Inference Is Becoming the New Steady-State Cost Center

Training was a bounded investment event. Inference is an unbounded operational residency problem.
That distinction is the one most AI cost conversations refuse to make. The infrastructure budget conversation for AI has moved — not from “cheap” to “expensive,” but from “event” to “permanent.” Training had a finish line. Inference steady state does not. Every model you deploy occupies compute, serving infrastructure, and operational overhead continuously, for as long as the application runs. The cost clock never stops, and unlike traditional cloud workloads, there is no idle state that naturally reduces spend.
This matters architecturally because it changes what you are trying to govern. The optimization lever for a bounded workload is efficiency — get the job done with less. The optimization lever for a permanently resident workload is authority — who decides what occupies infrastructure, on what terms, and with what accountability for the aggregate floor. Those are completely different governance problems, and the tooling built for one does not transfer to the other.
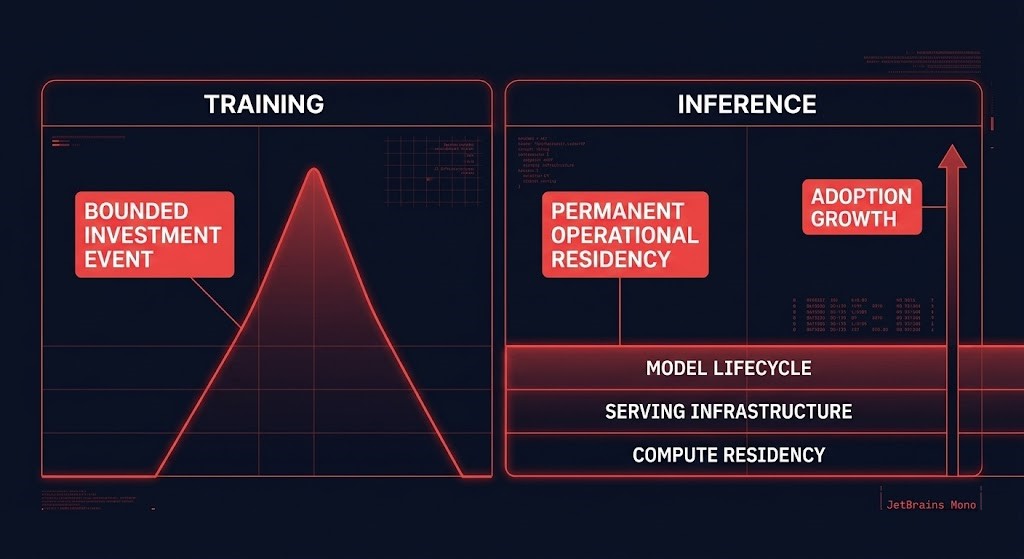
The Inference Steady State Is Not a Phase — It’s the New Baseline
The training phase is a familiar cost shape. You provision GPU capacity, run for days or weeks, and the bill ends when the job completes. Finance understands capital investment with a defined scope. Infrastructure teams know when they are done.
Inference doesn’t work that way. Once a model is in production, it occupies infrastructure permanently. Endpoints stay warm because cold start latency violates SLOs. Concurrency headroom has to be reserved in advance because inference demand spikes do not arrive with warning. Routing layers, token caches, fallback models, and observability pipelines all run continuously alongside the primary serving path. None of this drains away between requests.
This is not a cost-per-request problem. It is a continuous operational presence problem. The inference steady state is the minimum viable infrastructure footprint your AI workload requires at all times — not the average, not the peak, but the floor below which you cannot operate within your SLA commitments. That floor is expensive, it scales upward as adoption grows, and it almost never scales back down.
The teams that treat inference as a usage cost are modeling the wrong variable. Requests are the signal. Residency is the cost. That reframe has architectural consequences that run through every layer of how you design, govern, and account for AI infrastructure. AI inference is the new egress — a cost category that behaves more like data movement than compute consumption.
Why Inference Spend Doesn’t Decay Naturally
Traditional cloud cost guidance assumes workloads have an idle state. You right-size, set autoscaling rules, and trust that underutilized resources will eventually terminate. Inference breaks this assumption in several independent ways, and each one matters for architecture decisions.
Latency SLOs force warm capacity. A model endpoint that takes 8–12 seconds to serve a cold start cannot be allowed to cold-start during production traffic. The only way to guarantee latency budgets is to keep capacity warm — which means paying for capacity whether or not requests are arriving. This is an intentional architectural choice, not an optimization failure. The AI inference execution budget problem is downstream of this: you cannot enforce runtime cost limits on a system architecturally designed to never be idle.
