Service Mesh vs eBPF in Kubernetes: Cilium vs Calico Networking Explained
Kubernetes networking has historically been split across two layers: the Container Network Interface (CNI), which handles pod-to-pod connectivity and network policy, and the service mesh, which adds application-layer features like mutual TLS, traffic routing, and observability.
For years the common architecture looked like this:
- A CNI plugin such as Calico provided basic network connectivity and Layer 3/4 policy.
- A service mesh like Istio added Layer 7 features using sidecar proxies injected into every pod.
The rise of eBPF-based networking has started to collapse these layers. The Cilium vs Calico decision sits at the center of this shift — both CNIs can now enforce policy, capture telemetry, and perform traffic management directly in the Linux kernel without sidecar proxies
That shift raises a new architectural question for platform teams: if the network layer can already provide identity, encryption, and observability, do you still need a service mesh at all?
Most teams add a service mesh because someone said they needed one. Istio gets installed, sidecars get injected, and six months later the platform team is debugging mTLS failures they didn’t have before. The cluster is more observable — and significantly more fragile.
The question worth asking in 2026 isn’t “which service mesh should we run?” It’s “do we actually need a service mesh at all?”
The full architectural framework for making that decision — including the four control surfaces a mesh enforces, the cost physics of sidecar vs ambient vs eBPF, and the trigger list that determines when a mesh is justified — is covered in the Service Mesh Architecture pillar.
eBPF changed the answer. If you’re working through the K8s Day 2 Method diagnostic framework, this is where the network loop gets architectural — not just operational.
WHAT A SERVICE MESH ACTUALLY SOLVES
A service mesh exists to solve four problems: mutual TLS between services, traffic management (retries, circuit breaking, weighted routing), Layer 7 observability, and policy enforcement at the application layer.
These are real problems. In a microservices platform with 50+ services, you need mTLS, you need visibility into when a downstream service is degrading, and you need to enforce who can talk to what. The question is whether a sidecar proxy injected into every pod is the right mechanism — or whether the kernel can do it better.
The full container security architecture that frames these requirements — including zero-trust network policy at the cluster level — is covered in the Kubernetes Cluster Orchestration pillar. The complete service mesh decision framework — when a mesh is the right architecture, when eBPF eliminates the need entirely, and where mesh deployments break down in production — is in the Service Mesh Architecture pillar.
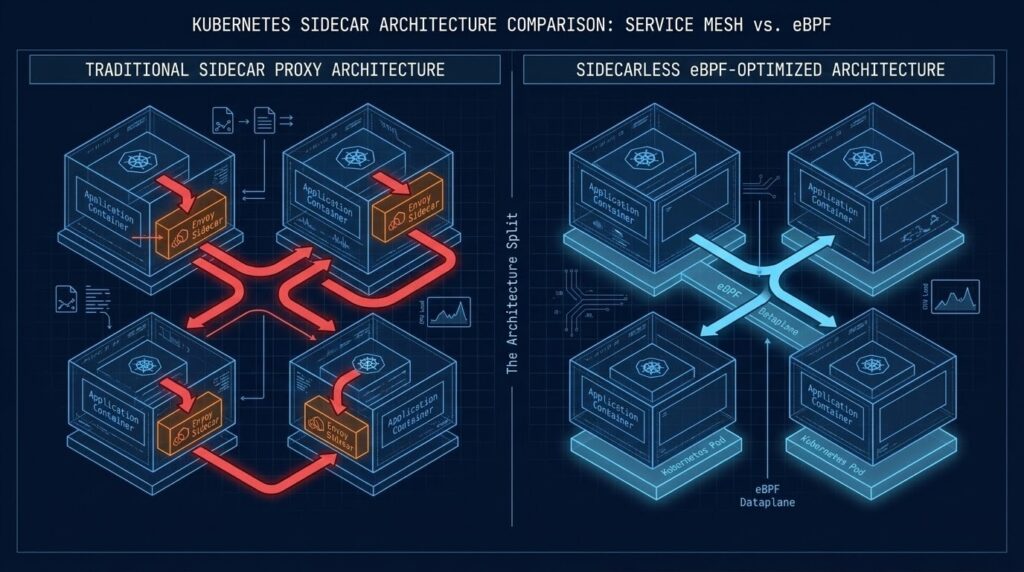
THE SIDECAR TAX
Traditional service meshes like Istio inject an Envoy proxy sidecar alongside every application container. Every network call — even pod-to-pod on the same node — transits through two proxies before reaching its destination. That’s latency on every request, plus memory overhead per pod that compounds at scale.
