Deterministic Networking: The Missing Layer in AI-Ready Infrastructure
Deterministic Networking for AI Infrastructure: Engineering the System Backplane
Deterministic networking is the infrastructure requirement that most AI cluster designs get wrong — not because the concept is misunderstood, but because it gets treated as a networking problem when it is actually a systems problem. In the legacy data center, networking was a best-effort transport layer. If a packet was delayed, the TCP stack handled retransmission, and the workload simply waited. In AI infrastructure, that assumption breaks at scale. When compute is distributed across hundreds or thousands of GPUs, the network ceases to be a cable between servers — it becomes the system backplane. Non-deterministic behavior in that backplane doesn’t slow your training job. It stalls it entirely.
To scale, architects must move beyond raw throughput and start engineering for determinism. Deterministic networking in AI infrastructure requires deliberate topology design, buffer allocation, and failure-state modeling — not just faster ports. This is the physical foundation of HCI Architecture and AI-Centric Cloud Design.
Architecture Context:
The Bandwidth Fallacy: Throughput vs. Tail Latency
Raw port speed cannot compensate for unstable latency behavior. While the industry fixates on 400G and 800G upgrades, infrastructure physics dictates that Tail Latency (P99) is the true governor of AI performance.
The Real Enemy: Tail Latency Amplification
In distributed AI training, a single delayed node amplifies tail latency and stalls the entire synchronization cycle. If 511 GPUs finish their calculation in 10ms, but one GPU is delayed by a network “Incast” event (buffer microburst), the entire cluster stalls.
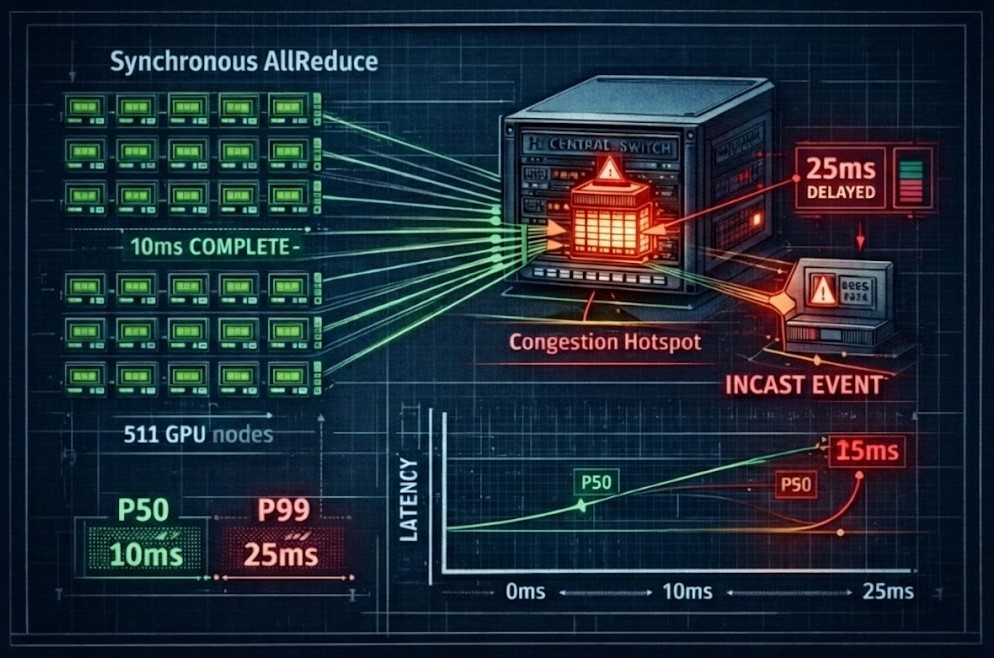
Measurable Engineering Guidance:
| Metric | Healthy AI Fabric | Warning Sign |
|---|---|---|
| P99 Latency | < 2x P50 | > 5x P50 |
| Packet Loss | 0% under load | Any measurable drop |
| Oversubscription | 1:1 | >3:1 |
AI scalability is a physical systems problem. Failure to control tail latency results in Gradient Synchronization Stalls, where expensive compute silicon sits idle waiting for the fabric to resolve a congestion event.
