Gateway API Is the Direction. Your Controller Choice Is the Risk.

Gateway API Kubernetes adoption is settled. The project has made its call — GA in 1.31, role-based model, the ecosystem is moving. That decision is not the hard part. Gateway API is GA. The Ingress API is not going away, but it is not where the ecosystem is investing.
That decision is made. What isn’t made — and what most guides skip entirely — is the controller decision that sits underneath it. Gateway API defines the routing model. It does not define what runs your traffic, how that component behaves under load, or what happens when it restarts in a cluster with five hundred routes and an incident already in progress. That’s the controller decision. And it’s where the architectural risk actually lives.
This post covers what the controller decision actually hinges on: failure modes, Day-2 behavior, and the operational tradeoffs that don’t appear in comparison matrices. If you want a feature checklist, there are dozens of those. This is the analysis that comes after you’ve already picked a direction and need to know what will break.
Gateway API defines the model. Your controller choice determines the blast radius.
Gateway API Kubernetes: Why the Controller Decision Matters
Gateway API graduated to GA in Kubernetes 1.31. The role-based model — GatewayClass, Gateway, HTTPRoute — separates infrastructure concerns from application routing in a way the original Ingress API was never designed to do. For platform teams managing multi-tenant clusters, this separation is architecturally significant: app teams manage their HTTPRoutes, platform teams own the Gateway and GatewayClass, and the permission model is explicit rather than annotation-based.
The migration from Ingress to Gateway API is well-documented at the spec level. What’s less documented is the operational delta between controllers that implement it. Two clusters running Gateway API with different controllers can behave completely differently under the same failure condition. The API is standardized. The runtime behavior is not.
That’s the gap this post addresses.
The Fork That Matters: Ingress API vs Gateway API
Before the controller decision, the API model decision — because the two are not interchangeable and your controller selection is downstream of it.
The Ingress API (networking.k8s.io/v1) is stable, universally supported, and battle-tested. It handles HTTP/HTTPS routing with host and path matching. It also handles almost nothing else without controller-specific annotations — which is where the operational debt starts accumulating in year two and compounds quietly through year five.
The Gateway API is the successor — graduated to GA in Kubernetes 1.31. Typed resources, explicit cross-namespace permission grants via ReferenceGrant, expressive routing rules that live in version-controlled manifests rather than annotation strings. For new clusters, it is the correct default. For existing clusters with years of Ingress annotations in production, migration has a cost that needs to be planned rather than assumed away.
Pick the API model first. The controller decision follows from it — not the other way around.
Where Kubernetes Ingress Controllers Actually Fail
The ingress-nginx deprecation path has pushed a lot of teams into controller evaluation mode. Most of that evaluation happens at the feature level. Here’s what happens at the operational level — the failure modes that surface after the controller is in production.
None of these failure modes appear in controller documentation. All of them will surface in production if you haven’t accounted for them in your architecture. The Kubernetes Day-2 incident patterns follow a consistent shape: the configuration was correct, the failure mode was structural, and it only became visible under the specific load condition that triggers it.
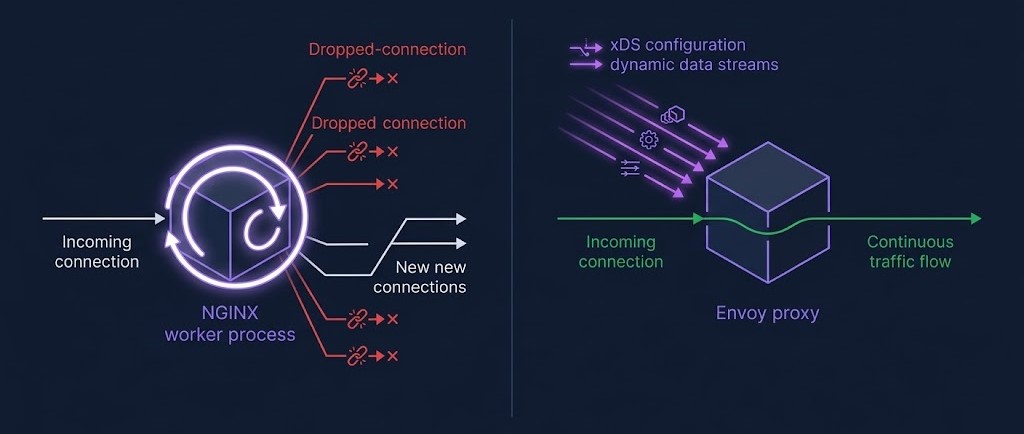
Reload-Based vs Dynamic Configuration: The Architectural Fork
The reload vs dynamic configuration distinction is the most operationally significant difference between controller architectures — more significant than any feature comparison.
NGINX-based controllers reload the worker process on configuration changes. The reload is fast — typically under 100ms. At low frequency: invisible. At 50–100 reloads per hour from a cluster with aggressive HPA configurations or high deployment velocity, the cumulative effect on tail latency and persistent connections is real. Monitor nginx_ingress_controller_config_last_reload_successful and reload frequency before this becomes a production problem.
Envoy-based controllers — Contour, Istio’s gateway, and AWS Gateway Controller — use xDS dynamic configuration delivery. Route changes propagate without process restart. For clusters with high pod churn or KEDA-driven autoscaling, this is architecturally significant rather than a preference. The autoscaler choice and the ingress controller choice have a dependency that most teams don’t map until they’re debugging correlated latency spikes.
