LLM OPERATIONS ARCHITECTURE
Runtime Governance Over Probabilistic Infrastructure. Control Planes, Not Deployment Scripts.
LLM operations architecture is not a deployment problem. It is a runtime governance problem — and that distinction determines whether your production AI systems remain controllable or quietly compound toward failure.
The mental model most teams bring to LLM deployment comes from application delivery: build, package, ship, monitor. That model worked when software produced deterministic outputs, when the artifact was the entire system, and when rolling back meant reverting a version. None of those assumptions hold for production LLM systems. The output is probabilistic. The artifact is one component among many — weights, tokenizers, serving framework, retrieval layer, router configuration, prompt templates, execution budgets. Rolling back the model without rolling back the retrieval index or the prompt version produces a different failure than the one you’re trying to escape. And the cost of doing nothing compounds silently through token consumption, retry accumulation, and behavioral drift that no standard infrastructure dashboard surfaces until it appears on a bill.
LLM Ops is not model deployment. It is runtime governance over probabilistic infrastructure.
The organizations getting this right are not the ones with the best models. They are the ones who treated the inference runtime as a production system with the same operational rigor they apply to their transactional databases — versioned artifacts, enforcement boundaries, observability instrumentation, and explicit rollback architecture — before the first production incident made those decisions urgent. The organizations getting it wrong are running inference workloads with no token ceilings, no artifact signing, no rollback path, and no way to attribute cost to the workflows producing it. The infrastructure looks operational. The control plane is absent.
This page maps the full LLM operations architecture: what governs a production LLM system and why, where the LLM Operations Control Plane sits in the AI infrastructure stack, how the five governance layers interact, and what the named failure modes look like when any one of them is missing. The framing throughout is enterprise runtime governance — not tooling commentary, not deployment tutorials, and not vendor comparison.
What LLM Ops Actually Is
The discipline called LLM Ops emerged because the operational requirements of large language models in production do not map onto the operational requirements of any infrastructure category that preceded them. Not application delivery. Not traditional MLOps. Not API services. Not batch processing pipelines.
Traditional MLOps was built for training pipelines and tabular models — deterministic systems where a given input produces the same output, where the artifact is the model file, and where operational concerns center on training stability, dataset management, and batch prediction throughput. LLM Ops operates in an entirely different domain. The output is probabilistic. The artifact is not a file — it is an assembly of weights, tokenizer, serving framework, prompt template, retrieval configuration, and runtime policy. The operational concern is not training stability. It is runtime governance: ensuring that a nondeterministic system behaves within defined operational boundaries under cost pressure, across changing models, with shared GPU infrastructure, and with evolving prompts — while maintaining the predictability that enterprise production systems require.
That distinction has architectural consequences at every layer. You cannot version an LLM system the way you version an application binary. You cannot roll back a production LLM deployment by reverting the model weights without also reverting the prompt templates, the retrieval index version, the embedding model, and the router configuration that was in place when that model version was validated. You cannot hand inference cost to a FinOps dashboard built for EC2 reservation optimization and expect it to surface token consumption rate trends, retry storm accumulation, or the incremental token ceiling relaxations that double inference spend without triggering any infrastructure alert. And you cannot observe a production LLM system the way you observe a stateless API — because modern LLM systems are not stateless, a point the Inference State section of this page addresses in full.
What LLM Ops actually governs is the operational control plane for a system where the compute is probabilistic, the cost is behavioral, the state is distributed, and the failure modes are invisible to standard infrastructure tooling. The five layers of that control plane — artifact governance, serving infrastructure, runtime enforcement, observability, and lifecycle governance — are what this page maps. Gaps in any one of them produce failures. Gaps in multiple layers produce the kind of compound operational failure that arrives as an inexplicable quarterly bill or a production incident with no clear root cause and no clean rollback path.
Why Production LLM Systems Fail
Production LLM systems fail in predictable ways. Not through hardware failure or network partition — those failure modes are handled by the same infrastructure practices that govern any production system. They fail through governance gaps: missing or wrong artifacts in the serving path, runtime systems with no enforcement boundaries, observability instrumentation that tracks the wrong signals, and lifecycle processes that treat model deployment as a one-time event rather than an ongoing operational discipline.
The seven failure modes below account for the majority of production LLM incidents. They are named — not as taxonomy, but because named failure modes are diagnosable. An on-call engineer who recognizes a KV Cache Saturation Cascade at 2am resolves it faster than one diagnosing an ambiguous latency incident with no operational vocabulary for what they are seeing.
Seven failure modes with one thing in common: none of them are hardware failures. None of them are network failures. All of them are governance failures — missing enforcement, missing versioning, missing observability, missing authority boundaries. The infrastructure was operational. The control plane was not.
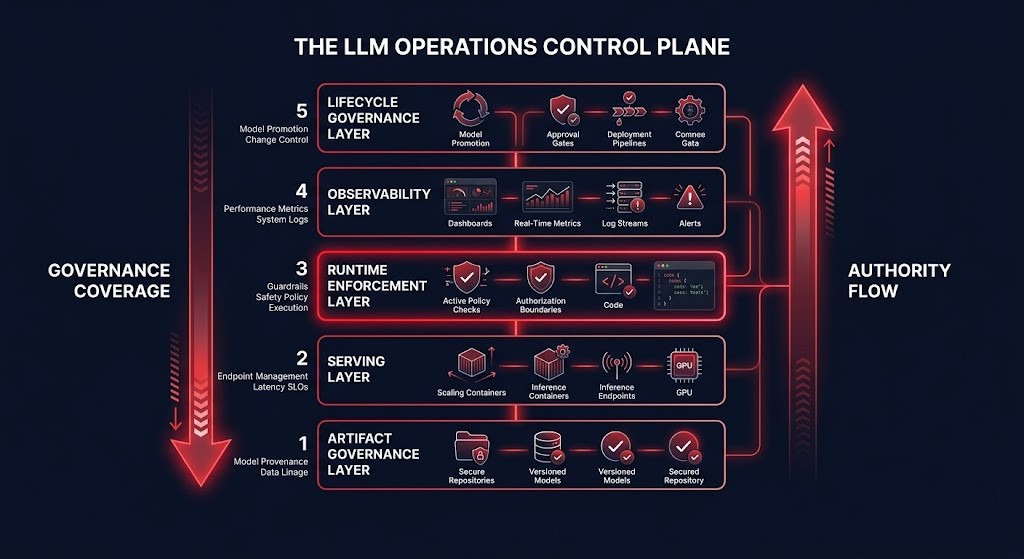
The LLM Operations Control Plane
The LLM Operations Control Plane is the governance architecture that sits above the model and below the application. It does not train models, serve tokens, or manage GPU allocation directly. It governs the systems that do — enforcing artifact integrity, routing authority, execution constraints, observability coverage, and lifecycle policy across the entire inference runtime.
