Distributed Inference Survivability Engine
Replica count is not survivability. Surface the dependency chains that fail before your compute does.
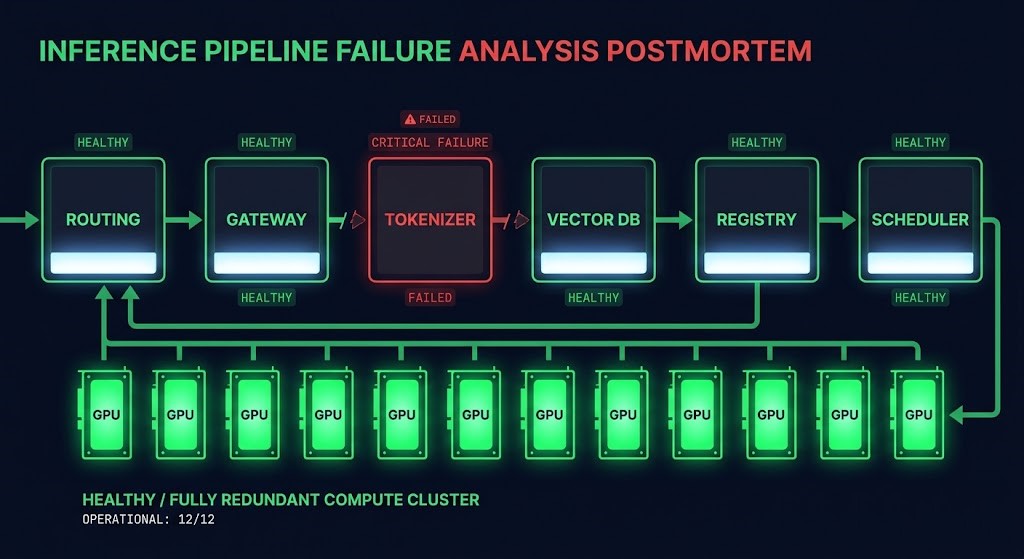
Most distributed inference platforms are designed for infrastructure survivability. A cluster with twelve replicas, redundant gateways, and distributed schedulers can still be operationally unavailable — because the tokenizer is a shared microservice with no fallback, the routing authority is singular, or the model registry introduces an external authority boundary that fails independently of compute. Replica count measures compute redundancy. It does not measure whether a request can be transformed into a response when parts of the architecture fail.
This is the distinction the Distributed Inference Survivability Engine evaluates. The tool assesses the complete dependency chain — routing, gateway, tokenizer, vector DB, model registry, and scheduler — and scores how many critical execution paths remain intact under partial failure. Where standard high-availability assessments stop at replica count and gateway redundancy, this tool evaluates the full set of mandatory dependencies required to move a request through the inference pipeline and produce a response. The primary output, the Inference Survivability Signal, reflects service survivability, not infrastructure survivability — the distinction that separates a defensible production posture from one that only appears resilient under normal operating conditions.
What the Engine Surfaces
01 — Inference Scale
Replica count and routing architecture. Establishes the compute redundancy baseline and the first governance input: whether routing authority is singular or distributed.
02 — Gateway & Routing Redundancy
Gateway redundancy configuration and fallback routing posture. A single gateway collapses all external ingress on failure regardless of what is running internally.
03 — Dependency Chain
The mandatory execution path layer: tokenizer infrastructure, vector DB dependency, model registry dependency, and model shard distribution. These are the components the inference pipeline cannot route around. Failure of any single path breaks the survivability chain regardless of replica count elsewhere in the architecture.
04 — Control Plane & DR Posture
Scheduler redundancy and DR posture for inference operations. The scheduler is an operational authority, not just a compute scheduler — its failure removes placement authority even when replicas remain active.
Inference Survivability Signal
The primary output classifies service survivability across four tiers. The classification reflects dependency chain integrity, not replica count.