Demand scales with adoption, not with engineering. As applications built on inference endpoints gain users, request volume grows independent of any infrastructure decision you make. You can right-size serving capacity for current demand, but the next product release, the next enterprise customer, or the next marketing campaign changes the floor. Inference spend doesn’t decay — it ratchets upward with product success.
Models proliferate faster than they are retired. Most organizations running production AI systems are adding new models faster than they are deprecating old ones. Each new model brings its own endpoint, its own serving infrastructure, its own monitoring stack. Old models rarely fully exit the environment — canary traffic, A/B testing, fallback routing, and compliance requirements keep them warm at reduced capacity. This is not mismanagement. It is how production AI systems actually operate.
Rollback and canary deployments double temporary residency. A responsible model deployment keeps the previous version live during canary analysis. That temporary doubling of residency becomes a recurring pattern across every model update cycle. At scale, with multiple models and frequent update cadences, the combined canary footprint is a meaningful permanent fraction of your serving spend — and it compounds with every release.
⚠ COMMON MISTAKE
Treating inference cost as a usage optimization problem. The serving floor is permanent by architectural intent — warm capacity, concurrency headroom, and serving infrastructure are not waste to eliminate, they are the mechanism that makes your SLA achievable. Optimizing against them degrades reliability before it reduces spend.
The Persistent Inference Residency Stack
The cost structure of production inference breaks into three distinct layers. Each has a different owner, different optimization physics, and a different failure mode when left unmanaged. Collapsing them into a single “AI spend” line item is why most inference cost reviews produce observations but no actionable decisions.
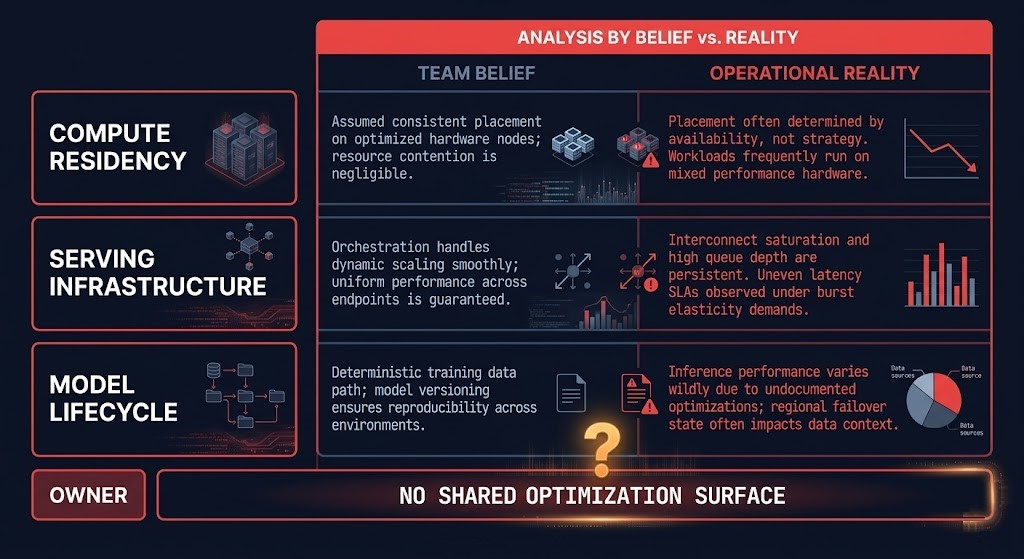
01 — COMPUTE RESIDENCY
What teams think: GPU spend. What actually happens: concurrency reservation. You are not paying for GPU cycles consumed by requests — you are paying for GPU capacity reserved to serve requests within your latency budget. The optimization lever is concurrency modeling, not request volume reduction. Teams that try to cut compute costs by reducing request throughput discover that serving latency blows out first. Owner ambiguity: Platform team optimizes for uptime. ML team optimizes for throughput. Neither owns cost as a first-class constraint.
02 — SERVING INFRASTRUCTURE
What teams think: platform overhead, a rounding error. What actually happens: a permanent operational tax. Load balancers, inference gateways, token caches, request routers, health monitors, and rate limiters are not temporary scaffolding — they are the production serving path. They scale with endpoint count, not request volume, and they rarely appear as a visible line item until someone runs a full infrastructure cost attribution exercise. Owner ambiguity: Platform team provisions it, app team depends on it, finance cannot see it as a discrete line.