The control plane concept is not new to infrastructure. Terraform’s control plane manages infrastructure state. GPU orchestration governs accelerator scheduling and CUDA isolation. Distributed AI fabric architecture governs the network backplane for gradient synchronization. In each case, the control plane is what makes the execution layer deterministic under changing conditions. For LLM systems, the equivalent is the LLM Operations Control Plane — and most production AI deployments are operating without a coherent one.
The control plane comprises five governance layers. Each layer addresses a distinct operational domain. Failures in any layer produce specific, predictable failure modes. Gaps across multiple layers produce compound failures that are expensive to diagnose and impossible to cleanly remediate.
The Runtime Authority Fragmentation Problem
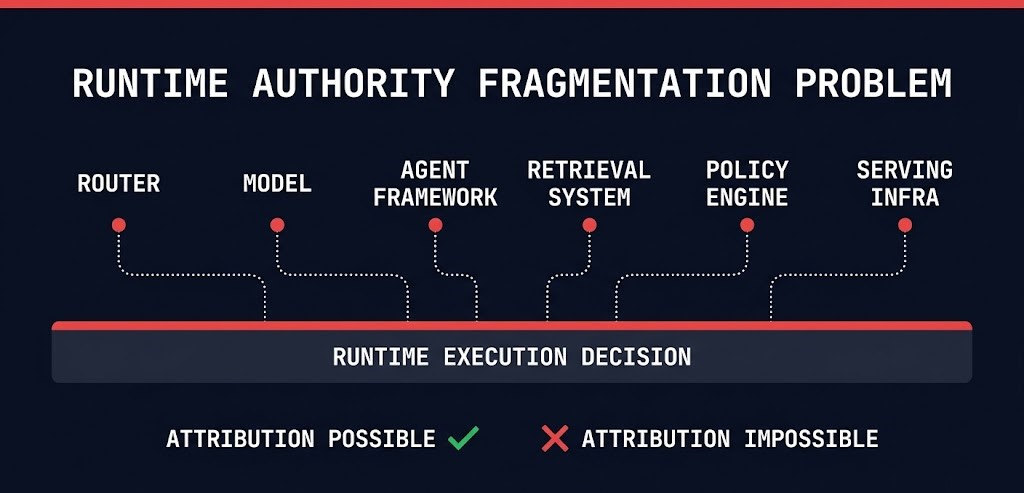
The five-layer control plane exists to address a problem that has no equivalent in traditional infrastructure: authority fragmentation. Traditional production systems had a relatively singular execution authority path — the application called the service, the service executed the logic, the result was deterministic. The authority for any given execution decision was locatable and attributable.
Modern LLM systems distribute runtime authority across six or more simultaneous domains. The router decides which model handles the request. The model produces the output given the prompt context. The agent framework decides which tools to invoke and in what sequence. The retrieval system determines what context is injected. The policy engine enforces guardrails on input and output. The serving infrastructure manages batching, scheduling, and memory allocation. All six are operating simultaneously. None of them owns the final execution decision. The output is a product of their interaction — and when that interaction produces a failure, attributing causality requires reconstructing all six authority domains at the moment of failure.
This is the Runtime Authority Fragmentation Problem. It is not a tooling gap. It is a structural property of how modern LLM systems are built. When a production incident occurs — wrong output, unexpected cost spike, policy violation, latency regression — the incident response process must answer: which authority domain produced this behavior, and what was its state at the time? Without governance architecture designed to answer that question — versioned artifacts, execution logging, router audit trails, retrieval context capture — replay becomes impossible, rollback boundaries blur, and observability fragments across six systems none of which has the full picture.
The consequence for incident response is direct: you cannot remediate what you cannot attribute. The LLM Operations Control Plane is built to make attribution possible — each layer creates an audit surface for one authority domain, and together they make the full execution context reconstructable.
Artifact Governance Layer
The artifact governance layer starts with a definition most teams skip: a model artifact is not the weights file. It is the complete assembly of everything required to reproduce a specific inference behavior — weights, tokenizer, system prompt templates, serving framework version, runtime dependencies, and the CUDA and driver versions the model was validated against. Treat any subset of that assembly as the artifact and you have a governance gap. That gap is where Ghost Deployment originates.
OCI-compliant model registries are the correct storage and distribution architecture for model artifacts at production scale. OCI registries — the same standard used for container images — provide content-addressable storage, cryptographic integrity verification, access control, and pull-through caching. They are not the only option, but they are the option with the most mature tooling for signing, scanning, and audit logging. The governance rule that follows from this choice is absolute: if an artifact is not stored in the registry, it does not exist as a production artifact. If it is not signed, it does not enter the production inference path. No exceptions for “temporary” testing models or “quick” hotfixes — those exceptions are where Shadow Model Routing starts.
