The Infrastructure Team Is the Real Single Point of Failure

Every serious infrastructure investment goes into redundant hardware, distributed systems, and multi-region failover. Almost none goes into the one dependency that sits above all of it — the small number of engineers whose departure, unavailability, or burnout makes the environment unrecoverable.
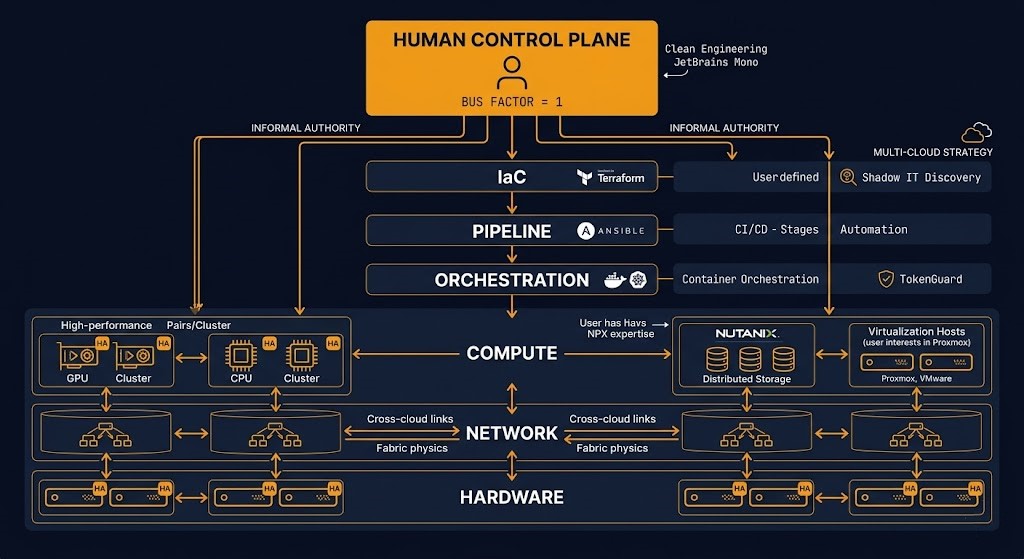
The infrastructure bus factor is the organizational single point of failure that no architecture review catches. It doesn’t appear in the system diagram. It doesn’t show up on a monitoring dashboard. It doesn’t produce a change failure rate metric or a drift alert. It lives in a person. In most organizations, the real infrastructure control plane is not Terraform, not Kubernetes, not vCenter. It is the senior engineer carrying operational context in their head — the undocumented governance layer that fills every gap the formal systems leave.
That is not a staffing problem. It is an architectural one.
THE AUTHORITY LAYER
The Bus Factor No One Models
The infrastructure bus factor is the number of engineers who would need to be simultaneously unavailable before the environment becomes unrecoverable. The question isn’t how many people are on the team. It’s how many of them carry operational authority artifacts that exist nowhere else.
Operational authority artifacts are not documentation gaps. They are not knowledge that could be written down if someone had time. They are the execution authority, recovery judgment, exception context, and institutional pattern recognition that accumulate in specific engineers over time — and that the formal systems were never designed to hold. Break-glass credentials held in one person’s vault. Recovery sequencing judgment that exists only in the engineer who has actually invoked DR and remembers what the runbook omits. Vendor escalation relationships that are personal, not organizational. IaC exception context that explains why a specific drift state was accepted and what would break if it were reverted.
Most enterprise infrastructure teams have a bus factor of one. Not because they are understaffed, but because operational authority was never treated as an architectural dependency that required the same redundancy discipline applied to hardware.
The Operational Memory Gap is the formal name for this condition: the distance between what the infrastructure documentation describes and what the people who actually operate the environment know — not as information, but as authority. The gap is almost always wider than organizations realize, and it becomes visible at the worst possible time: during an incident, a DR invocation, or a personnel change.
