The VMware Exit Has Entered the Coexistence Era
Somewhere around 2025, the enterprise conversation about VMware quietly rewrote its own objective. “Replace VMware” became “reduce VMware dependency” — not in any formal announcement, not in a strategy document, but in the actual architecture decisions organizations were making as migration programs ran longer than planned and the complexity of what they were replacing became clear.
That shift matters more than it first appears. The VMware coexistence era is not a story about migration fatigue or vendor frustration. It is a story about a structural discovery that arrived late in most migration programs: the hypervisor was always the easy part. What organizations discovered — usually after the coexistence phase had already become operational reality — is that the control plane built around the hypervisor was the actual dependency.
The organizations furthest along in their VMware exits are often the ones most willing to retain VMware where operational maturity still matters. Clean exits belong to greenfield estates and organizations with the architectural flexibility to treat the migration as a clean-room exercise. Everyone else is negotiating a path through a dependency graph that is deeper than any PoC revealed.
This post names what is emerging: The Fragmented Control Plane — the operational state that dual-platform architectures produce, why it becomes permanent faster than most migration plans acknowledged, and what it actually takes to manage it as a first-class architectural condition rather than a transition artifact.
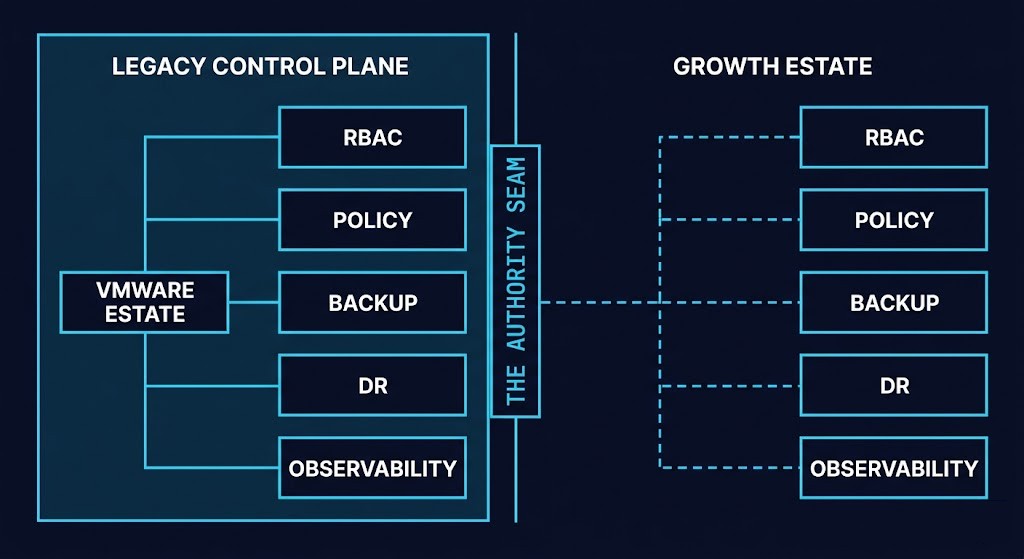
The Industry Finally Accepted There Is No Clean Exit
The 18-to-36-month coexistence window that was originally described as a migration transition estimate is now treated as a baseline planning assumption. Analyst projections put roughly one-third of VMware workloads moving to alternative platforms by 2028. The inverse of that number — two-thirds of workloads not moving, or not moving on any near-term timeline — is the signal that gets less attention.
The VCF 8 end of general support deadline in October 2027 creates real decision pressure. Organizations with 2.5-to-3-year execution cycles needed to complete proof-of-concepts and commercial negotiations by the first half of 2026 to enable phased migration through mid-2027. That window is closing. The pressure is visible in how conversations have changed: CIOs who were evaluating alternatives in 2024 are now making architecture commitments under timeline constraints rather than strategic optionality.
But decision pressure does not create execution speed. The October 2027 deadline forces a platform decision. It does not accelerate the migration of 900 applications with undocumented dependencies, or compress the hardware refresh cycle that was already scheduled for 2028, or resolve the DR asymmetry between a VMware estate with 10 years of validated recovery procedures and an AHV estate that is 18 months old.
What Nutanix’s revenue timing challenges in late 2025 made visible — migrations converting from pipeline to revenue more slowly than expected — is not a demand signal problem. It is a dependency graph problem. Organizations that committed to migration in principle encountered the actual cost of the operational control plane in practice. Legacy dependencies, hardware cycles, and long-term application support requirements extended timelines beyond what PoC success suggested was achievable.