East-West Dominance & HCI Amplification
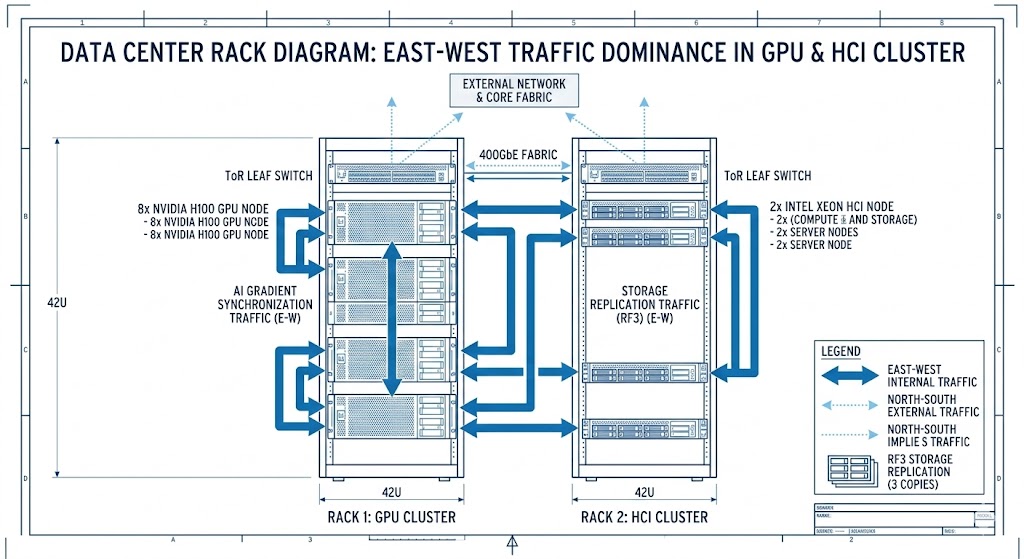
In modern AI clusters, the traffic pattern has shifted almost entirely to East-West (node-to-node). When running GPU-dense nodes powered by AMD accelerators or high-density HCI platforms like Nutanix AOS and VMware vSAN, the network fabric must simultaneously carry:
- AI Gradient Synchronization: High-priority, jitter-sensitive GPU traffic.
- Distributed Storage Replication: Massive RF2/RF3 write payloads.
- Rebuild Traffic: Heavy bursts during node or disk failures.
- Metadata Coordination: Low-latency heartbeats for cluster consistency.
If these traffic classes are not isolated via Deterministic Buffer Allocation, a storage rebuild can “poison” the latency pool for the AI training job. In multi-site or stretched cluster deployments, this is where validation tools such as Nutanix Metro Latency Scout become mandatory to verify that your East-West jitter remains within these synchronous thresholds.
Architect’s Note: For a deeper look at how these networking bottlenecks impact sovereign compute and the rise of GPU-specific clouds, read our analysis on Designing AI-Centric Cloud Architectures in 2026
Deterministic Networking: What It Actually Means
Deterministic networking is not a single feature — it is a rigorous design philosophy that must be enforced at every layer of the AI infrastructure stack. In practice it requires:
- Symmetric Leaf-Spine Topology: Ensuring every node is equidistant with zero internal fabric oversubscription (1:1 ratio).
- ECN over PFC Prioritization: Using Explicit Congestion Notification (ECN) to signal slows-downs before Priority Flow Control (PFC) triggers a “pause,” which can lead to catastrophic Head-of-Line (HoL) Blocking and “pause storms”.