Similarly, resource requests and limits on ingress controller pods are not a secondary concern. An under-resourced controller pod that gets OOM-killed or throttled under burst load is a full ingress outage. Size the controller like it’s critical infrastructure, because it is.
Controller Decision: Operational Tradeoffs by Profile
With the failure modes as context, here’s how the major controllers map to real operational environments. This is not a feature matrix — it’s a failure model and operational weight assessment.
| Controller | Config Model | Gateway API | Best Fit | Watch For |
|---|---|---|---|---|
| ingress-nginx (community) | Reload on change | Partial | Stable clusters, Ingress API incumbents | Reload storms under HPA churn |
| NGINX Inc. (nginx-ingress) | Hot reload (NGINX Plus) | Partial | Enterprise with NGINX support contracts | License cost, annotation parity gaps |
| Contour | Dynamic xDS | Native (GA) | New clusters, Gateway API-first | Smaller ecosystem, fewer extensions |
| Traefik | Dynamic | Beta | Dev/staging, operator-heavy envs | Gateway API maturity, CRD proliferation |
| AWS LB Controller | ALB/NLB native | Yes | EKS-only, AWS-native workloads | Hard AWS lock-in, ALB cost at scale |
| Istio Gateway | Dynamic xDS | Native | Existing service mesh deployments | Operational complexity, sidecar overhead |
The service mesh angle deserves a direct note: if your cluster is already running Istio or Cilium, adding a separate ingress controller creates a parallel traffic management layer with its own observability gaps. The service mesh vs eBPF tradeoff determines whether your ingress and east-west traffic share a unified data plane — and that decision has operational weight that shows up during incident response, not during initial deployment.
The Three Questions the Decision Actually Hinges On
Strip away the comparison matrices and the controller decision comes down to three questions. Answer these before you commit.
What is your cluster’s churn rate? Count your Ingress-triggering events per hour: HPA scale events, deployments, cert renewals, configuration changes. If that number is high and climbing, reload-based controllers carry real operational risk. This is not a hypothetical — it’s a direct dependency between your autoscaling strategy and your ingress architecture. The 502 and MTU debugging patterns that show up in ingress troubleshooting often trace back to reload timing under load rather than configuration errors.
Where does your annotation investment live? If you have years of Ingress annotations encoding routing logic, rate limiting, and authentication configuration across hundreds of resources, the Gateway API migration cost is real. It requires cataloging every annotation, testing every route, and coordinating with every application team that touches an Ingress object. Run that migration when you’re doing a platform modernization anyway — not as a standalone project.
Who operates this at 2 AM? A controller that a three-person platform team can debug during an incident is better than a technically superior controller no one fully understands. This is a legitimate selection criterion — not an excuse for technical debt. The platform engineering model puts ingress in the platform team’s operational domain, which means the controller needs to fit their observability stack, their runbook model, and their on-call capability.
The Day-2 Checklist Nobody Ships With
Before a controller goes to production, these questions need answers. They don’t change — only the urgency does, depending on whether you find them in testing or during an incident.
- [ ]What is the controller’s behavior during a rolling update — and is there a zero-downtime upgrade path documented for your version?
- [ ]How does it handle TLS certificate rotation under sustained load? Is the stale-cert serving window measured?
- [ ]What metrics does it expose natively, and what requires custom instrumentation? Is reload frequency in your alerting stack?
- [ ]What is the reconciliation time from cold start with your current route object count? Has this been measured — not estimated?
- [ ]Is a PodDisruptionBudget configured, and does it account for the reconciliation window — not just process start?
- [ ]What breaks first if the controller pod is evicted under node memory pressure? Is that failure mode in your runbook?
- [ ]If you’re running a service mesh — is the ingress controller in or out of the mesh data plane, and is that decision explicit?
The containerd Day-2 failure patterns and these ingress failure modes share a structural similarity: they are invisible during initial deployment, they compound under real production load, and they surface at the worst possible time. The checklist exists to surface them earlier.

Architect’s Verdict
Gateway API is the correct architectural direction for new Kubernetes clusters in 2026. That decision is settled. The controller decision underneath it is not — and it carries more operational risk than the API model choice does.
For new infrastructure: Gateway API Kubernetes with Contour is the defensible default. The API is GA, the xDS-based configuration model eliminates reload risk, and you avoid accumulating annotation debt from day one. On EKS, the AWS Load Balancer Controller is the pragmatic choice if you’re already committed to the AWS networking model — with the understanding that you are accepting the lock-in that comes with it.
For existing clusters on ingress-nginx: don’t migrate for migration’s sake. The community controller still works. The ingress-nginx deprecation path has four documented options — evaluate them against your actual cluster profile, not the general recommendation. The cost of migration needs to be planned, not assumed away by enthusiasm for a newer API model.
Either way: measure your reload rate before it becomes a problem. Configure readiness probes against reconciliation completion, not process start. Don’t assume cert-manager and your controller share the same definition of “ready.” These failure modes are predictable. The only variable is whether they surface in your testing environment or in production during an incident.
For the broader Kubernetes cluster orchestration decision space — from scheduling physics to autoscaling architecture — the Cloud Native Architecture pillar maps the full framework. If you’re building or stress-testing your platform team’s operational model, the Platform Engineering Architecture pillar covers the team and tooling layer that ingress controller decisions plug into.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