The de facto posture that emerged is: contain the existing VMware environment, route new workloads to alternative platforms, and operate both indefinitely. That is not a failure mode. For most organizations, it is the rational response to what the VMware operational control plane actually is.
DEADLINE PRESSURE
“The October 2027 VCF 8 deadline creates decision pressure without creating execution speed. Organizations that need 2.5–3 years to migrate needed to start PoCs in H1 2026 — which is now.”
Hypervisor Replacement Was the Wrong Mental Model
The hypervisor compute layer is replaceable. AHV, KVM, and Proxmox have all demonstrated this at enterprise scale. Western Union is migrating 900 to 1,200 applications across a 3,900-core fleet. Dartmouth completed its migration and freed its 11-person infrastructure team to manage approximately 1,000 VMs and 600 containers. The mechanism works.
What is not replaceable in a single motion is the operational control plane that vCenter, NSX, vSAN, SRM, and Aria built around the hypervisor over the course of a decade or more of enterprise deployment.
The vCenter assumption stack runs deep. RBAC hierarchies built over years of organizational change. DRS and HA policies encoded with institutional knowledge about which workloads tolerate interruption and which do not. Storage policies tied to application-level SLA requirements. Network policy enforced through NSX constructs that have no direct equivalent in most alternative platforms. DR orchestration built in SRM with validated runbooks, tested failover procedures, and documented RTOs that represent years of refinement.
None of that lives in the hypervisor. All of it lives in the control plane layer that the hypervisor enabled.
The third-party tooling problem compounds this. Veeam, Rubrik, Zerto, and most enterprise backup and DR platforms integrated at the vCenter API layer, not the ESXi layer. Replacing the hypervisor does not automatically migrate those integrations. It breaks them, requiring parallel integration work for every tool that assumed vCenter as its operational surface. The same applies to ITSM integrations, monitoring connectors, compliance tooling, and automation workflows.
The skills gap is a second-order constraint here, not the primary one. Teams that know vSphere deeply do not automatically know AHV or KVM. But the skills gap is an amplifier of the control plane dependency problem, not the root cause. Organizations that treated the migration as a hypervisor swap discovered the control plane dependency when their operational tooling stopped working. Organizations that understood the control plane dependency from the start planned migration of the governance and tooling layers alongside the hypervisor — and their migrations ran closer to schedule.
The lift-and-shift to KVM fallacy documents what happens when this distinction is missed. The hypervisor moves. The operational authority does not follow automatically.

Coexistence Creates the Fragmented Control Plane
NAMED FRAMEWORK — THE FRAGMENTED CONTROL PLANE
The operational state where infrastructure authority is distributed across multiple virtualization platforms, tooling layers, and governance surfaces simultaneously, with no unified authority model binding them.
The Fragmented Control Plane is the architectural condition the Sovereign Virtualization Architecture stage maps as the entry state for most enterprise post-VMware transitions — coexistence is not where the exit ends, it is where governance portability design has to begin.
The VMware coexistence era does not produce two separate and clean operational environments running in parallel. It produces one fragmented one. Every dimension of operational management splits at the platform boundary and diverges from that point.
Two governance paths with different RBAC models, different policy engines, and different enforcement mechanisms. VMware’s RBAC hierarchy, permission inheritance model, and vCenter role structure have no direct equivalent in AHV’s Flow governance model or Kubernetes RBAC. Policies that were consistently enforced across the VMware estate now require separate definition, separate enforcement, and separate audit evidence on the alternative platform.
Two API surfaces with different integration assumptions. Automation built against vCenter APIs — provisioning workflows, change management integrations, monitoring agents — does not transfer to AHV or KVM API surfaces without rewriting. Two sets of integrations means two maintenance surfaces, two upgrade dependencies, and two failure modes.
Two backup attachment models with different consistency guarantees. The backup integration that works against vCenter-managed VMs does not automatically produce the same consistency guarantees against AHV-managed VMs. Recovery procedures validated against VMware estate may not produce equivalent RTOs against alternative platform estate. Two backup paths means two test cycles, two runbook sets, and two validation requirements.
