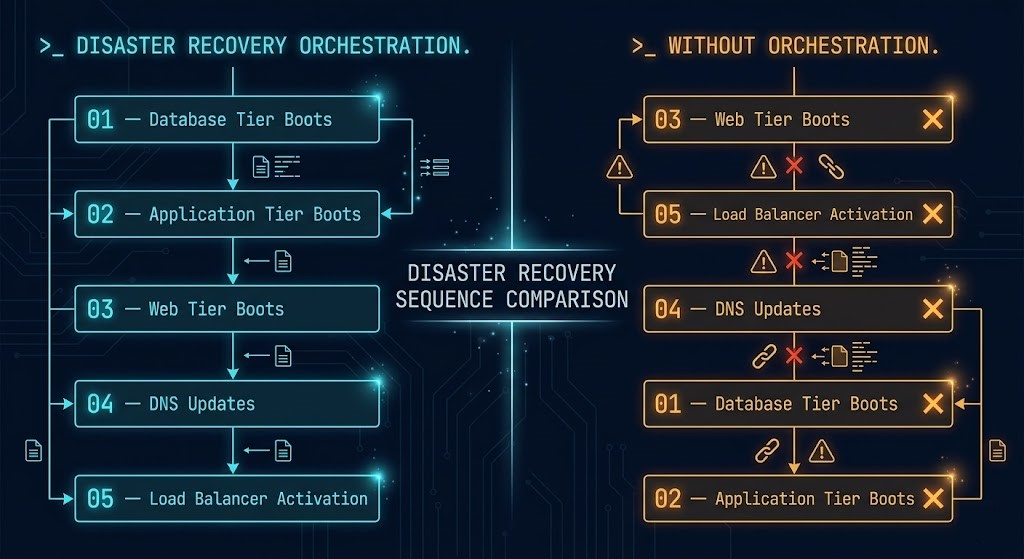
What SRM Actually Encodes
A fully configured SRM environment defines far more than replication: boot order across application tiers, dependency chains between services, startup delay intervals, network reconfiguration steps, DNS update sequences, load balancer activation order, and pre- and post-failover scripts. For a complete checklist of what must be captured before migration begins, the From vSphere to Nutanix AHV: The Deterministic Migration Checklist covers the full pre-migration verification scope.
Nutanix DR Model
Nutanix DR orchestration operates through protection policies and recovery plans built on consistency groups. The mechanism is equivalent in capability to SRM. The architecture is different in expression.
Key translation points:
- VMware protection groups map to Nutanix protection policies
- SRM recovery plan steps map to Nutanix recovery plan runbooks
- VM startup dependencies must be reconstructed as explicit sequencing rules
- Test failover isolation requires dedicated VLAN configuration on the target site
- Pre/post failover scripts must be re-validated against the new platform’s execution environment
The Documentation Problem
SRM plans frequently encode application architecture knowledge that exists nowhere else in the organization. The architect who designed the three-tier boot sequence left two years ago. The SRM plan is the only record of that dependency logic.
During migration, this creates a specific risk: the configuration is exported, the Nutanix recovery plan is created, and the dependency chain appears to have been recreated. But SRM plan configuration is dense, and subtle differences in startup timing or script execution order can produce DR tests that pass under ideal conditions and fail under real failure scenarios.
Every SRM recovery plan must be tested in the Nutanix environment before the VMware infrastructure is decommissioned. Not a replication verification — a full failover test with application-level health validation. The window for discovering orchestration gaps is while VMware is still available as a fallback, not after.
NSX Micro-Segmentation — The Highest-Risk Translation
If DRS translation is frequently missed and SRM translation is frequently incomplete, NSX translation is frequently misunderstood at a fundamental level.
The misunderstanding is about how NSX security policies are expressed.