Cryptographic signing closes the integrity gap between storage and serving. A signed artifact pointer means that the serving infrastructure can verify, at load time, that the weights and configuration it is serving are exactly the ones that passed validation — not a modified copy, not a version that was silently replaced, not the output of a pipeline that had an undocumented parameter change. Signing is not an audit compliance checkbox. It is the mechanism that makes rollback meaningful: you are reverting to a known, verified state, not to a file that happens to have the right name.
Immutable artifact pointers are the operational discipline that makes the registry model work under deployment pressure. When a model is promoted to production, the deployment records a pointer to a specific, immutable artifact digest — not a mutable tag like latest or v2 that can be silently updated. When rollback is triggered, the pointer reverts to the previous digest. The model that runs is exactly the model that ran before. No ambiguity. No silent updates. No version drift between what the deployment system believes is running and what is actually serving requests.
The failure mode this layer prevents most directly is Rollback Without Context — but only if the artifact definition is complete. Weights alone are insufficient. The prompt templates, retrieval index snapshot reference, and serving framework configuration that were validated alongside those weights must be versioned as part of the same artifact bundle, or the rollback restores the weights into an incompatible operational context. This is the part most teams discover during their first failed rollback rather than before it.
The artifact governance layer connects directly to the GPU Orchestration and CUDA architecture — CUDA version and driver compatibility are runtime dependencies that belong in the artifact definition, not in an ad-hoc runbook. A model validated against CUDA 12.2 that is deployed into a cluster running 12.4 may behave differently in edge cases that only surface under production load.
The Inference Runtime Architecture Split
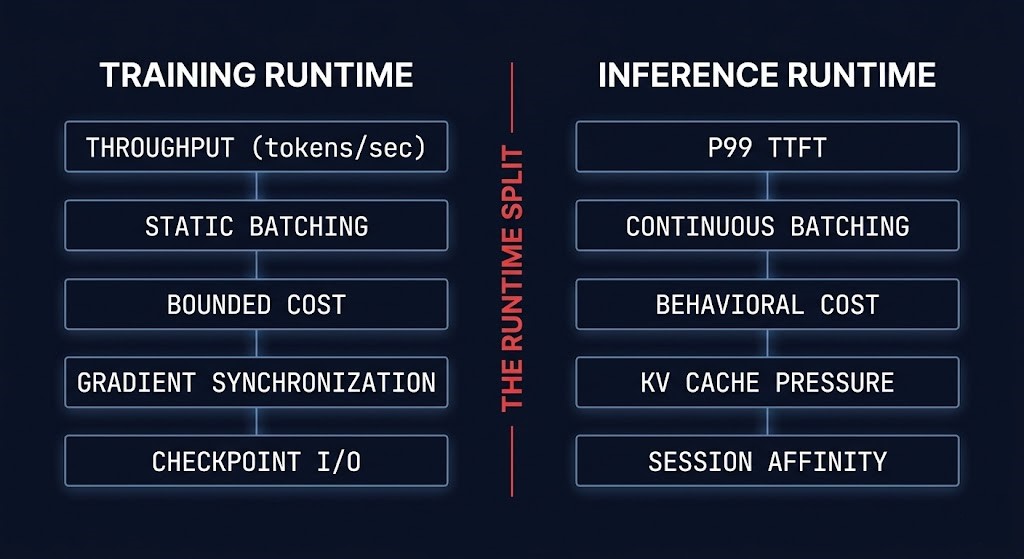
Training infrastructure and inference infrastructure are not versions of the same system. They are optimized for opposite physics — and operating inference workloads on training-optimized hardware with training-optimized serving configuration is one of the most reliable ways to produce an LLM system that is simultaneously expensive and slow.
Training is optimized for throughput: maximize the amount of gradient computation completed per unit of time, tolerate high latency per individual operation, and accept that all jobs in a training cluster are running the same model at the same time. Inference is optimized for latency predictability and concurrency stability: minimize Time to First Token for interactive workloads, maintain consistent P99 latency across a heterogeneous mix of request types, and manage a serving runtime where multiple models may be hot simultaneously against a shared GPU memory budget. The training/inference hardware split that GTC 2026 formalized at the silicon level reflects an architectural reality that infrastructure teams have been managing in software for years — these are different systems, and they need different operational models.
The gap between them is largest at the serving runtime layer. Understanding the architecture of that gap is prerequisite to configuring any inference serving stack correctly.
Continuous batching is the most operationally significant serving architecture shift in modern inference infrastructure, and the concept that explains why vLLM’s adoption curve looks the way it does. Naive request-response serving allocates a fixed batch of requests, runs the entire batch to completion, then processes the next batch. GPU utilization during the completion phase of long requests in a batch drops — shorter requests have finished, but the hardware is committed to the batch until all sequences terminate. Continuous batching — also called iteration-level scheduling — processes requests at the token generation level rather than the sequence level. As individual sequences in a batch complete, new requests fill their slots immediately without waiting for the entire batch to finish. The result is consistently higher GPU utilization, lower queue depth under load, and 2–4x throughput improvement over static batching at equivalent hardware cost.
The architectural consequence for inference operations: continuous batching transformed inference serving from request-response execution into queue-optimized runtime orchestration. The serving layer is no longer processing discrete requests — it is managing a continuous stream of token generation operations with dynamic slot allocation. This changes how you instrument it (queue depth and slot utilization matter more than request count), how you size it (memory headroom for KV cache growth under continuous load, not peak batch memory), and how it fails (slot exhaustion and KV cache pressure, not timeouts on individual requests).