Two lifecycle systems on different cadences. Broadcom’s VCF release cycle, support windows, and upgrade requirements are independent of whatever cadence AHV or Proxmox operates on. Patching windows, upgrade freeze periods, and change management procedures now require coordination across two independent schedules.
The operational complexity of a dual-platform environment increases before it decreases. That is not a temporary condition of early migration. It is the structural reality of the fragmented control plane, and it persists until either consolidation succeeds or the fragmentation is deliberately designed for — whichever comes first.
For organizations with legacy application dependencies, compliance constraints tied to VMware-specific tooling, or hardware refresh cycles that keep VMware-era hardware in production through 2028 or beyond, the fragmentation does not resolve on the timeline migration plans projected. It becomes the permanent operational topology.
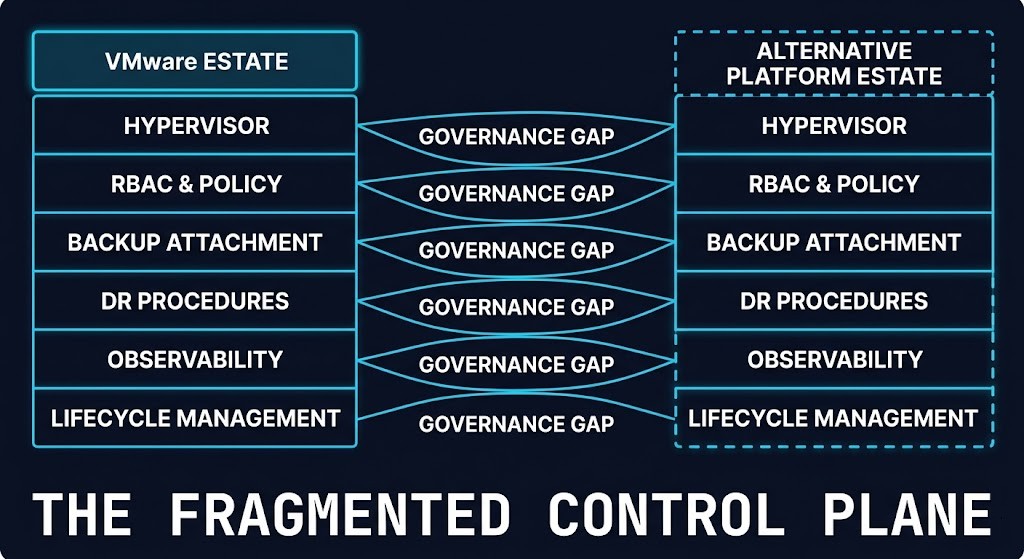
Why Coexistence Stops Being Temporary
Migration programs do not stall because organizations gave up. The VMware coexistence era became permanent for most enterprises not through strategic choice but through collision with compounding operational reality — at some point between the initial PoC success and the final 20% of the workload estate, the program hits what the migration actually requires.
01 — APPLICATION DEPENDENCY REALITY
Application dependency chains that were invisible in the PoC become visible at migration time. Undocumented integrations, hardcoded IP assumptions, and platform-specific behavior that worked in VMware’s execution environment do not survive a clean hypervisor swap.
02 — COMPLIANCE CONSTRAINTS
Compliance requirements tied to VMware-specific DR tooling — SRM orchestration, site-level failover procedures, audit trails built against vCenter APIs — have no equivalent replacement that produces the same certification evidence without significant re-validation work.
03 — DR ASYMMETRY
The VMware estate has years of validated recovery procedures with documented RTOs. The alternative platform estate is 18 to 24 months old at most. The operational maturity gap between the two is not closed by migrating VMs — it is closed by operating the new platform under production conditions long enough to build equivalent confidence.
04 — OPERATIONAL RETRAINING COST
Every workload migrated adds operational retraining cost. Teams operating AHV or KVM alongside VMware must maintain deep competency in both simultaneously. That cost does not amortize quickly at the pace most migration programs actually execute.
05 — TOOLING DIVERGENCE
Backup, SIEM, observability, and ITSM integrations rebuilt for the alternative platform run in parallel with their VMware equivalents. The tooling surface doubles before any consolidation is possible.
06 — EXECUTIVE MIGRATION FATIGUE
Multi-year migration programs compete with new organizational priorities. AI infrastructure investment, cloud repatriation initiatives, and platform modernization programs all consume the same engineering capacity and executive attention. VMware migration becomes a background initiative that progresses when capacity allows — which means it progresses slowly through the hardest workloads.