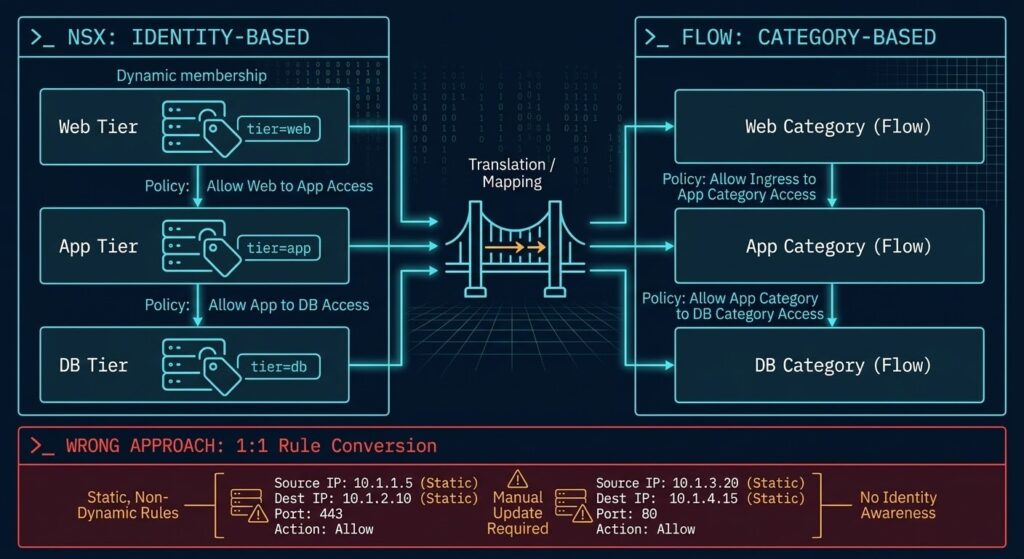
Identity-Based vs. IP-Based Security
Traditional firewall rules operate on IP addresses and port ranges. NSX security groups in a mature VMware environment typically do not. They operate on VM identity — dynamic group membership based on tags, names, and attributes. This policy model is covered in depth in Translating the Stack: A Field Guide to Migrating NSX‑T Security to Nutanix Flow.
A standard three-tier segmentation policy in NSX:
- Web tier VMs (tagged: tier=web) accept inbound traffic from the load balancer security group
- App tier VMs (tagged: tier=app) accept inbound traffic from the web tier security group only
- DB tier VMs (tagged: tier=db) accept inbound traffic from the app tier security group only
- DB tier VMs deny all other inbound traffic by default
This policy is portable — it moves with the workload as VMs are added, renamed, or moved, because membership is dynamic. The same policy expressed as IP-based firewall rules is a static configuration that diverges from reality every time a VM is added or an IP changes.
Translation to Nutanix Flow
Nutanix Flow micro-segmentation operates on application-centric policy with category-based grouping. The architecture is conceptually similar to NSX. The translation is operationally dangerous when approached incorrectly.
NSX tags and Flow categories are not the same object. VMware tags assigned to VMs must be mapped to Flow categories. Workloads with no existing tag assignment must be explicitly categorized before policy is applied — there is no implicit inheritance.
NSX processes rules in a defined order. Flow policy evaluation order differs. Rules that produce the correct result in NSX may produce different behavior in Flow if ordering assumptions are carried over implicitly. Validate evaluation order explicitly for every translated policy.
Verify explicitly whether the source NSX environment enforces default deny at the distributed firewall level. If it does, the same posture must be established in Flow before workloads are migrated. A default permit posture during migration is a security gap, not a convenience.
Application-specific service definitions in NSX — custom port groups, protocol definitions — must be recreated in Flow before rules referencing them can be translated. Missing service definitions produce silent rule failures, not errors.
The correct translation approach is category reconstruction: map NSX dynamic groups to Flow categories, validate category membership for all existing workloads, and rebuild segmentation policy using Flow’s application-centric model. This takes longer. The resulting configuration is maintainable.
Rebuilding segmentation policy manually from NSX exports is the part of vmware policy migration most likely to produce undocumented gaps. The NSX-T to Flow Translator maps your NSX security groups and rule sets to their Flow equivalents — so you’re rebuilding policy from validated logic, not from memory.
→ Run the NSX-T to Flow TranslatorNever attempt 1:1 rule conversion from NSX to Flow. Rebuild segmentation using application-centric groups and Flow categories. A policy that appears equivalent at the rule level but uses static IP addressing instead of dynamic group membership will diverge from the intended security posture within weeks of migration as the environment changes.