On a cluster with 500 services, the sidecar model can consume 25–50GB of additional memory compared to a sidecar-free alternative. Those aren’t abstract numbers — that’s real node capacity you’re purchasing back.
There’s also the operational surface area. Sidecar injection configuration, proxy version alignment, mTLS certificate rotation, Envoy filter ordering — each is a category of failure mode your platform team now owns permanently. The same misconfiguration drift that silently breaks mTLS is the same class of problem covered in the Infrastructure Drift Detection Guide — manual overrides that never get reconciled back to policy.
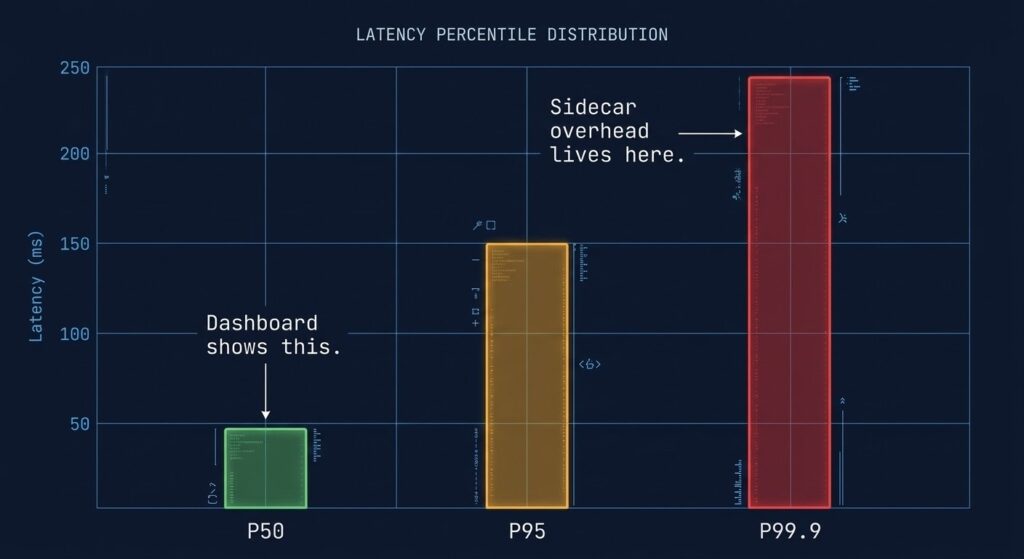
WHAT EBPF ACTUALLY CHANGES
eBPF lets you attach programs directly to the Linux kernel’s network stack. Instead of traffic routing through a userspace proxy, policy enforcement and observability happen at the kernel level — before the standard network stack processes the packet.
For Kubernetes networking this means two things. First, packet processing is faster because the userspace round-trip is eliminated entirely. Second, you can enforce Layer 7 policies — HTTP path filtering, gRPC service filtering, DNS-aware controls — without a sidecar in sight.