Speculative decoding provides a different throughput lever — using a small draft model to generate candidate tokens that a larger verification model accepts or rejects in parallel. For workloads where the draft model’s predictions are frequently correct (structured outputs, constrained domains, predictable response patterns), speculative decoding can reduce TTFT significantly without changing the effective model quality. The operational overhead is the draft model itself: it consumes GPU memory, requires its own artifact governance, and introduces a second version dependency into the deployment bundle.
KV cache locality governs the memory efficiency of multi-turn and RAG workloads. When a user sends a follow-up message in a multi-turn conversation, the KV cache from the previous turn should be reused rather than recomputed. Session affinity — routing requests from the same session to the same serving instance — is the infrastructure mechanism that makes cache locality possible. Without session affinity, every turn in a multi-turn conversation recomputes from context, multiplying per-request compute by the conversation depth. At scale, this is not a minor inefficiency: it is the difference between a serving infrastructure that handles multi-turn workloads within cost bounds and one that doesn’t.
Model sharding and tensor parallelism become the serving architecture when a model’s weight size exceeds the VRAM of a single GPU. Tensor parallelism splits individual matrix operations across multiple GPUs — each GPU holds a shard of the weight matrix and processes its portion of every forward pass in parallel. Pipeline parallelism places different layers of the model on different GPUs, processing requests in a pipeline. Both approaches introduce a hard dependency on low-latency GPU interconnect — the same distributed AI fabric requirements that govern training cluster architecture, applied to the inference serving stack. A sharded inference deployment that hits fabric P99 latency problems exhibits the same stall behavior as a distributed training job: all shards must synchronize before the next layer executes. The physics are identical. The operational context is different.
Runtime Controls and Execution Budgets
Inference cost is a runtime systems problem. Not a finance problem, not a FinOps problem, not a problem that resolves by adding cost attribution dashboards to an instrumented spend report. The cost driver is behavioral — token consumption, retry frequency, agent loop depth, context window utilization — and behavioral cost drivers are only controllable at the moment of execution. Once a token is generated, the cost is incurred. The enforcement boundary must sit before generation, not after reporting.
The teams getting blindsided by inference spend are not doing anything wrong operationally in the sense that their infrastructure is misconfigured. They are applying the wrong cost model. FinOps tooling built for EC2 reservation optimization cannot see token consumption rates per workflow, retry storm frequency per agent, RAG pipeline chunk count changes, or the recursive execution depth of agentic loops. GPU utilization can look healthy — at 70%, nothing in the standard infrastructure dashboard flags a problem — while inference spend compounds through behavioral patterns that are entirely invisible to GPU-level instrumentation. The cost architecture that makes this visible requires a different instrumentation model: per-request token consumption tracked over time, cost attributed per workflow, retry rates tracked per agent.
Execution budgets are the primary enforcement mechanism for making inference cost a controlled runtime property rather than an emergent billing outcome. An execution budget is a runtime constraint that limits how many tokens an agent or workflow can consume, how many model calls it can make, how many retries it is permitted, and how deep a recursive agent loop can run — enforced at the moment of execution, not reported after the fact. The full execution budget architecture covers the enforcement patterns in detail. The operational principle is simple: if the ceiling is not enforced in the runtime, it does not exist as a cost control. A token limit defined in a policy document and not implemented in the inference gateway is not a limit — it is an aspiration.
Tiered model routing is the cost optimization lever with the highest return per unit of implementation effort. Not every inference request requires the same model. A classification task, a short summarization, a structured extraction — these do not require a 70B parameter model to produce a correct result. Routing simple requests to smaller, cheaper models and reserving large models for requests that genuinely require their capability reduces inference cost without degrading output quality for the majority of traffic. The cost-aware model routing architecture covers the routing decision logic — which signals govern the routing decision, how to validate that the cheaper model’s output quality is acceptable for the request class, and how to instrument the routing layer so that cost attribution follows the model, not just the endpoint.
Invisible token amplification is the cost failure mode that most frequently surprises teams operating agentic systems for the first time. A workflow that invokes three tool calls per request, each of which invokes a model call, each of which returns context that feeds the next layer, can consume 10–20x the token budget of the surface-level request that triggered it. The amplification factor is invisible at the request level — the original request looks like a standard inference call. The cost is in the chain it triggers. Without per-workflow token consumption tracking and agentic loop depth limits enforced at the runtime layer, the amplification compounds silently until a billing cycle makes it visible. By then, the cost is historical. The autonomous systems drift analysis covers how small behavioral deviations in agentic systems accumulate into large, irrecoverable cost events when no runtime enforcement boundary exists.
Security and Authorization Boundaries
Security in LLM operations is not a perimeter problem. Traditional security architecture draws a boundary around the system and enforces access controls at the edge — authenticate the caller, authorize the request, log the transaction. That model fails for LLM systems because the attack surface is not at the boundary. It is inside the execution path. Prompt injection does not bypass authentication. It manipulates the model’s behavior after authentication has already succeeded. Data exfiltration does not traverse a firewall. It occurs through outputs that a legitimately authorized user receives. Authorization boundary failures in LLM systems are not access control failures in the traditional sense — they are runtime governance failures, which is why they belong in the runtime enforcement layer, not in a network security checklist.
The security architecture for production LLM systems covers three distinct domains. Each requires a different enforcement mechanism and maps to a different failure mode.
Prompt injection is the attack class with no direct equivalent in traditional infrastructure. An attacker — or an untrusted data source in a RAG pipeline — embeds instructions in content that the model processes as context. The model follows those instructions, treating them as legitimate operator directives. The mechanism is not a bug in the model. It is a consequence of how LLMs process context: they do not have a runtime distinction between “instructions I should follow” and “data I should process.” The enforcement architecture that mitigates prompt injection operates at the input layer — structured prompt templates that constrain the surface area where injected instructions can execute, input validation layers that detect and reject adversarial patterns before they reach the model, and output validation that catches policy violations in generated content before it reaches the caller. None of these are complete defenses. They are layers that raise the cost of a successful injection and surface anomalies for incident response. The LLM authorization boundary architecture covers the specific enforcement patterns for each layer.