Why Redundancy Stops at the Human Layer
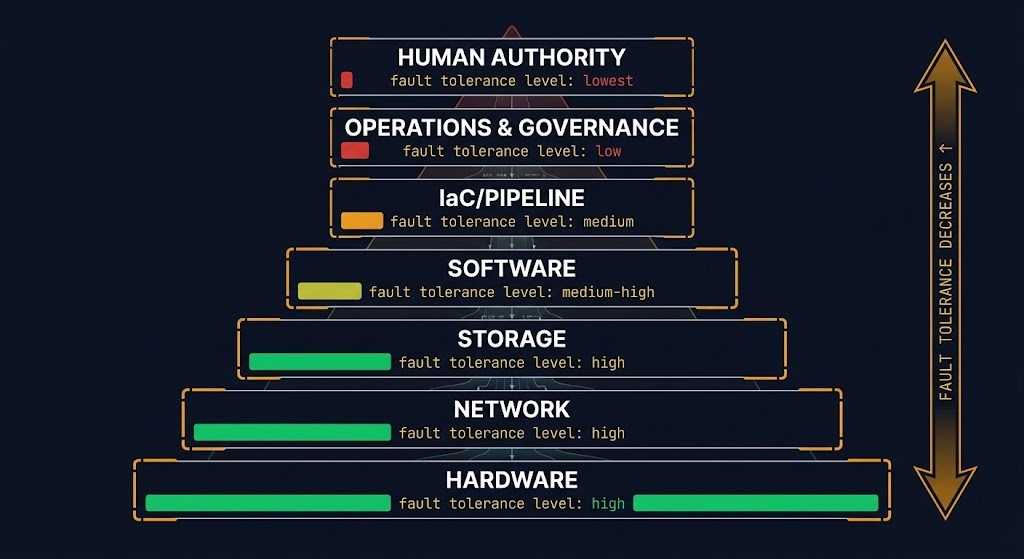
Organizations build HA clusters, multi-region failover, replicated storage, redundant networking, and distributed control planes. The investment in fault tolerance is real and significant. But it stops at a specific layer.
The infrastructure stack becomes progressively more fault tolerant moving downward into hardware and software. It becomes progressively less fault tolerant moving upward into operations and governance. Disk failure is handled by RAID or erasure coding. Node failure is handled by clustering. Region failure is handled by replication and failover. Team failure — a departure, a simultaneous unavailability, a knowledge concentration event — is handled by nothing, because no system was designed to handle it.
Most enterprises eliminated hardware single points of failure years ago. Many still operate with human single points of failure embedded directly in the recovery layer — the layer that is supposed to be invoked when everything else has failed.
This is the architectural contradiction at the center of the bus factor problem. The fault tolerance investment ends exactly where operational authority begins. Hardware redundancy was an architectural decision. Operational authority distribution was never made a decision at all — it accumulated by default.
⚠ THE ARCHITECTURAL CONTRADICTION
Organizations design redundancy into every layer of infrastructure hardware and software. They never design redundancy into operational authority. The most fault-tolerant layer in most enterprises is the storage fabric. The least fault-tolerant layer is the team member who knows how to recover it.
How the Infrastructure Bus Factor Gets Built
The bus factor doesn’t arrive by design. It accumulates through the normal operational patterns of a mature infrastructure environment — and it accumulates fastest in the most capable teams.
The senior engineer who resolves incidents faster than anyone else creates a gravity well. Tickets start routing to them informally. The on-call rotation that everyone nominally participates in gradually becomes one person’s responsibility in practice, because the fallback is always the same. Console changes get made during incidents and never land in code, because the engineer who made them is available to explain them if anyone asks. Runbooks don’t get written because the person who owns the procedure is always reachable to just execute it.
The most significant pattern is The Engineer Who Became the Exception Layer. Systems grow complex. Governance processes slow down change velocity. One senior engineer becomes the fast path around operational friction — the person who can get something done without a three-week change management cycle. The organization optimizes around them, not intentionally, but operationally. All undocumented exceptions begin routing through them. All judgment calls that fall outside the documented process get escalated to them. They become human middleware: the execution layer that fills the gap between what the formal systems enforce and what production operations actually require.