- Deterministic Buffer Allocation: Selecting switches with sufficient MB-per-port to absorb microbursts without dropping packets.
- Failure-State Modeling (N+1): In a deterministic design, you utilize Adaptive Routing and pre-calculated N+1 headroom to ensure that if a leaf switch fails, the traffic re-patterning doesn’t push the remaining spines to 120% load and collapse the training job.
The Failure-State Multiplier
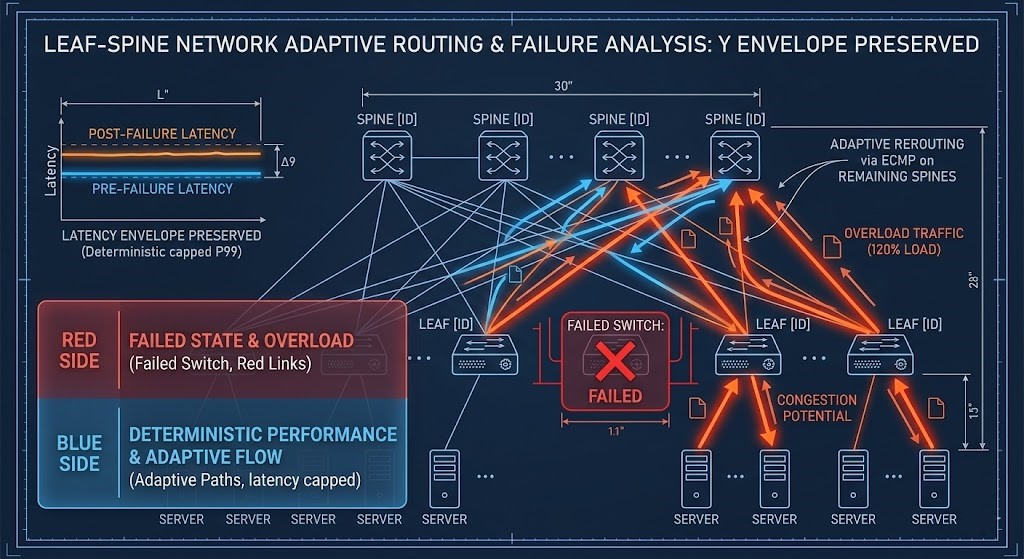
Architects often size for steady-state, but the network proves its value during a Failure-State. When a leaf switch fails or a storage node rebuilds, traffic does not just increase—it re-patterns.
If a fabric is operating at 70% utilization during normal training, a single failure can push specific spine links to 120% effective load. In a non-deterministic network, this leads to buffer exhaustion and massive packet loss. In a deterministic fabric, N+1 headroom and adaptive routing absorb failure-state traffic without violating P99 latency thresholds.
Fabric Comparison: RoCEv2 vs. InfiniBand
The architectural decision between Ethernet (RoCEv2) and InfiniBand will define AI infrastructure design through 2026 and beyond.