RBAC on inference endpoints is the mechanism that prevents Shadow Model Routing from becoming an authorization failure rather than just an operational one. Every inference endpoint — every model, every serving tier, every routing configuration — should have explicit access controls tied to caller identity. Developers cannot call an endpoint they are not authorized to call. Workflows cannot invoke models outside their approved routing path. When a Shadow Model Routing incident occurs in an environment with proper endpoint RBAC, it fails at the authorization layer rather than accumulating silently as an operational gap. The authorization controls on inference endpoints are also the mechanism that closes the agentic authority gap: an agent framework that is not explicitly authorized to call a specific model cannot call it, regardless of what its prompt template instructs it to do.
Input and output logging is the forensic foundation that makes the Runtime Authority Fragmentation Problem tractable during incident response. Every request to every inference endpoint — the full input context, the model and version that processed it, the output produced, the token count, the latency, the caller identity, and the routing path taken — must be logged in an immutable, queryable audit record. This is not observability in the operational sense. It is forensic infrastructure. When a policy violation surfaces, when an unauthorized output is reported, when a cost anomaly needs to be traced to a specific workflow — the audit log is the only source of truth for reconstructing the execution context. Environments that log at the infrastructure level (GPU utilization, request count, endpoint health) but not at the execution level (what was sent, what was returned, by whom, through which path) cannot perform meaningful incident forensics on LLM failures.
The agentic control plane problem makes the authorization architecture more complex in one specific way: agents can invoke model endpoints, tool endpoints, and other agents — and each invocation carries its own authorization context. An agent that is authorized to call a summarization model is not automatically authorized to call a code execution tool or a customer data retrieval endpoint. Agent permission scopes must be explicitly defined, explicitly enforced, and explicitly audited. The Runtime Authority Fragmentation Problem applies here with particular force: in an agentic execution chain, the authorization context at any point in the chain is a product of who initiated the original request and what permissions propagated through each invocation layer. Without explicit scope enforcement at each layer, authorization authority fragments across the chain — and a permission granted at the top of a workflow can propagate into sub-agents or tool calls it was never intended to reach.
The Inference State Problem
The foundational assumption most teams bring to inference infrastructure — that inference is stateless — was approximately true for first-generation API serving. A request arrived, a response was generated, the system returned to baseline. No state persisted between requests. Each request was independent. The operational implications of that model are simple: scale horizontally, load balance freely, any instance can serve any request.
That model does not describe modern LLM systems in production. It describes a simplified version of inference that no longer exists at the workload classes enterprise teams are actually running.
Modern LLM systems maintain operational state across at least six dimensions simultaneously. Each dimension creates an operational dependency that changes how the serving infrastructure must be designed, how incidents must be investigated, and how rollback must be architected. Together, they constitute what we call the Inference State Explosion — the expansion of operational state surface area beyond anything that traditional stateless API governance was designed to handle.
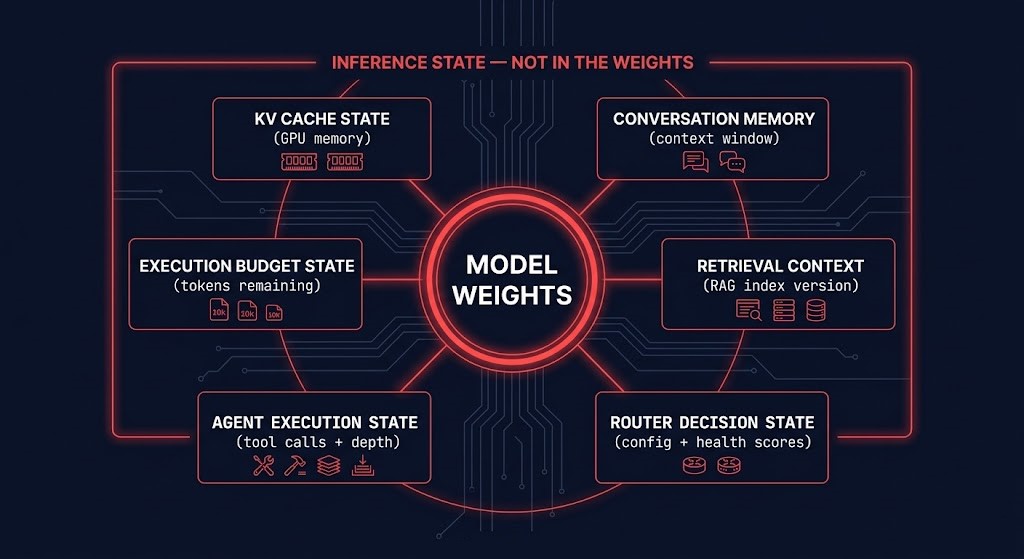
The operational consequence of the Inference State Explosion is most acute during incident response. When a traditional stateless API produces a wrong output, the investigation starts with the request and the application code — both of which are reproducible. When a modern LLM system produces a wrong output, reproduction requires reconstructing: the exact model version that handled the request, the exact prompt template in effect, the retrieval index version that provided context, the router state that selected the model, the KV cache state at the start of the session, and the execution budget remaining at the time of the output. None of this is available from standard infrastructure logs. All of it must be explicitly captured by governance architecture before the incident occurs.
This is why rollback is architecturally harder for LLM systems than for traditional applications — and why the Rollback Without Context failure mode is so common. Rolling back the model weights is the easy part. The weights are versioned, the artifact pointer is clear, the serving framework reloads in seconds. What cannot be rolled back without explicit design is the retrieval index that was serving different context, the prompt templates that were tuned for the previous model’s behavioral characteristics, the router configuration that was routing differently, and the conversation histories that users accumulated during the period when the wrong model version was serving. An LLM rollback that addresses only the weights has solved the smallest part of the problem. The autonomous systems drift analysis maps how state accumulation in inference systems produces behavioral divergence that compounds faster than the governance architecture can track it.