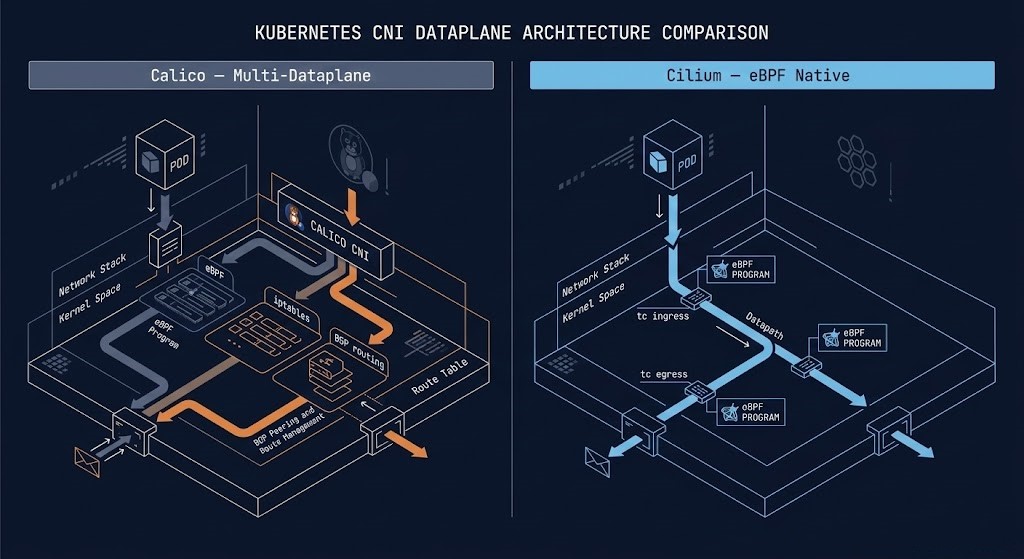
Cilium is the most mature implementation of this model. Calico, historically the default CNI for enterprise clusters, now offers an eBPF dataplane alongside its traditional iptables model — though it remains multi-dataplane, falling back to iptables where kernel requirements aren’t met. The MTU and overlay encapsulation issues that cause 502 errors in ingress paths apply equally to eBPF tunnel configurations — the debugging methodology in It’s Not DNS (It’s MTU): Debugging Kubernetes Ingress applies directly here. Need a cluster to test these configurations? DigitalOcean Kubernetes supports Cilium natively on managed clusters.
Cilium vs Calico: The Real Architectural Split
The Cilium vs Calico split is architectural, not just feature-level. Both tools solve Kubernetes networking — but they make fundamentally different bets on where policy enforcement and observability should live.
Calico is multi-dataplane — eBPF, iptables, Windows HNS, and VPP are all supported options. Its BGP-based routing model integrates cleanly with physical network infrastructure, which matters in enterprise environments where your K8s cluster doesn’t live in isolation. It’s predictable, debuggable with standard Linux tools, and reliable in brownfield environments where you can’t guarantee a modern kernel across every node.
Cilium is eBPF-native — every feature runs through the kernel. The performance ceiling is higher, the observability model via Hubble is deeper, and L7 policy enforcement is first-class. The major cloud providers have already voted: GKE Dataplane V2, AKS with Azure CNI Powered by Cilium, and AWS EKS increasingly default to Cilium in greenfield configurations. The tradeoff is that eBPF debugging is harder — when a packet drops inside a kernel program, standard Linux tools won’t show you why.