03 — MODEL LIFECYCLE
What teams think: temporary rollout cost that goes away after deployment. What actually happens: multiplicative residency growth. Every model version in canary, every fallback model kept warm for reliability, every shadow traffic endpoint running for evaluation — these are not temporary costs. They are structural overhead that compounds with each update cycle. A team running monthly model updates across five production models has a permanent lifecycle residency footprint that, unmanaged, grows without a natural ceiling. Owner ambiguity: ML team owns model versions, platform team owns endpoint lifecycle, neither owns the aggregate residency cost of the combined portfolio.
The Persistent Inference Residency Stack is the governance surface that most organizations do not have a clear owner for. Each layer is managed by a different team with a different optimization target. That is the real problem — and it is structural, not behavioral. AI workloads break traditional FinOps models because the cost authority inversion puts architectural decisions upstream of billing observation — and the residency stack is where that inversion manifests most visibly.
Inference Residency Creep
There is a failure pattern that emerges from the Persistent Inference Residency Stack operating without unified governance: Inference Residency Creep.
Every new inference workload inherits operational overhead that never fully exits the environment. Canary endpoints are retained for rollback safety. Shadow traffic paths stay live for evaluation. Observability infrastructure scales with endpoint count. Token cache layers persist across model versions. Routing configurations accumulate across model families. Each addition is individually justified. The aggregate is a steadily growing residency footprint that no single team has the authority or visibility to address.
The teams most susceptible to Inference Residency Creep are the ones moving fast — adding models, shipping new AI applications, iterating quickly on model versions. These are also the teams doing the most valuable work. The residency growth is a direct byproduct of productive engineering activity. That is what makes it structurally difficult to govern: the incentive structure rewards adding, not auditing.
The pattern compounds in three distinct ways. First, endpoint proliferation — each new model deployment creates a new permanent serving floor even if the previous model’s floor was never fully retired. Second, observability accumulation — monitoring, alerting, and logging infrastructure scales with endpoint count, not traffic, creating a shadow cost that grows in lockstep with the model portfolio. Third, dependency retention — token caches, routing layers, and gateway configurations built for one model generation often persist as dependencies for the next, even when the original model is deprecated.
DIAGNOSTIC QUESTION
“How many model endpoints in your environment were deployed more than six months ago and have never been formally reviewed for deprecation — and what is their combined serving infrastructure footprint?”
Why Rightsizing Stops Working
Standard cloud cost optimization rests on three assumptions. Inference violates all three, and understanding why changes the governance approach entirely.
Idle is accidental. Cloud cost guidance treats underutilized resources as a configuration failure — you set the wrong instance size, forgot to turn something off, left a dev environment running. The fix is right-sizing and autoscaling policies. Inference warm capacity looks idle by this model because utilization is intentionally low between request spikes. The fix is not right-sizing — it is redefining what “idle” means for a latency-constrained workload. Rightsizing tools that flag warm GPU capacity as underutilized are measuring against the wrong baseline. The target utilization for a low-latency inference endpoint is whatever level produces acceptable P99 latency under peak load — which may be 30–40% average utilization for a system architected to handle 3x traffic spikes within SLA.
Elasticity exists. Autoscaling works for stateless workloads that can spin up in milliseconds. Model loading times measured in seconds to minutes mean scale-out cannot respond to traffic spikes in time to prevent SLA violations. The result is that inference serving is architected for peak, not average — persistent overcapacity relative to average load is the correct design. This directly connects to why visibility is not control: FinOps elasticity optimization is not applicable to a workload category where elasticity is limited by physical loading constraints.
Scale-down is safe. Scaling down a serving endpoint to zero between traffic periods sounds economically rational. In practice, the next traffic event produces cold start latency that fails user-facing SLAs, and the re-warm cycle compounds the problem. Teams learn this once. After that, scale-to-zero stops being considered as an option for latency-sensitive endpoints, and the serving floor becomes effectively permanent regardless of what autoscaling policy is nominally configured.

The downstream effect is that the cost control mechanisms available to the teams responsible for cloud spend — rightsizing, autoscaling, spot instances, schedule-based scaling — do not apply cleanly to inference serving infrastructure. This is not a tooling gap. It is a workload physics mismatch. The tools are correct for elastic workloads. Inference serving is not an elastic workload.
