Velero Going CNCF Isn’t About Backup. It’s About Control.

The Velero CNCF backup announcement at KubeCon EU 2026 in Amsterdam was framed as an open source governance story. Broadcom had contributed Velero — its Kubernetes-native backup, restore, and migration tool — to the CNCF Sandbox, where it was accepted by the CNCF Technical Oversight Committee. The Sandbox application was originally filed in February 2026.
Most coverage treated this as a backup story. It isn’t.
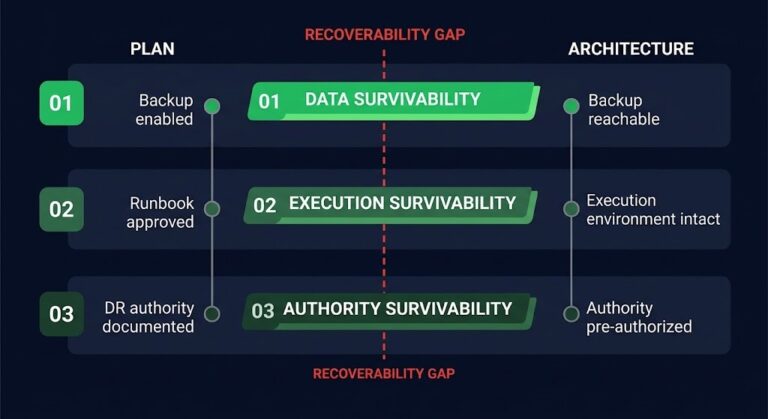
Velero moving to CNCF governance is a control plane story disguised as an open source announcement. The distinction matters — and if your team is running stateful workloads on Kubernetes, understanding the difference between vendor-neutral governance and vendor-independent operations is the architectural decision that sits beneath the headline.
The Architectural Distinction
Vendor-neutral governance means no single vendor controls the roadmap.
Vendor-independent operations means your recovery path survives without them.
CNCF gives you the first. It does not give you the second.
What the Velero CNCF Backup Move Actually Means
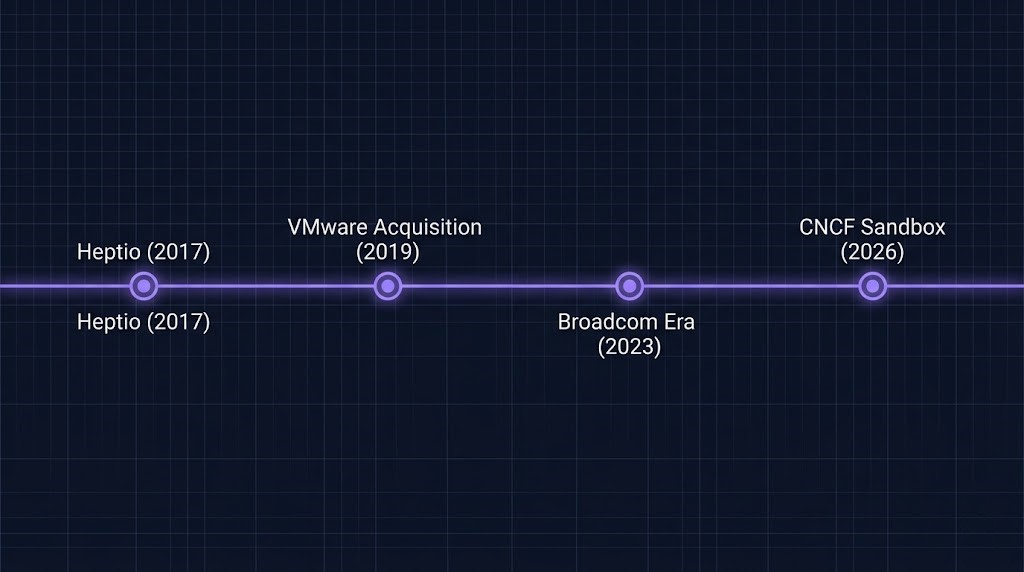
The Velero CNCF backup transition traces its roots further back than KubeCon EU. Velero originated at Heptio, the Kubernetes company founded by former Google engineers Joe Beda and Craig McLuckie, which VMware acquired in 2019. The project has been under VMware — and then Broadcom — stewardship ever since. It operates at the Kubernetes API layer rather than the storage layer directly, which makes it fundamentally different from traditional backup tools. All backup operations are defined via Kubernetes Custom Resource Definitions — Backup, Restore, Schedule, BackupStorageLocation, VolumeSnapshotLocation — and managed through standard Kubernetes control loops.