Framework #124 — AI Inference Survivability Chain
The doctrinal foundation of the engine. An inference platform remains survivable only when every dependency required to transform a request into a response retains an available execution path. Failure of any mandatory dependency within the chain creates a survivability break regardless of replica count elsewhere in the architecture.
This framework establishes the architectural distinction between infrastructure survivability and service survivability. A cluster with high replica count but singular tokenizer, routing, or registry dependencies has infrastructure redundancy and dependency fragility simultaneously — which is the condition the Governance & Runtime Control layer exists to surface. The Survivability Illusion condition fires when the engine detects high infrastructure redundancy alongside singular dependency chains — the state where replica count actively overstates service resilience.
Key Features
- Deterministic survivability chain scoring: Evaluates six mandatory execution paths — routing, gateway, tokenizer, vector DB, model registry, and scheduler — and scores each independently. Chain integrity displayed as X of 6 paths intact with per-dependency status.
- Survivability Illusion detection: Conditional signal that fires when high infrastructure redundancy coexists with singular dependency chains. Explicitly flags the condition where replica count overstates actual service resilience.
- Inference Degradation Ladder: Rendered as a sequential visual showing how inference capability collapses stage by stage as dependencies fail, based on actual input configuration. The failure sequence is deterministic, not generic.
- Control plane redundancy scoring: Outputs the independent authority path count alongside replica count — the architectural framing that separates governance-aware survivability assessment from standard HA review.
- Client-Side Only: No data leaves the browser. No telemetry, no server-side logging, no account required.
THE ENGINE SURFACES THE SURVIVABILITY BREAK.
A REVIEW MAPS THE REMEDIATION PATH.
The Inference Survivability Signal names where dependency chain failure breaks service delivery regardless of replica count. A distributed inference architecture review maps it to your real topology, routing design, and dependency chain — and identifies the authority boundary changes that move the threshold before a production incident exposes them.
|
>_ Architectural Guidance
Infrastructure Architecture ReviewStructured review of your distributed inference architecture and survivability posture against your production topology, routing design, dependency chain, and failure domains.
|
>_ The Dispatch
Architecture Playbooks. Field-Tested Blueprints.AI infrastructure survivability patterns, dependency chain architecture, and governance frameworks — delivered as field-tested operational blueprints.
Zero spam. Unsubscribe anytime. |
Frequently Asked Questions
Q: What does the Distributed Inference Survivability Engine actually measure?
A: The engine measures service survivability — whether a distributed inference platform can continue transforming requests into responses when parts of the architecture fail. It evaluates six mandatory dependency paths: routing, gateway, tokenizer, vector DB, model registry, and scheduler. Each path is scored independently, and chain integrity is displayed as a count of intact paths. The primary output reflects whether your inference stack can survive partial failure, not whether it has compute redundancy.
Q: How is this different from standard high-availability assessments?
A: Standard HA assessments score replica count, geographic distribution, and gateway redundancy. These measure infrastructure survivability. DISE evaluates the complete execution dependency chain — including tokenizer infrastructure, model registry authority boundaries, and routing control plane architecture. An environment with twelve replicas and a single shared tokenizer microservice scores high on standard HA metrics and fails survivability analysis. The distinction is the architecture of mandatory execution dependencies, not the count of compute nodes.
Q: What is the Survivability Illusion condition?
A: Survivability Illusion fires when the engine detects high infrastructure redundancy — replica count of six or more, redundant gateways, redundant schedulers — alongside singular dependency chains: a shared or external tokenizer, an external model registry, and no fallback routing. This is the architectural state where replica count actively overstates actual service resilience. The condition name reflects the doctrinal point: the infrastructure appears resilient but the service is not.
Q: Is any data sent to a server or stored?
A: No. The engine runs entirely in your local browser session. All logic is client-side JavaScript. No inputs, results, or metadata are transmitted to any server, logged, or stored. Closing the browser tab ends the session completely.
🔒 Privacy Architecture: No cookies. No tracking pixels. No server-side database.
This logic runs entirely in your local browser session.