Observability Layer
Standard infrastructure observability was built to answer a binary question: is the system up or down? CPU utilization, memory consumption, network throughput, error rate, request latency — these metrics surface operational failure. They do not surface operational drift. And LLM systems do not fail the way infrastructure fails. They degrade. Slowly, silently, in ways that look like normal variation in metrics that were not designed to detect the signal.
The observability architecture for production LLM systems requires instrumentation at a different layer than infrastructure monitoring — and aggregation at a different level than total spend dashboards. The signals that matter are behavioral and per-workflow, not aggregate and per-resource.
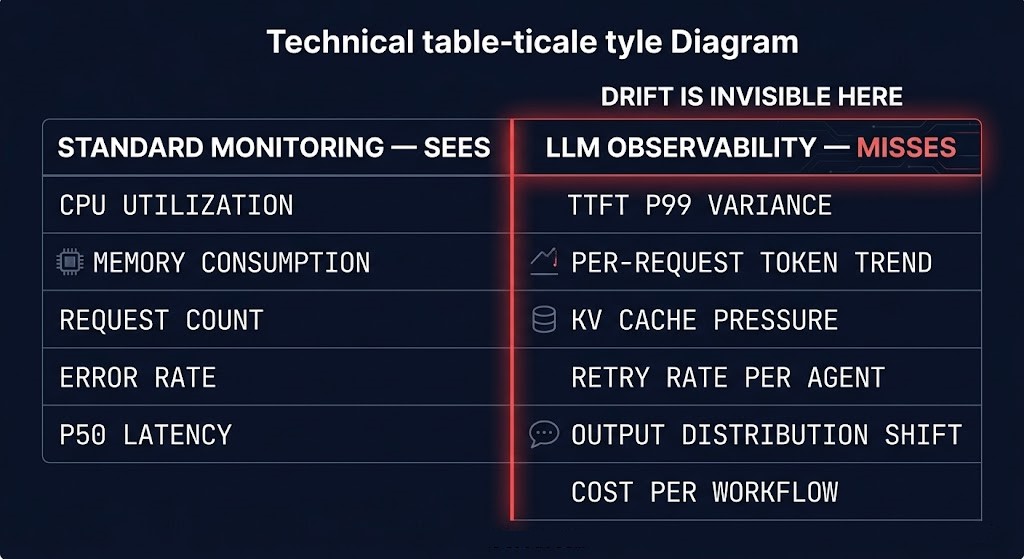
The instrumentation architecture that captures these signals requires decisions made before deployment, not after the first anomaly surfaces. Per-request token consumption must be logged with the request, not derived post-hoc from billing data. KV cache pressure must be exposed as a serving-layer metric, not inferred from latency variance. Retry rates must be tagged with agent and workflow identity at the point of retry, not reconstructed from request logs. Output characteristic distributions must be computed over rolling windows and compared against baselines, not evaluated as individual outliers.
The operational principle is the same one that governs every other observability discipline: you can only detect what you instrument for, and you can only instrument for what you decide to measure before the failure occurs. LLM systems fail through drift, not through crash. Drift is invisible to monitoring designed for crash detection. The AI inference observability architecture maps the specific instrumentation decisions — what to capture, at what granularity, at which layer — that make production drift detectable in time to intervene.
Lifecycle Governance Layer
Model deployment is not an event. It is the beginning of an operational commitment that extends through every update, every behavioral change, every cost deviation, and eventually through the model’s retirement. Most production LLM failures that are attributed to “deployment problems” are actually lifecycle governance failures — the deployment itself succeeded, but the operational processes required to govern what comes after were absent.
The lifecycle governance layer is what makes the difference between a model deployment that is a controlled, auditable, reversible operation and one that creates an operational liability the moment it touches production.
Model versioning in the LLM context extends beyond the artifact registry. The version that matters operationally is not just the weights version — it is the complete operational bundle: weights, prompt templates, system prompts, retrieval index snapshot reference, embedding model version, serving framework configuration, and the test suite and evaluation results that validated that bundle in staging. A version that is not defined at this level of completeness cannot be meaningfully rolled back, cannot be accurately reproduced in a staging environment for incident investigation, and cannot be compared against a previous version in a way that isolates the change being evaluated.
Canary and shadow deployment mechanics are the operational bridge between staging validation and production confidence. Canary deployment routes a defined percentage of production traffic — typically 5–10% — to the new model version while the remaining traffic continues on the current version. The evaluation window must be long enough to capture behavioral signals across representative traffic distributions, not just peak or valley conditions. Shadow deployment runs the new model version in parallel with production — processing every request but not serving its output to users — allowing full output comparison without user exposure. Shadow is the correct pattern when the risk profile of a model update is high enough that canary traffic exposure is not acceptable before validation.
Canary Contamination — the failure mode where a shared retrieval layer is updated during the canary window and contaminates the A/B comparison — is prevented by one operational rule: the canary deployment boundary must encompass all runtime artifacts that influence output, not just the model. If the retrieval index, the embedding model, or the prompt templates are not locked during a canary evaluation window, the evaluation result is not interpretable.
Rollback architecture must be designed before the first deployment, not assembled during the first incident. A complete rollback capability for a production LLM deployment requires four things that are individually insufficient. The artifact pointer must be versioned and revertible — the serving infrastructure must be able to repoint to the previous artifact digest without a full redeployment cycle. The prompt templates and system prompts must be versioned alongside the model, so that rollback restores the operational context the previous model was validated against, not just the weights. The retrieval index snapshot reference must be part of the versioned bundle, so that rollback does not leave the previous model serving against a retrieval layer it was never tested with. And the rollback procedure must be tested in staging before it is needed in production — rollback paths that have never been exercised fail at the worst possible moment.