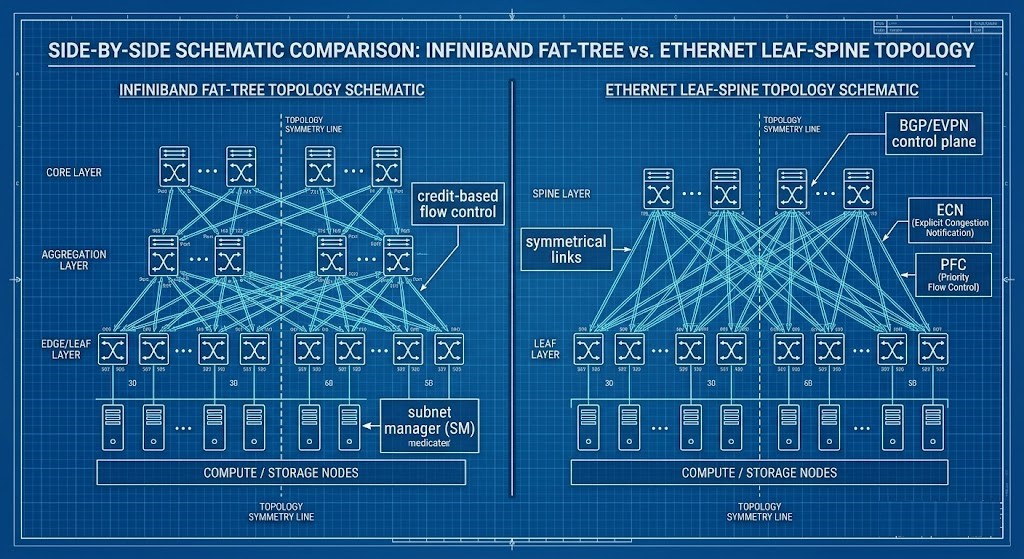
| Feature | InfiniBand (NDR/XDR) | Deterministic Ethernet (RoCEv2) |
| Latency Physics | Native Credit-Based Flow Control | Buffer-Based Flow Control (PFC/ECN) |
| Reliability | Zero-Drop by Design | Lossless via Configuration |
| Topology | Strict Fat-Tree | Flexible Leaf-Spine / Clos |
| Management | Centralized Subnet Manager | Distributed Control Plane (BGP/EVPN) |
| Cost Profile | Specialized Hardware Premium | Commodity Scaling Economics |
For the full fabric architecture decision framework — topology selection, cost physics, failure modes, and sovereign cluster design — see the Distributed AI Fabrics pillar.
Moving Toward NetDevOps: Continuous Validation
Modern networking requires moving away from manual CLI changes and toward Continuous Validation Pipelines. To maintain determinism and prevent performance decay. These networking invariants must be enforced through Infrastructure as Code & Drift Enforcement and automated drift detection.
- Telemetry-Driven Congestion Detection: Real-time visibility into buffer utilization at the nanosecond level.
- Automated ECN Threshold Tuning: Dynamically adjusting congestion signals based on workload burstiness.
- Fabric Symmetry Validation: Automated checks to ensure that drift in cabling or configuration hasn’t created hidden oversubscription points.
Architect’s Verdict
Most AI infrastructure networking failures are not bandwidth failures. They are determinism failures — environments where the fabric was sized for throughput and designed for steady-state, but never validated for tail latency behavior under load or failure-state traffic re-patterning.
The practical implication is that deterministic networking for AI infrastructure is not a procurement decision. It is a design discipline. You can buy 400G ports and still build a non-deterministic fabric if the topology is asymmetric, the buffers are undersized, or the ECN thresholds are misconfigured. Conversely, a well-engineered leaf-spine fabric at 100G will outperform a poorly configured 400G environment on every metric that matters to a distributed training job.
The three things that actually determine whether your fabric is deterministic: topology symmetry with 1:1 oversubscription, ECN tuned ahead of PFC to prevent pause storms, and N+1 headroom validated against failure-state traffic re-patterns — not steady-state utilization. If you haven’t validated all three under simulated failure conditions, you haven’t validated your fabric.
Canonical Engineering Resources
- NVIDIA Spectrum-X: Deterministic Ethernet for AI Design Guide
- Cisco AI Factory: Validated Design for AI-Ready Fabrics
- Arista Networks: Designing AI Spines for Large-Scale Clusters
Q: Why do AI workloads require deterministic networking?
A: Because distributed training amplifies packet jitter into GPU idle cycles.
Q: Is 100GbE sufficient for AI clusters?
A: Bandwidth is necessary but not sufficient — buffer and congestion behavior matter more.
Q: How does HCI complicate AI networking?
A: Because compute, storage, and GPU traffic share the same fabric.
Q: Can traditional three-tier networks support AI?
A: Only at small scale. Leaf-spine architectures are required for deterministic latency.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