Mature environments rarely centralize authority intentionally. They centralize it operationally — around the person who can bypass friction fastest. By the time it becomes visible as a bus factor problem, the dependency is years deep.
What the Infrastructure Bus Factor Actually Controls
The bus factor manifests differently across different categories of operational authority artifacts. The table below maps the artifact categories that most commonly concentrate in single individuals — and the consequence when that person is unavailable.
| Authority Artifact | Single-Person Concentration | Consequence of Absence |
|---|---|---|
| Break-glass credentials | Held in one engineer’s personal vault | Environment unrecoverable during IAM/IdP failure |
| Undocumented network topology | Lives in one person’s mental model | Incident diagnosis requires their presence |
| Vendor escalation paths | Personal relationships, not organizational | P1 escalation stalls without them |
| IaC exception context | One person knows why drift was accepted | Revert risk unknown — remediation blocked |
| Recovery sequencing authority | One person knows the dependency restart order | DR invocation produces cascading failures |
| Certificate and secrets rotation | One person owns the schedule and method | Expiry events undetected or mishandled |
| Incident judgment authority | One person calibrates alert signal vs. noise | False escalations or missed real signals |
| DR invocation procedure | One person has executed it and knows what the runbook omits | Documented procedure fails at the first undocumented step |
The most operationally critical row is recovery sequencing authority. This is the authority artifact with the highest blast radius — and the one least likely to appear in any formal documentation. The DR runbook says “restore services.” One engineer knows the actual dependency order required to avoid a continuity cascade on restart: which system comes up first, which services have hidden startup interdependencies, which sequence triggers a recovery cascade versus a clean initialization. That judgment — built from direct experience of what happened last time — is not a procedure. It is pattern recognition accumulated through operational history. Writing it down doesn’t transfer it. The engineer executing the procedure under live incident conditions is solving a different problem than the engineer who originally wrote the steps.
This is Recovery Authority Concentration: the degree to which recovery execution depends on the presence of specific individuals rather than documented, system-enforced procedures. It is the bus factor at its most dangerous, because it surfaces exactly when operational pressure is highest and individual availability is most uncertain.
Connect to The Continuity Cascade — the Recovery Engineering Series covers what happens when recovery dependencies are not mapped before they’re needed. The Day 2 operations debt post covers the IaC exception context category specifically — the undocumented drift that accumulates when one person makes judgment calls that never reach the governance layer.

The Human Control Plane
Parts 1 and 2 of the Authority Layer established two failure modes in the infrastructure control plane architecture. Part 1: the CI/CD pipeline should be the authority over infrastructure state change — but most pipelines can be bypassed by anyone with console access or a local Terraform install. Part 2: console access is the shadow control plane — every untracked mutation that bypasses the pipeline accumulates as undocumented state.
Part 3 names what sits above both of those failure modes.
In most enterprise infrastructure environments, there is a third control plane layer that no architecture diagram includes. It is the informal layer of operational authority carried by the senior engineers who understand how the environment actually behaves — not how it is documented, not how it was designed, but how it runs in production under real conditions. This is the Human Control Plane: the undocumented governance layer that fills every gap the formal systems leave.
The Human Control Plane operates through three mechanisms. Informal authority: people route around slow or incomplete formal processes to the engineer who gets things done, and that routing becomes load-bearing over time. Exception accumulation: every undocumented workaround, every console change that wasn’t backfilled to IaC, every policy exception that was verbally approved and never codified — each one becomes a dependency on the person who created or approved it. Recovery concentration: actual recovery paths diverge from documented paths because only certain engineers know the divergence points, the undocumented dependencies, the steps the runbook skips because the person who wrote it assumed they would always be there to fill the gaps.