The Policy Audit Framework
Before any vmware policy migration begins, every environment requires a structured policy audit across all three layers. The output is not a feature comparison. It is a policy map — a document that records what each policy is designed to guarantee, not just what it currently configures.
Export and document all DRS affinity rules with rationale, all anti-affinity rules with the failure scenario each is designed to prevent, all VM-to-host rules with constraint type (license, compliance, hardware, NUMA), and any host maintenance mode automation affecting placement.
Flag any rules where the original rationale is unknown — these require an SME conversation before migration, not after.
Export all SRM recovery plans with full configuration including boot order and startup delays, all dependency chains between protected VMs, all pre- and post-failover scripts with documentation of what each script does, and test failover history with pass/fail results.
Flag any recovery plans not tested in the past 12 months. Untested recovery plans are configuration, not DR capability.
Catalog all NSX security groups with dynamic membership criteria, all distributed firewall rules with the application tier or compliance requirement driving each rule, all tag assignments across all VMs in security groups, and default deny status at the distributed firewall level.
Flag any security groups with membership criteria referencing VMware-specific attributes (vCenter folder, cluster membership) that will not exist in the Nutanix environment — these require redesign, not translation.
The Nutanix AHV Day-2 Operations: The Architect’s Ultimate Deep Dive covers how policy validation fits into ongoing operational practice once migration is complete.
Policy Drift — The Post-Migration Risk
Correct policy translation at migration time does not guarantee policy integrity over time.
VMware environments accumulate policy drift through a specific set of operational patterns — emergency rules applied during incidents that are never reviewed, new workloads deployed without policy review, and documentation that lags six months behind configuration. The same patterns apply on Nutanix. Migration is not a reset. It is a transfer — including a transfer of operational habits.
Policy drift is also compounded by a structural problem that most migration plans don’t account for: the coexistence window. During the months when VMware and Nutanix run simultaneously, policy governance across two platforms is harder than governance on either one alone. Security group membership diverges between platforms. Anti-affinity rules enforced on one side aren’t enforced on the other. The operational overhead of maintaining policy coherence across a hybrid estate accelerates the drift that would have happened anyway. The VMware Exit Has Entered the Coexistence Era maps the Fragmented Control Plane problem that the coexistence window creates — and the governance architecture required to contain it. The full sequence — from policy audit through cutover execution to post-migration governance normalization — is mapped across five clusters in the VMware Migration Strategy Track, with Cluster 03 covering policy portability in depth and Cluster 05 addressing the normalization window where drift accumulates fastest.
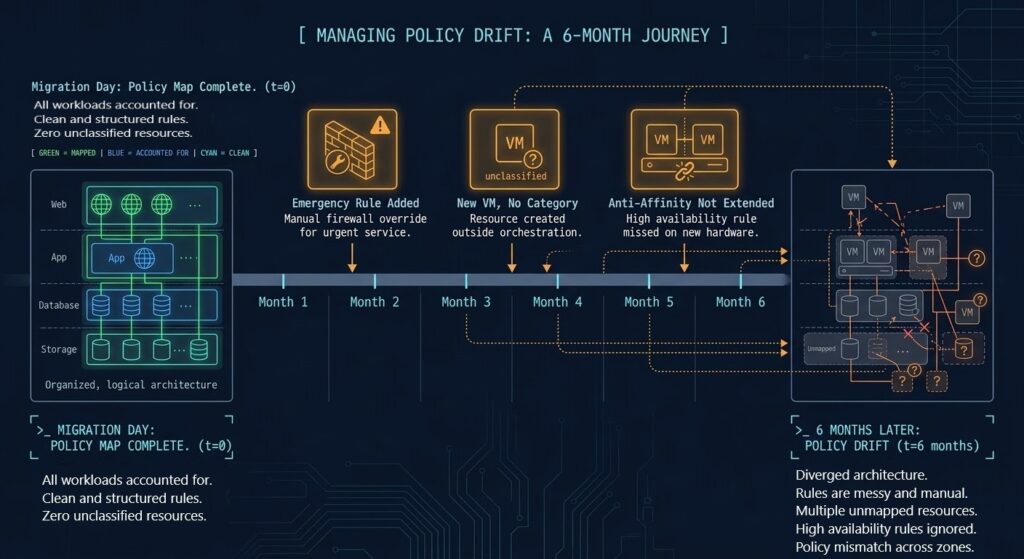
Why Drift Happens Faster Post-Migration
In a mature VMware environment, most engineers know the policy configuration well enough to recognize when something looks wrong. In a newly migrated Nutanix environment, that institutional knowledge has not developed yet. New workloads are deployed without category assignment. Emergency rules are added without review. Anti-affinity policies are not extended to new members of existing clusters.