The lifecycle governance layer is where the long-term entropy of a growing LLM deployment portfolio is controlled. Without it, the governance problems that are manageable at one or two deployed models become unmanageable at ten or twenty — ghost deployments accumulating, rollback paths degrading, shadow routing paths multiplying, and the operational authority over what is actually running in production fragmenting across teams with no unified view of the deployment state. The platform engineering architecture is the organizational infrastructure that makes lifecycle governance scalable — as LLM operations mature into an internal platform capability, the governance layer becomes an IDP concern, not a per-team operational burden.
Decision Framework
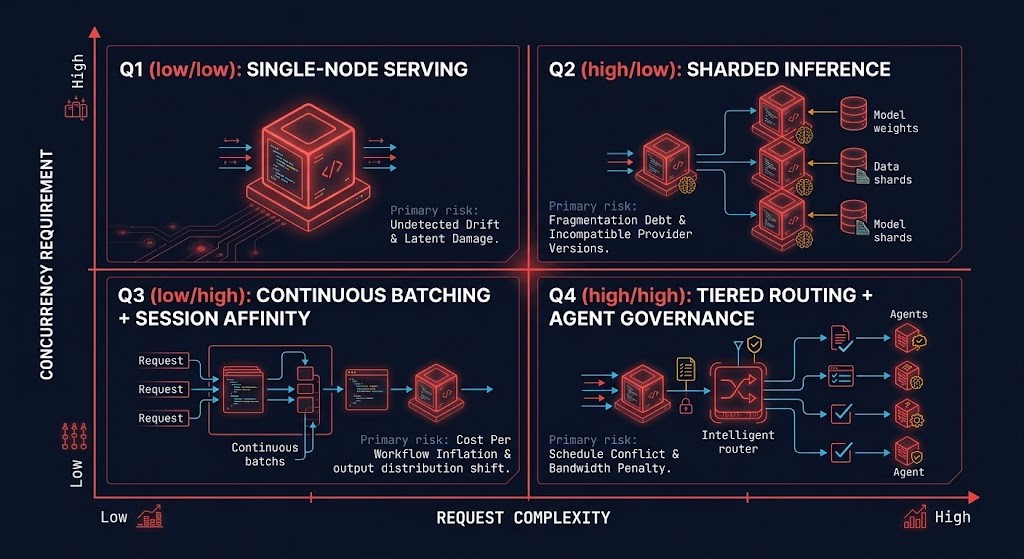
Every LLM operations architecture decision has a right answer for the workload class it is serving. The framework below maps the primary decision dimensions — serving architecture, runtime enforcement requirement, and primary failure risk — against the workload types that enterprise teams operate in production.
| Workload Type | Serving Architecture | Runtime Enforcement Requirement | Primary Failure Risk |
|---|---|---|---|
| Single-turn inference, low concurrency | Single-node serving, vLLM with continuous batching | Token ceiling per request, output validation | KV cache pressure under burst; missing output logging for forensics |
| Multi-turn conversational AI | Session-affinity routing, KV cache locality, persistent memory layer | Context window budget, session state governance | KV Cache Saturation Cascade under high concurrency; Rollback Without Context if session state unversioned |
| RAG-heavy applications | Co-located inference + vector store, retrieval cache layer | Retrieval index versioning, chunk count limits per request | Retrieval Drift Collapse; Canary Contamination if retrieval layer not locked during evaluation windows |
| Agentic and multi-step workflows | Agent orchestration layer with gateway enforcement, tiered model routing | Loop depth limits, tool permission scopes, per-agent token budgets | Invisible token amplification; Runtime Authority Fragmentation during incident response; Shadow Model Routing |
| High-volume batch inference | Async pipeline, dedicated inference endpoints, speculative decoding where applicable | Cost per workflow attribution, throughput vs latency tradeoff governed explicitly | Runtime Budget Drift from unconstrained batch job token consumption; missing per-workflow cost attribution |
| Large model serving (70B+) | Tensor parallelism across multiple GPUs, low-latency fabric required | Fabric P99 monitoring, shard health governance | Fabric-induced TTFT variance; shard state divergence on partial failure; serving cost uncontrolled without tiered routing below it |
| Regulated inference, data sovereignty required | On-premises or sovereign cloud serving, local control plane, no external API routing | Full audit logging, RBAC on all endpoints, no external model calls | Ghost Deployment from incomplete artifact governance; authorization boundary gaps in agentic paths |
Architect’s Verdict
LLM Ops is a discipline the industry is still learning to take seriously. The tooling is maturing faster than the operational practices, which means most teams have the serving frameworks in place before they have the governance architecture that makes those frameworks safe to operate at scale. The result is production AI systems that are technically impressive and operationally fragile — capable of generating high-quality outputs, incapable of explaining what they generated, unable to roll back cleanly when something goes wrong, and accumulating cost and behavioral entropy in ways that only become visible after the damage is done.
The LLM Operations Control Plane is not a product. It is an architectural commitment — to treating model artifacts as governed infrastructure objects, to enforcing execution constraints at the runtime rather than reporting them after the fact, to instrumenting the behavioral signals that matter rather than the infrastructure signals that are easy, and to building lifecycle processes that remain coherent as the deployment portfolio grows.
