GPU Utilization Is Becoming the New Cloud Waste Crisis
Enterprises are now paying premium-market prices for infrastructure that spends most of its life waiting. The number that frames this era: average GPU utilization across enterprise Kubernetes clusters sits at 5%, according to Cast AI’s 2026 State of Kubernetes Optimization Report — drawn from measured production telemetry across 23,000 clusters, not a survey. That figure means 95% of provisioned GPU capacity is idle at any given moment. It also arrives at exactly the point NVIDIA raised H200 reserved prices by roughly 15%, breaking a 20-year pattern of falling compute costs. The industry spent two years treating GPU scarcity as the defining AI infrastructure problem. The next phase will be dominated by the opposite: organizations that massively over-reserved GPU capacity they cannot efficiently utilize, now paying more for the privilege. It is the operational phase the AI Infrastructure Architecture pillar is designed around.

The GPU Shortage Narrative Hid the Real Problem
From 2023 through 2025, GPU scarcity drove a rational but architecturally corrosive behavior: defensive over-provisioning. Organizations reserved capacity before workloads existed to fill it. GPU reservation became a strategic moat — holding accelerators against a competitive landscape where spot availability was unreliable and on-demand H100s were measured in weeks-long wait queues. The behavior made sense under scarcity conditions. It created an environment where utilization telemetry was irrelevant because nobody was optimizing, only acquiring. The same reservation dynamic that drove idle cloud cost to become a structural problem now operates at GPU prices.
That environment is gone. The cost structure has changed. The wait queues have eased. And the 5% utilization figure is now the operational reality underneath billions in committed GPU spend. Cast AI co-founder Laurent Gil framed it precisely: “A GPU sitting idle costs dollars per hour. A CPU sitting idle costs cents. And 95% of GPU capacity is doing nothing.” The question is no longer where to get GPUs. It is why the ones enterprises already have aren’t running.
GPU Utilization Is Not CPU Utilization
This is where most FinOps analysis of the problem goes wrong. GPU utilization is not a more expensive version of CPU utilization, and the optimization playbook is not the same. The traditional FinOps model was built for CPU elasticity — it has no vocabulary for VRAM fragmentation or inference queue depth.
CPU environments reward high utilization because workloads are relatively fungible. A heavily loaded CPU is generally doing useful work. GPU environments can hit high utilization numbers while simultaneously degrading inference latency, starving request queues, or over-concentrating workloads onto constrained VRAM boundaries. A GPU running at 90% utilization with poorly batched inference requests and fragmented memory allocation is not a well-operated GPU — it is a saturated one. The goal is not maximum GPU utilization. The goal is controlled utilization under placement-aware scheduling.
The operational differences compound at every layer. GPU reservation cannot be made elastic the way CPU can — inference latency constraints mean you cannot scale to zero between requests without accepting cold-load penalties measured in seconds, not milliseconds. VRAM fragmentation means memory that appears available is often not addressable by the current workload because models cannot co-reside efficiently on the same physical device. Batching complexity means the strategy that maximizes throughput directly conflicts with the SLA that governs latency. Model residency requirements mean that warm state versus cold load time is not a configuration choice — it is a placement architecture decision that must be made before the request arrives.
GPU locality adds another dimension that most scheduling discussions omit entirely. The scheduler may see available accelerators, but the workload may require specific NVLink topology, PCIe adjacency, or node co-location to avoid cross-fabric bandwidth penalties. Distributed inference and coordinated batching impose topology requirements — which GPUs are connected to each other, at what bandwidth, across what fabric — that a scheduler operating on integer device counts cannot reason about without explicit locality constraints encoded in the placement policy. The GPU Utilization & AI Capacity Analyzer surfaces where that gap is costing yield — Phantom Scarcity detection and the Capacity Illusion Index identify whether perceived GPU shortage is structural fragmentation or genuine demand before the provisioning decision compounds it.”
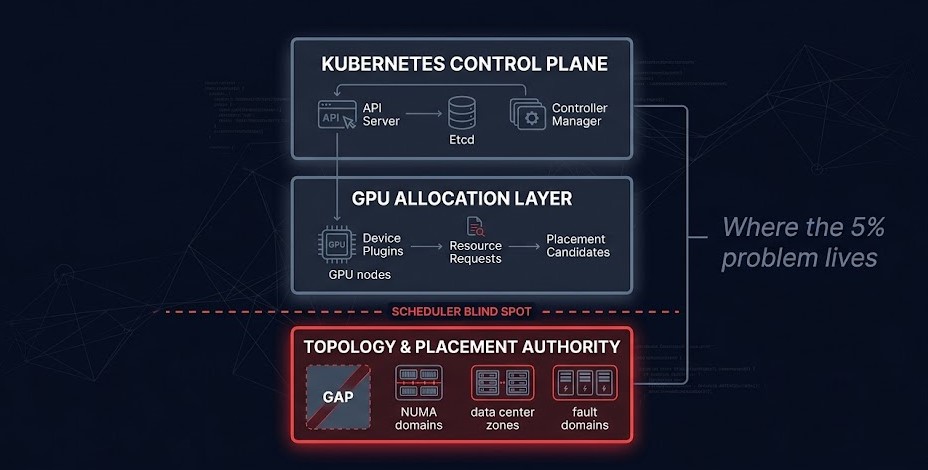
>_ Scheduler Blindness
The Kubernetes scheduler sees nvidia.com/gpu: 1 as an integer. It has no visibility into VRAM state, model residency, batching queue depth, or NVLink topology. Allocation and utilization are two entirely different problems — and the scheduler only solves one of them.