DECISION MATRIX
>_ SCENARIO CNI DECISION MATRIX
| Scenario | Recommendation | Reasoning |
|---|---|---|
| Greenfield cluster, modern Linux kernel (5.10+) | Cilium | eBPF-native, sidecar-free mesh, Hubble observability out of the box |
| GKE, AKS, or EKS managed cluster | Cilium (default) | Cloud providers have standardised — work with the grain, not against it |
| Brownfield enterprise, mixed OS, BGP fabric integration | Calico | Multi-dataplane flexibility, Windows node support, standard Linux debugging |
| Regulated environment, strict compliance baseline | Calico Enterprise | GlobalNetworkPolicy, HostEndpoint protection, audit-ready controls |
| 500+ services, high throughput, L7 policy required | Cilium | O(1) rule lookup, identity-based policy, no iptables chain bloat at scale |
| Calico running fine, no L7 requirement | Stay put | CNI migration risks cluster-wide outage — don’t migrate for its own sake |
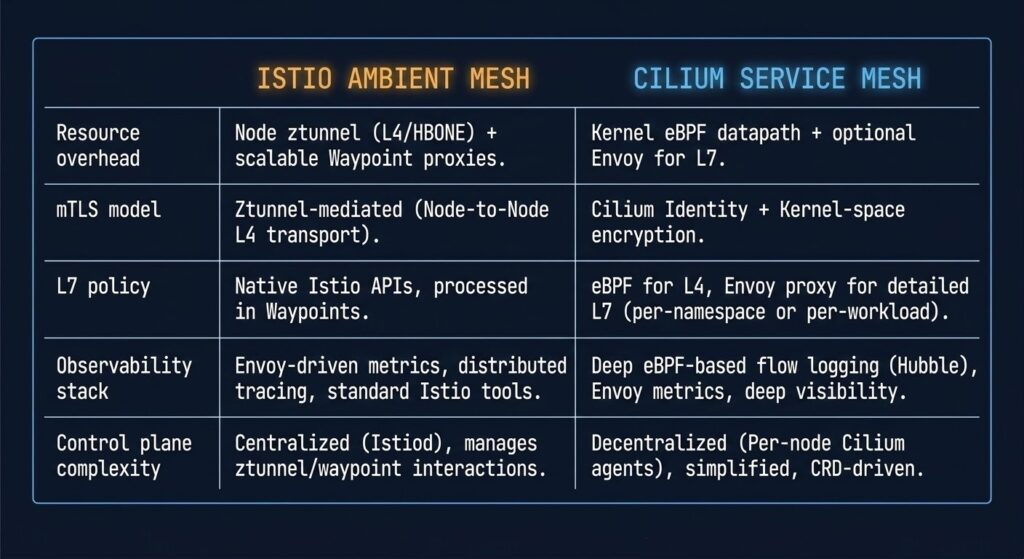
THE ISTIO QUESTION
If you’re running Istio today, you have options that didn’t exist two years ago. Istio’s ambient mesh mode — which removes per-pod sidecars in favour of a node-level proxy — reached production readiness in 2025. It’s a meaningful improvement to the operational model and brings resource overhead closer to the eBPF range.
But if you’re evaluating a service mesh from scratch and your CNI is Cilium, the answer is that you may not need Istio at all. Cilium covers mTLS via SPIFFE identity, L7 traffic policy, load balancing, and observability through Hubble — without adding a second control plane. The complexity budget you’d spend on Istio is better invested in the application layer.
The caveat: Cilium’s mutual authentication model uses eventual consistency for policy sync. In environments where security policy must be instantaneous and fully auditable, Istio’s synchronous model remains the more defensible architectural choice.
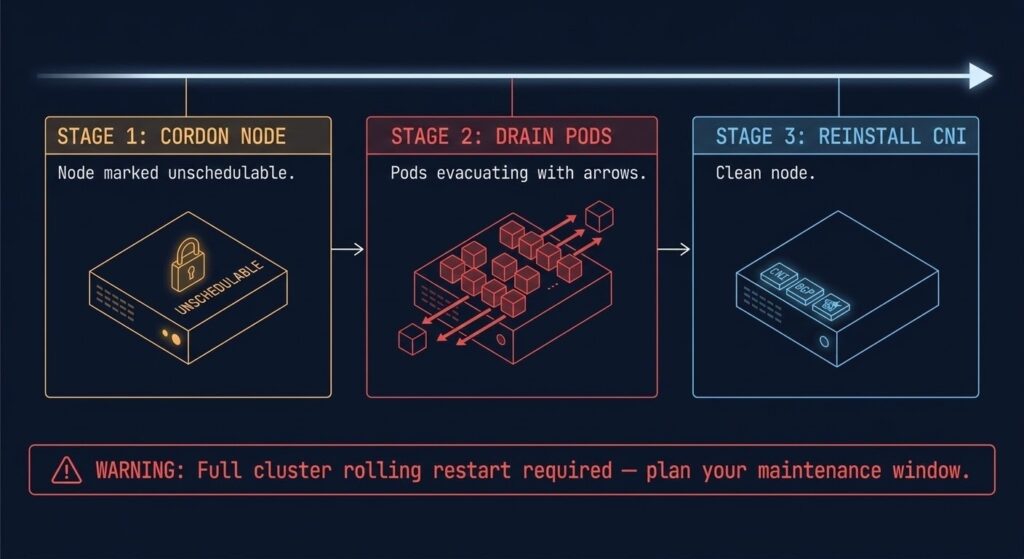
MIGRATION REALITY
One detail glossed over in every CNI comparison: migrating between CNIs in a running cluster requires draining every node. That means a full rolling restart — pod by pod, node by node. In a production cluster with stateful workloads, this is not a Saturday morning task. It’s a planned maintenance window with tested rollback procedures.