The final 20% problem is where most migration programs stall. The first 80% of a VMware estate — commodity workloads, development environments, test infrastructure, workloads with no external dependencies — migrates relatively smoothly. The final 20% represents the workloads that are most constrained, most business-critical, and most tightly coupled to VMware-specific platform behavior. That is where the control plane dependency is deepest and where the migration cost per workload is highest.
The migration ROI curve reflects this. Cost savings from early migrations are captured in year one or two. The remaining workloads produce diminishing operational return against increasing migration effort. At some point the calculation shifts: “good enough reduction” in VMware dependency replaces “complete replacement” as the operative objective. The migration program is declared successful at 70% or 80% completion, and the remaining VMware estate stabilizes as a permanent operational layer.
THE FINAL 20% PROBLEM
“The last 20% of a VMware estate typically represents 80% of the remaining migration complexity. Most organizations reach this point and recalculate.”
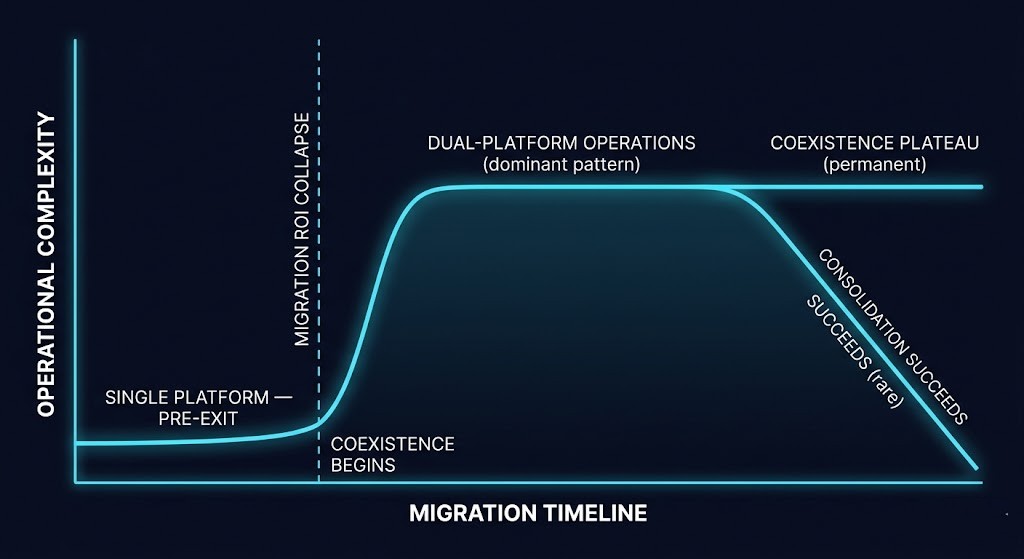
Dual-Platform Operations: The VMware Coexistence Era Default State
The pattern that has emerged across enterprise VMware migrations is not sequential replacement — VMware estate shrinks to zero as the alternative platform grows to 100%. The pattern is workload segmentation with deliberate boundary management. The VMware estate stabilizes. The alternative platform grows alongside it. The boundary between them becomes a permanent architectural feature. This is the VMware coexistence era operating as designed at the application abstraction layer.
Kubernetes has become the operational abstraction layer that makes this workable for many organizations. VMs stay fragmented across platforms; orchestration standardizes above them. The pattern is not Kubernetes replacing VMs — that misreads what Kubernetes is. It is Kubernetes decoupling workload portability and operational consistency from the hypervisor layer below. Teams that run containerized workloads on AHV or bare metal alongside VM workloads on VMware can maintain operational coherence at the application layer while the infrastructure layer remains fragmented.
The Kubernetes as VMware exit ramp architecture pattern captures this. Platform teams reducing VMware dependency by moving containerized workloads off the VM estate while retaining VMware for the workloads that require it — this is dual-platform operations functioning as designed, not as a transition that has stalled.
Sovereign workload isolation represents a different but increasingly common variant. Regulated workloads on VMware — because the compliance certification, the DR validation, and the audit trail all live there — and everything else on the alternative platform. That is not migration lag. It is deliberate architectural segmentation with a security and compliance rationale that makes the VMware retention permanent by design.