At KubeCon EU, Broadcom formalized the governance transition: Velero is now a CNCF Sandbox project, with maintainers currently drawn from Broadcom, Red Hat, and Microsoft. The stated goals are widening the contributor base, aligning governance with CNCF standards, and removing the perception that this is a VMware project.
Broadcom’s own framing was direct: “We really don’t want people to mistrust the open source project and believe that it’s somehow a VMware thing even though it hasn’t been a VMware thing for quite some time.”
That sentence is the tell. This move is as much about trust repair as it is about governance mechanics.
What Most Teams Will Get Wrong
Vendor-neutral does not mean vendor-independent.
This is the distinction that matters in production. CNCF governance means Broadcom no longer controls the technical direction of Velero unilaterally. The roadmap is now community-steered, the contributor base will expand, and no single vendor can make breaking changes without community consensus.
What it does not change: how Velero actually runs in your environment. Your backup storage location is still a cloud bucket or S3-compatible endpoint that lives outside your cluster. Your IAM credentials still have to reach that endpoint. Your restore workflow still depends on Velero’s controller being operational inside the cluster you’re trying to recover. The operational dependencies are unchanged by governance.
This distinction trips up most teams because they conflate the licensing story with the operational story. Governance changes who owns the project. It does not change who owns the failure mode.
The Real Architecture Question
When your cluster dies — what actually survives?
This is the question Velero is supposed to answer. And the CNCF transition makes it worth asking more precisely, because the architecture of how Velero works determines exactly what survives and what doesn’t.
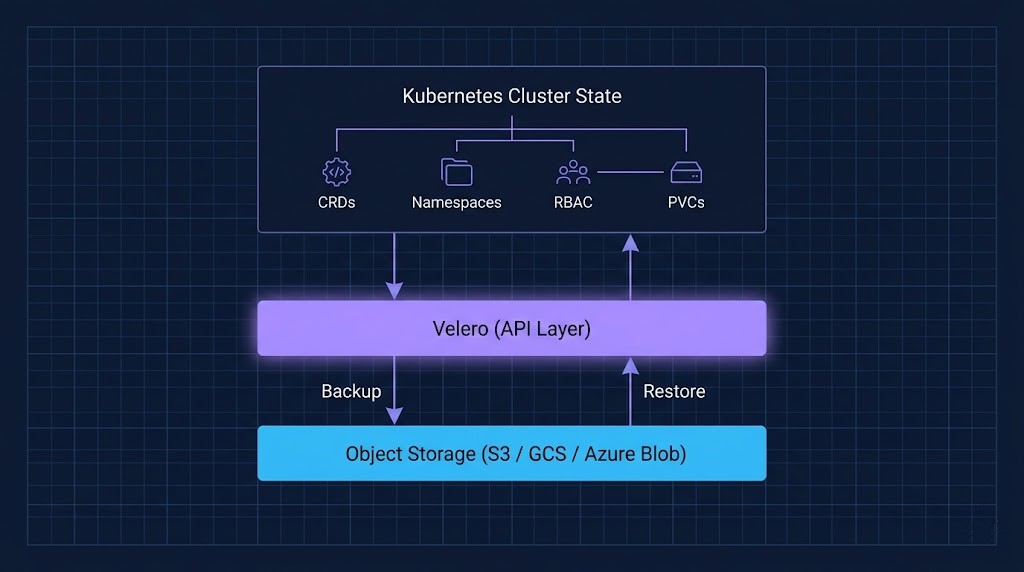
Velero operates at the Kubernetes API layer. This is architecturally significant. It means Velero captures cluster-level state — namespace definitions, resource configurations, persistent volume claims, CRDs, RBAC policies — as Kubernetes objects, not as raw storage blocks. A Velero backup is a portable snapshot of declarative cluster state, not a disk image.