The Knowledge Authority Collapse is what happens when the Human Control Plane fails. A personnel change — departure, illness, extended unavailability, role transition — removes the informal governance layer that was doing real operational work. The formal systems remain intact. The documentation remains in place. But the actual recovery paths, exception contexts, and judgment calls that the formal systems depended on are no longer accessible. The infrastructure didn’t change. The control plane did.
This is the authority trilogy that Parts 1, 2, and 3 describe. The pipeline gets bypassed — Part 1 failure. Console access accumulates untracked state — Part 2 failure. Operational authority concentrates in individuals — Part 3 failure. Each can occur independently. All three together produce an environment that is technically instrumented and operationally ungoverned
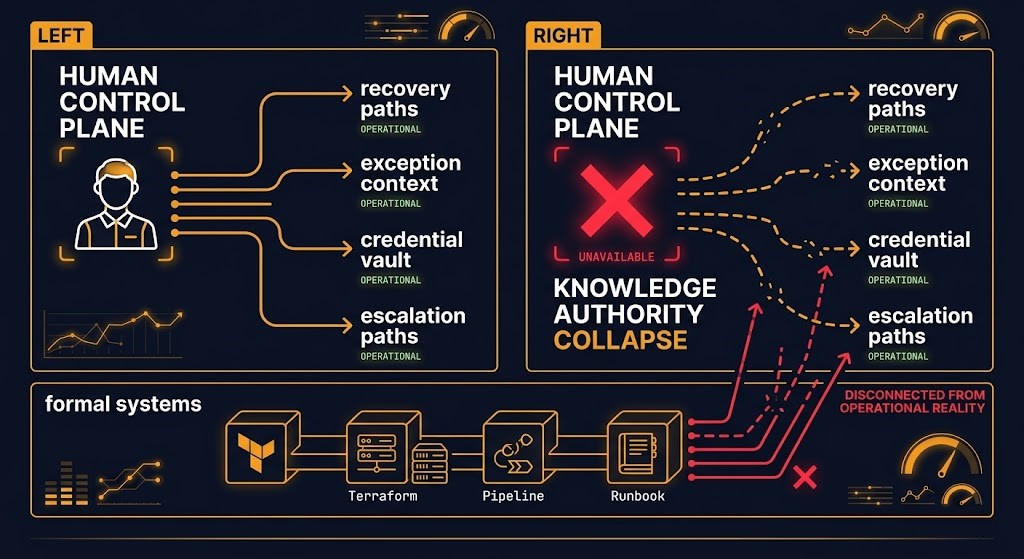
THE AUTHORITY TRILOGY — THREE FAILURE MODES
- Part 1 — Pipeline bypass: infrastructure state changes without passing through the mandatory execution path
- Part 2 — Shadow control plane: console mutations accumulate as undocumented state outside the governance model
- Part 3 — Human Control Plane: operational authority concentrates in individuals rather than systems, making personnel availability a control plane dependency
This concentration risk compounds directly at the multi-cloud boundary: when ownership of a cross-provider decision has never been explicitly assigned, the bus factor isn’t just “who understands this system” — it’s “who has authority to act during a provider-boundary failure at all.” Multi-Cloud Coherence Is an Ownership Problem, Not a Technology Problem covers the version of this gap that shows up specifically at cloud provider seams.
Bus Factor Audit: Five Diagnostic Questions
The infrastructure bus factor doesn’t require a formal audit to surface. Five questions expose the concentration of operational authority artifacts in most environments:
BUS FACTOR AUDIT — FIVE DIAGNOSTIC QUESTIONS
01 — RECOVERY COVERAGE
If your two most senior infrastructure engineers were simultaneously unavailable for 72 hours, which systems could not be recovered from an incident — and why?
02 — RUNBOOK EXECUTABILITY
Which recovery procedures exist only as tribal authority — documented in name but only executable by the engineer who wrote them, because the procedure omits the judgment calls that make it work?