The counter-signal is worth acknowledging. ING selected VCF 9 as their strategic private cloud platform in late 2025. Enterprise financial institutions with sovereign compliance requirements and existing deep VMware integration are not always coexistence candidates — some are doubling down on VMware as their long-term private cloud infrastructure. The dominant pattern across the broader enterprise market is coexistence, but coexistence is not universal. Platform choice, estate complexity, and compliance topology all determine which side of the dual-platform pattern an organization lands on.
What the Azure VMware Solution architecture conversation makes clear is that even cloud migration paths have absorbed the coexistence reality — AVS exists precisely because clean VMware exits to native cloud are not the path most enterprises take.
The Real Risk Is Governance Fragmentation
Control plane fragmentation produces governance fragmentation as its primary operational consequence. Two platforms, two authority models, and no single enforcement surface means that every governance objective — access control, policy enforcement, audit evidence, change management — requires separate implementation and maintenance across both environments.
vCenter’s RBAC model, permission inheritance hierarchy, and role structure are not portable. The access control policies built into a mature VMware environment over years of organizational change do not translate automatically to AHV’s Flow governance model, Kubernetes RBAC, or cloud IAM. They require redefinition, with the attendant risk that the redefinition introduces gaps or inconsistencies that the original model did not have.
DR procedures diverge at the platform boundary in ways that compound over time. SRM-orchestrated recovery on the VMware estate and manual or Veeam-orchestrated recovery on the AHV estate do not produce equivalent RTOs, equivalent validation procedures, or equivalent runbooks. Each platform evolves its recovery procedures independently. The gap between them widens as both platforms mature in different directions.
Observability splits. Two monitoring stacks, two alerting configurations, two dashboard surfaces — operational memory distributes across both, and neither captures the full picture. The shadow control plane problem is present in both environments independently, and the fragmentation between them creates a third surface where neither platform’s observability tools see the complete operational state.
Teams revert to platform-specific tribal knowledge as the path of least resistance. This is the governance amnesia pattern — one of the five sovereign architecture failure modes the Sovereign Virtualization Architecture stage defines: operational discipline built on the original platform erodes as the new platform matures and stops being treated as a governance surface. Governance documents become aspirational rather than operational. The Day 2 operations debt that accumulates in IaC environments has a direct parallel in dual-platform virtualization estates — the documented operational model diverges from the actual operational practice faster than governance processes can track it.
At the IaC layer, that same divergence has a specific expression: policies carried forward across a platform transition continue to be enforced by the GitOps control plane long after the operational context that justified them no longer exists — the failure mode Framework #133 — Policy Intent Drift documents.
The compliance and audit surface fractures in ways that are architecturally harder to address than they appear at first. Demonstrating consistent security posture across a fragmented control plane is not just operationally harder. It requires that both platforms produce audit evidence in compatible formats, that both environments are tested under equivalent conditions, and that the gap between them can be explained and justified to auditors who may not understand why two different platforms enforce the same policy differently.
The Cost Surface Fragments Too
Governance fragmentation is visible and felt operationally. Economic fragmentation is visible on the budget line and often understated in migration ROI projections.
ECONOMIC FRAGMENTATION — WHAT DUAL-PLATFORM ACTUALLY COSTS
- VMware support contracts retained for the legacy estate — Broadcom pricing at current subscription rates
- Nutanix or AHV licensing added for the growth estate — new contracts running in parallel
- Backup vendors running two separate integration paths — or two separate backup vendors
- SIEM ingestion and observability licensing doubled — two platforms generating two independent event streams
- DR validation labor doubled — two test cycles, two runbook sets, two platforms to validate
- Operational certifications duplicated — teams need platform competency on both stacks simultaneously, which means training investment in two directions at once
The strategic logic of the VMware exit was sound: reduce licensing exposure, reduce vendor lock-in, recover cost flexibility. The economic reality of the coexistence phase is that it inverts that logic temporarily — and for organizations that stall in the final 20% problem, temporarily becomes permanently.
Most coexistence architectures initially optimize for strategic flexibility at the expense of operational efficiency. The licensing cost trajectory improves on the side of the new platform. The operational cost does not improve until consolidation actually succeeds. For organizations running both platforms indefinitely, the licensing savings from the reduced VMware estate are partially offset by the doubled operational overhead of managing two platforms, two tooling stacks, and two governance surfaces simultaneously.