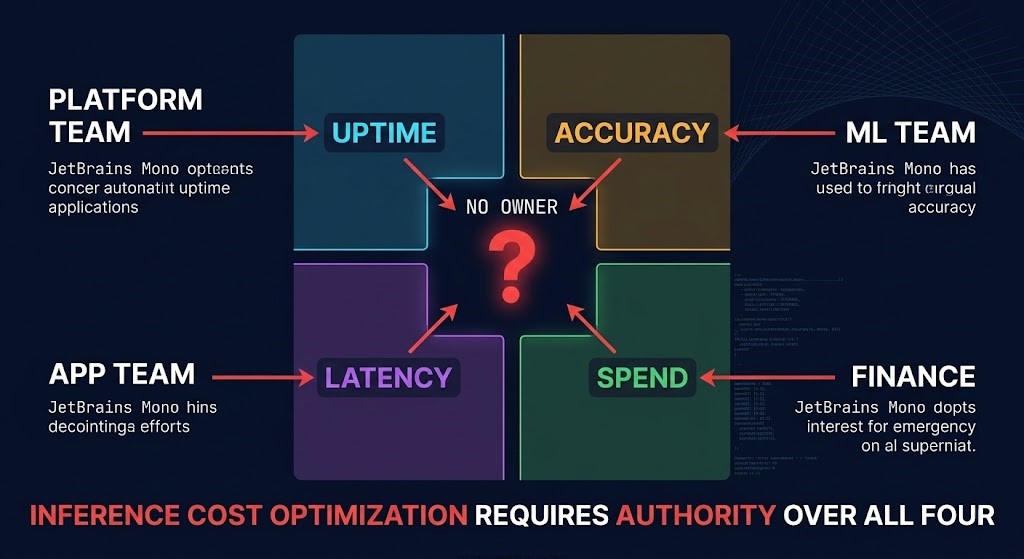
The Governance Problem: Four Teams, No Shared Surface
Inference cost authority is fragmented across teams that optimize for different physics, and none of them own the combined optimization surface.
The platform team owns uptime. Their success metric is endpoint availability and SLA compliance. They provision conservatively, keep warm capacity, treat scale-down as a risk. They are not wrong.
The ML team owns accuracy. Their success metric is model performance and output quality. They run canary deployments, maintain fallback models, keep previous versions warm during evaluation windows. They are not wrong.
The application team owns latency. Their success metric is response time and user experience. They set the latency SLOs that drive warm capacity requirements, request the concurrency headroom that defines the compute floor, and escalate when P99 spikes. They are not wrong.
Finance owns spend. Their success metric is budget variance and cost-per-unit trending. They have no visibility into the operational physics producing the cost structure and no authority to change the decisions driving it. They are also not wrong.
The governance failure is not that any individual team is making bad decisions. It is that inference cost optimization requires simultaneous authority over all four dimensions — and no organizational structure naturally produces that. The Cost Authority Inversion is most acute in inference: the people who understand the cost do not control it, and the people who control it do not share a common optimization target.
DIAGNOSTIC QUESTION
“Who in your organization owns the combined optimization surface across compute residency, serving infrastructure, model lifecycle, and latency SLOs — simultaneously? If the answer is nobody or a committee, the cost problem is a governance gap, not a budget problem.”
What Governance Actually Requires
The teams that close the governance gap do it by creating an ownership surface that doesn’t map to any single existing team. In practice this looks like one of three models.
An inference platform team with explicit cost authority alongside reliability authority. This team owns the serving layer — not just uptime, but the aggregate residency footprint, endpoint lifecycle, and the trade-off between latency SLOs and serving cost. It is structurally distinct from a generic platform team because it has explicit mandate over cost decisions that other teams currently own by default. The platform team becoming a finance team dynamic is exactly this transition played out at the infrastructure layer.
A model portfolio governance process that treats the set of production models as a managed portfolio with explicit entry and exit criteria. New model deployments require a residency cost estimate. Existing models require periodic review against utilization and value thresholds. Canary retention policies have defined maximum durations. This does not require a new team — it requires attaching cost governance to the existing ML release process.
An inference cost attribution architecture that makes residency costs visible at the model level, not just the aggregate. When the ML team can see the serving cost of each model they own — including lifecycle overhead, canary retention, and shadow traffic — the incentive structure changes. Cost visibility is not cost control, but granular attribution at the model level creates accountability that aggregate AI spend dashboards never produce.
None of these is a complete solution independently. All three together create overlapping governance coverage that matches the distributed ownership structure of the problem.
Architect’s Verdict
Inference steady state cost is not an AI problem. It is an infrastructure residency problem that happens to involve AI. The workload characteristics — permanent warm capacity, concurrency-based pricing physics, multi-layer serving infrastructure, lifecycle overhead that compounds with every update cycle — these are architectural constraints that predate the cost question. The cost is a symptom. The residency model is the disease.
Most organizations treating this as a FinOps problem will produce dashboards and reports that accurately describe costs they cannot change, because the decisions that create those costs were made at the architecture and governance layer, not the procurement layer. You cannot optimize your way out of a residency model you never explicitly designed.
Training made AI expensive. Inference makes AI operationally permanent.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