Six months post-migration, the environment is running on policy configurations that diverge materially from the policy map produced during migration planning. The hidden costs of this kind of configuration drift are part of what the <a href=”https://www.rack2cloud.com/snapshot-tax-vmware-migrations/”>The “Snapshot Tax”: Why Hidden Metadata is the Silent Killer of VMware Migrations</a> covers in the context of ongoing technical debt accumulation post-migration.
For teams still in the platform selection phase — before the migration work begins — the constraint model that determines whether Nutanix, VMware, or Proxmox is the right destination is covered in Proxmox vs Nutanix vs VMware: The Post-Broadcom Constraints No One Explains.
Policy as Code
The environments that maintain long-term stability after a major platform migration treat policy as code — version-controlled, reviewed, and tested — not as UI configuration.
This does not require complex tooling. It requires discipline:
- Policy changes are documented at the time they are made, not in retrospect
- New workload deployments include a policy review step before production
- Anti-affinity and security group membership is validated as part of regular change management
- DR plan tests include policy validation, not just replication verification
The technical gap in any vmware policy migration is smaller on the technical side than it appears is smaller than it appears before migration. The operational gap — the habits, documentation practices, and review processes that maintain policy integrity over time — is where migrations diverge long-term.
Architect’s Verdict
Parts 01 through 03 of this series dealt with physics. I/O events, CVM headroom, storage amplification — these are measurable, modelable, and recoverable. A stutter event produces telemetry. The recovery protocol is deterministic.
Policy translation failures do not behave this way. The environment appears healthy. Applications run. Monitoring shows green. The gap only surfaces when a domain controller failure takes down two nodes simultaneously because an anti-affinity rule was never recreated, or when a DR test fails because the recovery plan boots tiers in the wrong order, or when a security audit identifies lateral movement exposure because NSX dynamic group membership was replaced with static IP rules that were never maintained.
Migrating workloads moves compute and storage. Migrating policies moves architecture intent.
Most VMware exits solve the first problem completely and address the second problem partially. The environments that remain stable — that pass DR tests, survive host failures cleanly, and hold their security posture over time — are the ones that treated policy translation as a first-class engineering problem, not a post-migration cleanup task.
The policy map is not documentation overhead. It is the deliverable that determines whether the migration succeeded architecturally, not just operationally.
What Part 5 Covers
Parts 01 through 04 have addressed the core translation layers of a VMware exit: execution model physics, controller resource contention, migration I/O sequencing, and policy logic.
Part 05 examines the operational layer that determines whether the new platform remains stable as it evolves: upgrade physics and rolling maintenance design.
In VMware environments, upgrade sequencing — vCenter, ESXi hosts, vSAN — follows a defined dependency chain that most teams know well after years of operation. In Nutanix, the upgrade coordination model is architecturally different. AOS, AHV, and Foundation upgrades interact with CVM availability windows in ways that are not obvious from the VMware mental model. Part 05 maps the upgrade dependency graph, the minimum viable headroom requirements for a rolling upgrade without service impact, and the failure scenarios that only appear when an upgrade is attempted on an under-resourced cluster.
You know the risk of carrying forward architectural debt. Now, we tear down the mechanics. Track the series below as we map the exact physical changes required for a deterministic migration.
Skip the wait. Download the complete Deterministic Migration Playbook (including the Nutanix Metro Cluster Implementation Checklist) and get actionable engineering guides delivered via The Dispatch.
SEND THE BLUEPRINTAdditional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session