03 — CREDENTIAL DISTRIBUTION
Which credentials — break-glass accounts, vendor portals, infrastructure management systems — exist in one engineer’s personal vault rather than a secrets management system with rotation policy and access controls?
04 — ESCALATION PATHS
Which vendor escalation relationships are personal rather than organizational? If that engineer is unavailable during a P1 incident, does the escalation path still exist?
05 — EXCEPTION CONTEXT
Which IaC exceptions, console changes, or policy deviations exist because one engineer made a judgment call that was never encoded into policy — and would be mishandled if someone else encountered it without the context?
DIAGNOSTIC QUESTION
“If every runbook in your environment were executed by someone who has never met the engineer who wrote it, how many would fail at the first undocumented step?”
Reducing the Infrastructure Bus Factor Is an Architecture Problem
The instinct when confronted with bus factor exposure is to schedule a documentation sprint and a cross-training program. Both help at the margin. Neither resolves the underlying problem — and understanding why is critical to not solving the wrong thing.
Documentation preserves procedures. It does not automatically preserve operational judgment under failure conditions. The engineer who wrote the runbook and the engineer executing it under a live incident are solving materially different problems. One is recording the steps they know. The other is applying pattern recognition, incident history, and contextual judgment that years of operational experience produce. The procedure can be transferred. The judgment that fills the gaps in the procedure cannot be transferred through documentation — it has to be built through exposure.
This distinction matters because it defines what “reducing bus factor” actually requires. The goal is not comprehensive documentation. The goal is reducing human-exclusive authority — moving operational authority artifacts from people into systems so that the failure of any single person’s availability does not constitute a control plane failure.
Four architectural moves that address bus factor at the structural level:
FOUR ARCHITECTURAL MOVES — REDUCING HUMAN-EXCLUSIVE AUTHORITY
- Automation reduces decision variance. Fewer execution paths require human judgment in the first place. Every automated reconciliation loop removes a category of ad-hoc intervention that would otherwise require the engineer who knows the procedure.
- Pipelines reduce hidden execution paths. When the fast path is the pipeline path — not the engineer’s local terminal — authority concentration has fewer surfaces to form around. The CI/CD control plane post covers the specific design requirements.
- Policy systems reduce memory dependencies. Compliance enforced by code rather than recalled by engineers eliminates the category of authority artifact that lives in someone’s understanding of what is and isn’t acceptable. Policy as code externalizes that judgment into a system.
- Reconciliation systems reduce exception entropy. Drift detected and remediated by systems — rather than remembered by the person who introduced the exception — removes the IaC exception context category from the bus factor surface. The Day 2 operations debt post maps the specific debt categories that accumulate when this isn’t in place.
The Ansible operational governance model — covered in Ansible & Day 2 Ops Architecture — addresses the configuration management layer specifically: the Day 2 mutations that accumulate as informal operational authority when no governance model owns them after Terraform provisioning ends.
None of these moves eliminate the need for experienced engineers. They eliminate the condition where the environment is unrecoverable without specific ones.
SERIES: THE AUTHORITY LAYER
Architect’s Verdict
The infrastructure bus factor is the failure mode that every post-incident review finds and every capacity plan ignores. Organizations invest heavily in redundant hardware, distributed systems, and failover architecture. They treat the team running it as a staffing concern rather than an architectural dependency — which means the same resilience discipline applied to hardware is never applied to operational authority.
The Human Control Plane accumulates by default in every mature infrastructure environment. It is not designed. It grows through operational friction, exception accumulation, and the natural tendency to route difficult problems to the person most capable of solving them quickly. By the time the Knowledge Authority Collapse is visible — when a personnel event exposes how much operational authority was living in a specific person — the environment has been structurally fragile for longer than anyone realized.
The infrastructure survives hardware failure because redundancy was designed into the system. It fails operationally because redundancy was never designed into authority. The organizations that resolve this by returning to private cloud are often doing the same thing at the governance layer — recovering an operating model that the public cloud transition never absorbed
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