This is not an argument against migration. It is an argument for modeling the coexistence cost surface honestly in migration ROI projections — which most pre-migration analyses do not.

What Coexistence Actually Requires
“Accepting the fragmented control plane as a planning input — rather than a transition artifact the VMware coexistence era will eventually resolve — is the first architectural decision that separates organizations managing dual-platform operations well from those that are not.
The authority boundary requires explicit definition. Which platform owns which workload class, and why — documented as an architectural decision with a rationale, not as a migration backlog item waiting for resolution. VMware retains regulated workloads with compliance certification requirements. AHV handles new greenfield deployments and containerized workloads. The boundary is documented, maintained, and reviewed as workload placement decisions arise. Without that explicit boundary, workload placement defaults to operational convenience, which produces the worst version of the fragmented control plane — one that is fragmented by accident rather than by design. The architectural work of defining that boundary — translating governance policy, sequencing workload placement decisions, and building the normalization procedures that close the operational maturity gap — is what the VMware Migration Strategy Track covers in depth: five clusters mapping execution physics, failure domains, policy portability, platform decision criteria, and post-cutover governance normalization.
Standardizing at the tooling layer above the hypervisor reduces per-platform divergence at the layers that matter most. For the destination cluster to absorb the governance normalization work this requires — including the operational capacity to run upgrade cycles, rebuild events, and production load simultaneously — the HCI Failure-State Architecture specialization track maps the cluster envelope that coexistence-era HCI deployments must maintain. A single backup platform with integrations maintained for both VMware and AHV, rather than two separate backup vendors. A unified observability stack that ingests from both environments rather than two separate monitoring deployments. IaC tooling that manages both platform estates through a single pipeline. None of this eliminates the fragmentation at the hypervisor layer, but it limits the fragmentation’s propagation into the governance and operational layers above it.
Runbook parity is not optional. Every DR procedure requires a platform-specific variant with documented RTOs and RPOs for each environment. The VMware version and the AHV version of the same recovery procedure will differ in their steps, their tooling dependencies, and likely their time requirements. Documenting both, testing both, and maintaining both as the platforms evolve independently is the operational baseline for dual-platform DR.
The VMware Licensing Cost Model and the HCI Migration Advisor are useful for organizations still in the modeling phase — establishing the cost of holding both platforms against the cost of accelerating consolidation clarifies whether the coexistence plateau is a rational economic decision or a migration program that needs reactivation.
Someone Must Own the Boundary
Coexistence environments create a role that barely existed in single-platform estates: platform arbitration. The function — workload placement decisions, operational boundary management, cross-platform governance, and policy normalization — exists in every dual-platform environment whether or not it is formally assigned. The question is whether it is owned deliberately or handled ad hoc.
In environments where it is handled ad hoc, workload placement decisions default to whoever is handling the provisioning request. Policy normalization happens reactively when an audit gap surfaces or an incident reveals a governance inconsistency. Cross-platform governance is a conversation rather than a process.
Fragmented control planes produce operational seams at every governance, backup, observability, and lifecycle boundary. Those seams do not manage themselves. They require explicit ownership — not as a project management overlay on top of the migration program, but as a first-class operational responsibility in the dual-platform architecture. The CI/CD infrastructure as control plane pattern provides one model for how platform boundary governance can be operationalized through automation rather than tribal knowledge.
Architect’s Verdict
The organizations struggling most with VMware exits are usually trying to replace a control plane with a hypervisor swap. The hypervisor was never the dependency. The control plane was. Most migration programs discovered this only after the coexistence phase had already become operational reality — after the first 80% migrated cleanly and the final 20% revealed the depth of what actually needed to move.
The VMware coexistence era is not evidence the migration failed. It is evidence that the operational dependency graph was deeper than the original migration plan acknowledged. The organizations managing it well accepted that early, defined the authority boundary deliberately, and designed the fragmented control plane as a first-class operational condition rather than waiting for a consolidation that was always further away than projected.
The organizations still waiting for the clean exit — still treating dual-platform operations as a temporary state that will resolve itself when the migration program catches up — are the ones accumulating governance debt at the fastest rate. The coexistence plateau is the operating model. The question is whether it is designed or inherited. Sovereign Virtualization Architecture — Stage 5 — the maturity stage where coexistence governance, control plane portability, and post-VMware sovereignty architecture converge — the architectural destination the Fragmented Control Plane is the entry condition for
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