That portability is the real capability. A Velero backup taken on a VKS cluster can theoretically be restored on an EKS cluster, an AKS cluster, or a bare-metal kubeadm deployment — because the backup operates through the Kubernetes API, not through hypervisor or cloud-provider-specific snapshot mechanisms.
This is what makes Velero structurally different from VM-level backup. It is not a storage problem. It is a state reconstruction layer.
Control Plane Survivability: Who Controls What After a Failure
The CNCF governance change is particularly meaningful when you think about it through the lens of control plane survivability — a concept covered in depth in the Sovereign Infrastructure guide.
In a Kubernetes environment, control plane survivability asks: when something fails, what has to be reachable for recovery to be possible?
State Reconstruction Layer
When your cluster dies — what actually survives?
Survives
Object metadata in storage
CRD definitions in backup
Resource specs + RBAC
Persistent volume snapshots
Does Not Survive
Velero controller itself
IAM credential chain
External service bindings
In-cluster backup CRDs
Depends On Your Design
Object storage reachability
Restore target availability
DNS + ingress bindings
External DB connections
For Velero, the answer breaks down into four axes:
| Axis | What Velero Controls | What Velero Depends On |
|---|---|---|
| Backup Definitions | CRDs inside cluster (Backup, Schedule) | etcd — if cluster is gone, so are the definitions |
| Restore Logic | Velero controller + API server | A working target cluster to restore into |
| Metadata | Object metadata, resource specs | Object storage bucket (external) |
| APIs | Kubernetes API layer operations | Cloud provider IAM for bucket access |
The architectural implication: Velero is a state reconstruction layer, not a self-contained recovery platform. It cannot bootstrap a cluster from nothing. It cannot authenticate to object storage if IAM credentials are unavailable. And it cannot run a restore without a target cluster already operational.
CNCF governance does not change any of these dependencies. What it changes is who controls the definitions, APIs, and restore logic at the project level — which matters if you’re concerned about vendor lock-in at the tooling layer, but has no effect on your operational dependencies at runtime.
Where It Still Breaks: The Four Production Failure Modes
Production Failure Modes
These won’t appear in the vendor press releases. Each one is an operational dependency that CNCF governance does not change.
Object Storage Dependency
Backup lands outside the cluster. Restore requires live access to that external endpoint.
IAM Credential Survivability
Authentication is provisioned outside Velero. If identity fails, the data is unreachable.
Restore-Time Complexity
Velero restores Kubernetes objects. External dependencies — DBs, DNS, certs — are not included.
Air Gap Theater
Network isolation doesn’t protect a credential chain that must reach storage at restore time.
This is the section that won’t appear in the vendor press releases.
1. Object Storage Dependency
Every Velero backup lands in object storage — S3, GCS, Azure Blob, or an S3-compatible endpoint. This is external to your cluster. In a full cluster failure scenario, your recovery path requires: the storage bucket to be accessible, credentials to still be valid, and your restore target to have network reach to that endpoint. If you’re in a sovereign, air-gapped, or network-partitioned environment, this dependency is not academic. It is a recovery failure waiting to happen.
2. IAM Credential Survivability
Velero authenticates to object storage using cloud provider IAM — typically an IAM role, a service account with IRSA on EKS, or a Workload Identity binding on GKE. These credentials are provisioned outside Velero. In a failure scenario that involves identity system compromise or cloud control plane unavailability, Velero’s authentication path breaks independently of whether the backup data is intact. The data survives. The ability to access it does not.
3. Restore-Time Complexity
A Velero backup captures what was running. It does not capture the dependencies required for what was running to function after restore — external databases, DNS records, ingress controller configurations, certificate bindings, service mesh policies. Restoring a Velero backup into a freshly provisioned cluster produces a set of Kubernetes objects that may require significant remediation before they’re operational. The closer your architecture is to a fully self-contained cluster, the better Velero performs. The more external dependencies you have, the wider the gap between “backup succeeded” and “system restored.”