The GPU Waste Triangle
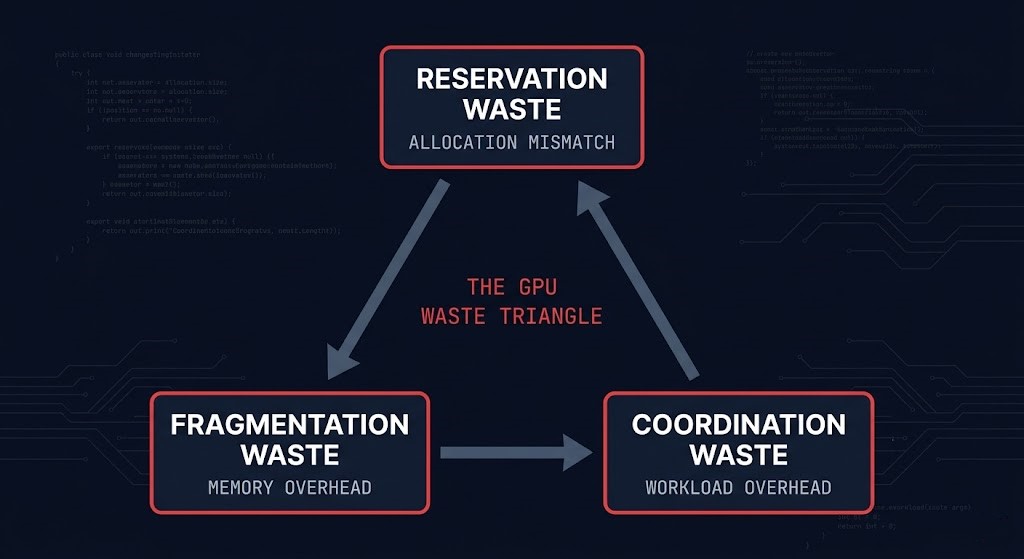
GPU utilization failures are not random. Across enterprise deployments, the same three structural patterns appear repeatedly. Together they form what I’m calling the GPU Waste Triangle — three nodes, each representing a distinct failure mechanism, each feeding the others.
01 — RESERVATION WASTE
GPUs held for burst inference at low steady-state occupancy. The procurement behavior that made sense during scarcity — reserve first, fill later — created environments where capacity sits reserved against burst demand that rarely materializes at the assumed scale. Cast AI’s data puts a no-effort utilization baseline at roughly 30% once you account for day cycles, weekends, and normal business patterns. Enterprises averaging 5% are operating at one-sixth of what doing nothing intentional would yield.
02 — FRAGMENTATION WASTE
VRAM stranded between models that cannot co-reside efficiently on the same physical device. Multi-Instance GPU (MIG) partitioning can address this architecturally, but adoption remains low — most schedulers assign whole GPUs by default because the tooling to reason about sub-GPU allocation at the workload placement layer is still maturing. The result is memory that is technically allocated but not addressable by any active workload. The GPU appears busy. The work is not happening.
03 — COORDINATION WASTE
GPUs sitting idle while requests queue upstream waiting for batch formation. This is the failure pattern that produces the most operationally confusing symptom: accelerators showing low utilization at the same time inference latency is degrading. The GPUs are idle not because there is no demand — there is demand, visible in the queue depth — but because the orchestration layer cannot coordinate batch assembly fast enough to keep the accelerators fed. Cross-zone dispatch compounds it: requests routed to a geographically distant GPU pool add latency without improving utilization, while nearby accelerators sit waiting. The underlying cause is orchestration layers that were designed for CPU workloads and still model accelerators as fungible compute resources with no queue state, no model residency, and no topology dependencies.