The Cilium vs Calico migration decision has one rule: if Calico is working, the bar for switching to Cilium should be ‘we need what Cilium provides’ — not ‘Cilium is newer’. Evaluate against your actual L7 policy requirements, your observability gaps, and whether your node fleet kernel versions support eBPF reliably before committing.
The IaC angle matters here too. Cilium and Calico both have Terraform providers, but provider feature parity lags significantly behind CLI capabilities — especially for Cilium’s newer eBPF-specific features. Validate provider support before building your pipeline around capabilities that may not be in the provider yet. The Modern Infrastructure & IaC Learning Path covers the governance framework that prevents policy drift between dev, staging, and production CNI configurations across the full IaC lifecycle.
ARCHITECT’S VERDICT
The service mesh conversation has shifted. The Cilium vs Calico question is no longer about which CNI has better iptables support — it’s whether the kernel can replace the proxy entirely.
For greenfield platforms on modern infrastructure, Cilium answers that question convincingly. For brownfield enterprise environments with BGP fabric integration, mixed OS node fleets, or compliance requirements that need audit-ready policy controls, Calico remains the more pragmatic choice.
Pick the tool that matches your actual operational reality. Not the one with the best conference talk.
Cilium and Calico both have Terraform providers — but provider support consistently lags behind CLI capabilities, especially for eBPF-specific features. Before building your IaC pipeline around a CNI feature, verify it’s actually in the provider. The Terraform Feature Lag Tracker surfaces the gap between cloud API releases and Terraform provider support so you don’t architect around functionality that isn’t there yet.
→ Check CNI Provider Support LagFrequently Asked Questions
Q: Do I need a service mesh if I’m already using Cilium?
A: Not necessarily. Cilium provides mTLS via SPIFFE identity, L7 policy enforcement, load balancing, and full observability through Hubble — all without a sidecar proxy. If your requirements are covered by Cilium’s feature set, adding Istio introduces a second control plane without proportional benefit. Evaluate your specific mTLS, traffic shaping, and audit requirements before committing.
Q: Can I run Cilium and Calico on the same cluster?
A: No. Kubernetes runs a single CNI plugin per cluster. Migrating between them requires a full node drain and CNI reinstall on every node — it’s a planned maintenance operation, not a configuration change.
Q: Is Calico’s eBPF dataplane the same as Cilium?
A: No. Calico’s eBPF dataplane is one option within a multi-dataplane architecture — it can also run on iptables, Windows HNS, and VPP. Cilium is eBPF-native, meaning every feature is architected around the kernel model. The observability stack, identity model, and L7 policy enforcement differ significantly between the two.
Q: What Linux kernel version does Cilium require?
A: Cilium requires Linux kernel 4.9.17 minimum for basic functionality. Kernel 5.10+ is recommended for the full eBPF feature set including sidecar-free service mesh via Mutual Authentication. Audit your node fleet kernel versions before planning a CNI migration.
Q: What’s the production risk of migrating from Calico to Cilium?
A: High if not planned correctly. CNI migration requires draining every node in the cluster, meaning a rolling restart of all workloads. Stateful applications require extra care — validate PersistentVolume reclaim behavior and ensure your rollback procedure is tested before the maintenance window begins.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session