4. Air Gap Theater
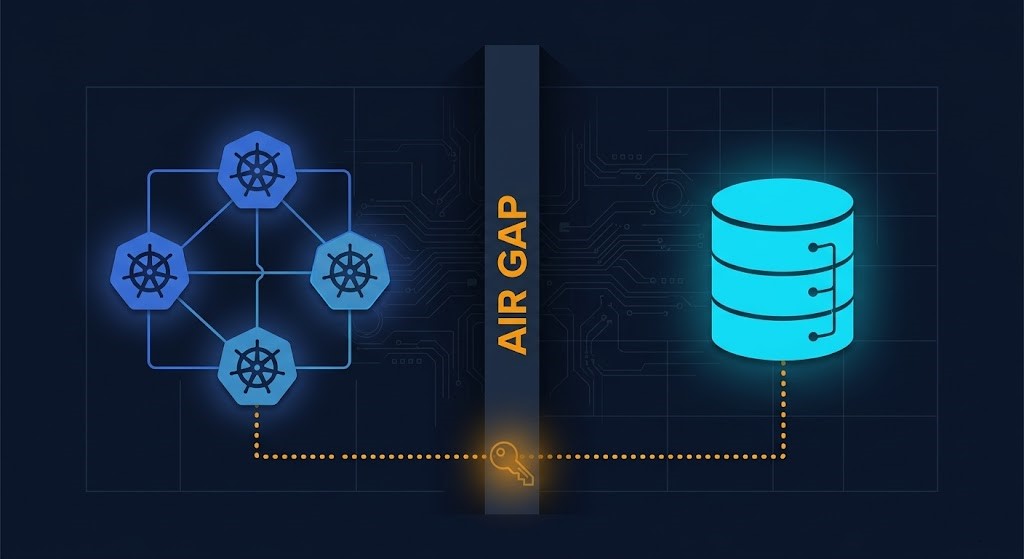
This is the pattern that causes the most damage in regulated and sovereign environments. Teams deploy Velero, configure backups to an on-premises MinIO or Ceph endpoint, declare the environment air-gapped, and close the compliance checkbox. The problem: Velero’s restore path still requires live access to that storage endpoint, live IAM credentials, and a functional Kubernetes API server on the restore target. If any of those three are unavailable — due to the same incident that caused the failure — the air gap is theater. The backup exists. The restore doesn’t work.
This is covered in detail in the immutable backup architecture guide — immutability at the storage layer and restore-path survivability are separate properties that must both be engineered explicitly.
The Broadcom Signal Worth Reading
Set aside the governance mechanics for a moment and read the strategic move.
Broadcom has been navigating a trust deficit since the VMware acquisition — documented across multiple posts on this site. The pricing restructuring, the perpetual license elimination, and the VCF bundling created a market perception problem: that Broadcom would eventually lock down everything it touched.
The Velero CNCF contribution is a counter-signal. By relinquishing direct governance of a project that sits at the center of Kubernetes backup and migration, Broadcom is demonstrating that at least some of its infrastructure stack is genuinely community-governed. Whether that signal holds over time depends on how the project is actually managed under CNCF stewardship — not the announcement.
What it does create immediately is a clearer separation between Velero as an open, portable, community-governed backup mechanism and VKS/VCF as a proprietary platform layer. That separation is architecturally useful for teams evaluating VMware Cloud Foundation: you can run Velero regardless of which Kubernetes distribution you use, which means your backup portability is not contingent on your platform choice.
That is a genuine architectural benefit — independent of any positive framing Broadcom attaches to it.
Architect’s Verdict
The CNCF move is real and it matters — but not for the reasons most teams will act on.
If your concern is Broadcom controlling Velero’s roadmap in ways that disadvantage non-VMware users, that concern is now materially reduced. Community governance, multi-vendor maintainership, and CNCF oversight create real structural separation between the tool and the vendor.
If your concern is operational — whether Velero will work when your cluster is down — the CNCF transition changes nothing. Your object storage dependency still exists. Your IAM credential chain still needs to survive the same incident your cluster didn’t. Your restore-time complexity is still proportional to how many external dependencies your workloads carry.
The teams that will get the most value from this transition are those running multi-distribution environments who previously hesitated to standardize on Velero because of its VMware lineage. The governance change removes a legitimate organizational objection. The operational architecture still requires the same engineering discipline it always did.
CNCF doesn’t remove risk. It changes where the risk lives — from project governance to operational design. Most teams haven’t engineered the latter. That’s the work.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session