| Waste Type | Root Cause | Observable Signal | Fix Layer |
|---|---|---|---|
| Reservation | FOMO procurement, static capacity planning | Low steady-state utilization, high reservation cost | Placement policy, continuous rightsizing |
| Fragmentation | Whole-GPU allocation, no MIG adoption | VRAM allocated but not used, model co-residency failures | Scheduler configuration, MIG partitioning |
| Coordination | Poor batching, cross-zone dispatch, CPU-model scheduling | Idle GPUs + high queue latency simultaneously | Inference orchestration, locality-aware placement |
Kubernetes Is Quietly Becoming the AI Infrastructure Scheduler
AI infrastructure inherited the Kubernetes control plane before Kubernetes understood accelerators. The scheduling assumptions, authority models, and governance gaps that exist in Kubernetes today are the same ones GPU workloads are now forced to operate within — an integer device model, no topology awareness, no queue-depth visibility, and placement logic designed for stateless CPU workloads.
That is changing. At KubeCon Europe in March 2026, NVIDIA donated its Dynamic Resource Allocation Driver for GPUs to the Cloud Native Computing Foundation, shifting GPU scheduling governance from a single vendor into the broader Kubernetes community. This is the architectural signal: heterogeneous accelerator scheduling is no longer a niche ML platform concern. It is a first-class infrastructure problem that the Kubernetes community has accepted ownership of.
Two days ago, NVIDIA published the GPU Usage Monitor — a Helm-deployable observability stack specifically because the standard Kubernetes metrics stack does not surface GPU-specific signals. Teams have been operating without visibility into VRAM state, per-pod GPU utilization, or memory waste at the workload level. That tooling gap is why the waste is invisible until it shows up on a bill.
Kubernetes is not winning AI workloads because containers won. It is winning because heterogeneous accelerator scheduling at enterprise scale became unavoidable, and Kubernetes was the only orchestration layer with the operational ecosystem to handle it. The architectural mechanics behind that shift are covered in the GPU Orchestration & CUDA Architecture pillar. The real optimization layer is no longer the GPU itself. It is the scheduler authority deciding where, when, and under which topology the workload executes.
Why Observability Alone Doesn’t Fix GPU Waste
The NVIDIA GPU Usage Monitor, DCGM Exporter, and the broader Kubernetes GPU observability stack give you the signal. They do not change the allocation model. Knowing that GPU utilization is 5% tells you the waste exists. It does not fix VRAM fragmentation, reservation behavior, or the coordination failures that leave accelerators idle while queues fill upstream.
The standard Kubernetes metrics stack — kube-state-metrics, node-exporter — does not surface GPU-specific signals at all. Teams have been building one-off monitoring setups or operating without GPU visibility entirely, which is precisely why the utilization gap went unaddressed for as long as it did. Visibility was the missing prerequisite. But visibility is not the fix.
The fix requires changes upstream of the observability layer: placement logic that encodes locality constraints before the request arrives, batching strategies that balance throughput and latency at the inference serving layer, reservation policies that distinguish burst headroom from structural waste, and scheduler configuration that treats GPU topology as a first-class placement variable rather than an afterthought. The inference placement problem and the AI FinOps model failure are downstream consequences of the same architectural gap — a control plane not built to reason about accelerator workloads, now governing the most expensive infrastructure layer in the enterprise stack.
The layer below the scheduler where that architectural gap is most consequential — storage throughput, checkpoint behavior, and data pipeline design as first-class compute dependencies — is covered in the Storage & Data Pipeline Architecture stage of the AI Architecture Learning Path. The operational layer above the scheduler — where GPU utilization signals, cost observability, and runtime governance converge into LLMOps operational practice — is the domain of Operations & LLMOps Architecture, the stage that covers how these signals are turned into production governance rather than diagnostic observations.
Architect’s Verdict
The industry optimized aggressively for acquiring GPUs before it learned how to operate them efficiently. The scarcity era created procurement behaviors that made strategic sense in 2023 and are creating structural waste problems in 2026. That is not a criticism of the teams involved — it is a description of what rational actors do when the constraint is availability, not efficiency.
The result is environments where the most expensive infrastructure in the stack spends most of its life waiting. Waiting for work. Waiting for batch formation. Waiting for coordination. Waiting for orchestration layers that still model accelerators as fungible CPU-equivalent resources with no topology requirements, no queue state, and no placement intelligence. The waste is not hidden in forgotten cloud instances or idle compute clusters. It exists inside GPU pools that enterprises paid premium prices to reserve, are paying premium prices to hold, and are now paying NVIDIA’s revised pricing to renew.
GPU scarcity was the opening phase of the AI infrastructure era. GPU efficiency is the operational phase that comes next. The cost consequences of that transition are what makes inference the new steady-state cost center. The teams that resolve the control plane problem first — placement authority, scheduler governance, locality constraints, reservation discipline — will operate at a cost profile that makes the current 5% baseline look like a different era entirely.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