- [+]Define model artifacts as complete operational bundles — weights, prompts, retrieval reference, serving config, evaluation results
- [+]Enforce token ceilings and execution budgets in the runtime — not in a policy document
- [+]Instrument per-request token consumption, KV cache pressure, and retry rate per agent before the first production deployment
- [+]Treat retrieval index updates as runtime artifact changes subject to the same governance as model deployments
- [+]Test rollback procedures in staging before they are needed in production
- [+]Define explicit permission scopes for agent frameworks — what models they can call, what tools they can invoke, at what depth
- [!]Treat inference as stateless — KV cache, session memory, retrieval context, and router state are all operational state that must be governed
- [!]Roll back model weights without verifying that prompts, retrieval index, and router configuration are also being restored to the validated state
- [!]Let inference cost be a finance problem — enforce token ceilings and loop depth limits in the runtime or they do not exist
- [!]Run canary evaluations while shared retrieval or prompt layers are being updated — the comparison result is not interpretable
- [!]Rely on aggregate infrastructure metrics to detect LLM system drift — instrument at the per-request, per-workflow, per-agent level or drift is invisible until it is expensive
- [!]Deploy agentic inference workloads without explicit tool permission scopes and loop depth enforcement — the runtime authority fragmentation problem gets worse with every agent added to the system
The AI Architecture Learning Path provides the sequenced reading order for architects building the full stack this page sits inside — from silicon and fabric through inference cost architecture to the LLM operations control plane documented here.
You’ve seen how the LLM Operations Control Plane governs production inference systems. The pages below cover the infrastructure layers it sits on top of — and the adjacent disciplines that determine how it operates at enterprise scale.
You’ve Mapped the Control Plane.
Now Find Out Where Yours Has Gaps.
Production LLM systems that lack artifact governance, runtime enforcement, and lifecycle controls look operational until they aren’t. The triage session identifies the specific gaps — in your serving architecture, your execution budget enforcement, or your observability coverage — before a failure makes them visible.
AI Infrastructure Audit
Vendor-agnostic review of your LLM operations architecture — artifact governance gaps, serving infrastructure configuration, runtime enforcement coverage, observability instrumentation, and lifecycle governance maturity. Applicable whether you are deploying your first production model or operating a portfolio of ten.
- > Artifact governance and registry architecture review
- > Runtime enforcement and execution budget audit
- > Inference observability instrumentation coverage
- > Lifecycle governance and rollback architecture
Architecture Playbooks. Every Week.
Field-tested blueprints from real LLM operations environments — inference cost runaway analysis, artifact governance failures, serving architecture post-mortems, and the runtime control patterns that keep production AI systems within operational bounds.
- > LLM Inference Cost Architecture & Runtime Controls
- > Serving Infrastructure & KV Cache Failure Patterns
- > Agentic System Governance & Execution Budgets
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q1: What is LLM operations architecture and how does it differ from MLOps?
A: The LLM Operations Control Plane is the governance architecture that sits above the model and below the application — governing the systems that serve tokens rather than serving them directly. It comprises five layers: Artifact Governance, Serving Infrastructure, Runtime Enforcement, Observability, and Lifecycle Governance. Each layer addresses a distinct operational domain, and gaps in any layer produce specific, predictable failure modes. The control plane’s absence is not visible until a failure makes it expensive.
Q3: Why is inference rollback harder than application rollback?
A: Because the model weights are the smallest part of the operational state that needs to be restored. A complete rollback of a production LLM deployment requires reverting the model artifact, the prompt templates validated against that artifact, the retrieval index snapshot that was in place during validation, the router configuration that was routing traffic during that period, and the serving framework configuration the model was tested against. Rolling back only the weights — which is what most teams do — restores the artifact into an incompatible operational context. Outputs remain degraded. This is the Rollback Without Context failure mode, and it is prevented by treating the complete operational bundle as the versioned unit, not the weights file alone.
Q4: What is the Inference State Explosion?
A: The Inference State Explosion describes the expansion of operational state surface area in modern LLM systems beyond what stateless API governance was designed to handle. Modern inference systems maintain state across at least six dimensions simultaneously: KV cache locality in GPU memory, conversation history and context window state, retrieval context from the RAG layer, router decision history and configuration, agent execution and tool permission state, and execution budget consumption. None of this state lives in the model weights. All of it influences runtime behavior. Incident response, rollback architecture, and observability must all account for the full state surface — not just the model artifact.
Q5: How should inference cost be governed in production LLM systems?
A: As a runtime systems problem, not a finance problem. Inference cost is behavioral — it accumulates through token consumption rates, retry frequency, agentic loop depth, and context window utilization, none of which are visible to standard infrastructure monitoring. The correct governance architecture enforces token ceilings, tiered model routing, retry limits, and agentic loop depth constraints at the inference gateway — before tokens are generated, not after they appear on a billing report. Workflow-level cost attribution, tracked per request and per agent, is the instrumentation model that makes behavioral cost drivers visible before they become quarterly surprises.
Q6: What is the Runtime Authority Fragmentation Problem?
A: The Runtime Authority Fragmentation Problem describes the structural condition of modern LLM systems where runtime authority is distributed simultaneously across six or more domains — router, model, agent framework, retrieval system, policy engine, and serving infrastructure — with no singular execution authority path. When a failure occurs, no single system owns the final execution decision. Replay becomes impossible without reconstructing all six authority domains at the moment of failure. Rollback boundaries blur across system boundaries. Observability fragments across systems none of which has the complete picture. The LLM Operations Control Plane addresses this by creating an explicit audit surface for each authority domain — making execution context reconstructable when it matters.
Q7: When should LLM operations governance become a platform engineering concern?
A: When the deployment portfolio grows beyond two or three active models, or when multiple teams are independently deploying and operating inference workloads. At that point, per-team operational governance creates divergent practices, shadow routing paths, and governance gaps that compound with each new deployment. Platform engineering absorbs LLM lifecycle governance — artifact registry management, endpoint RBAC, execution budget policy enforcement, canary governance — as internal platform capabilities, making governance consistent across teams without requiring each team to build it independently. The platform engineering architecture covers how this transition is structured and what the IDP boundary looks like for inference workloads.