Recovery Dependency Mapper
Recovery Dependency Risk · Sequence Viability · Recovery Authorities · Order Confidence · Circular Dependencies
Every recovery plan documents a sequence. Almost none of them map the dependencies that sequence depends on. The gap between “we have a recovery order” and “our recovery order is dependency-safe” is where recovery failures actually originate — not at the backup layer, not at the restore layer, but at the moment the first step of the plan assumes a system is available that the dependency graph shows cannot yet be available. Identity assumes DNS is up. DNS assumes the management plane is running. The management plane assumes the hypervisor has recovered. The hypervisor is Step 4. The plan says Identity is Step 1.
The Recovery Dependency Mapper builds a directed dependency graph from your recovery architecture. It runs topological sort to derive the graph-required recovery order, detects circular dependencies via DFS cycle detection, computes path participation to identify where recovery paths concentrate, and scores Recovery Order Confidence using Kendall Tau inversion distance against your declared sequence. What surfaces is not an abstract risk score — it is a specific, evidence-backed statement about where your documented recovery sequence breaks, which node is the recovery gatekeeper everything depends on, and which assumptions the plan cannot survive. This is part of the broader Data Protection Architecture discipline — and pairs directly with the Recovery Readiness Analyzer as the dependency-mapping layer that closes the gap the Analyzer identifies.
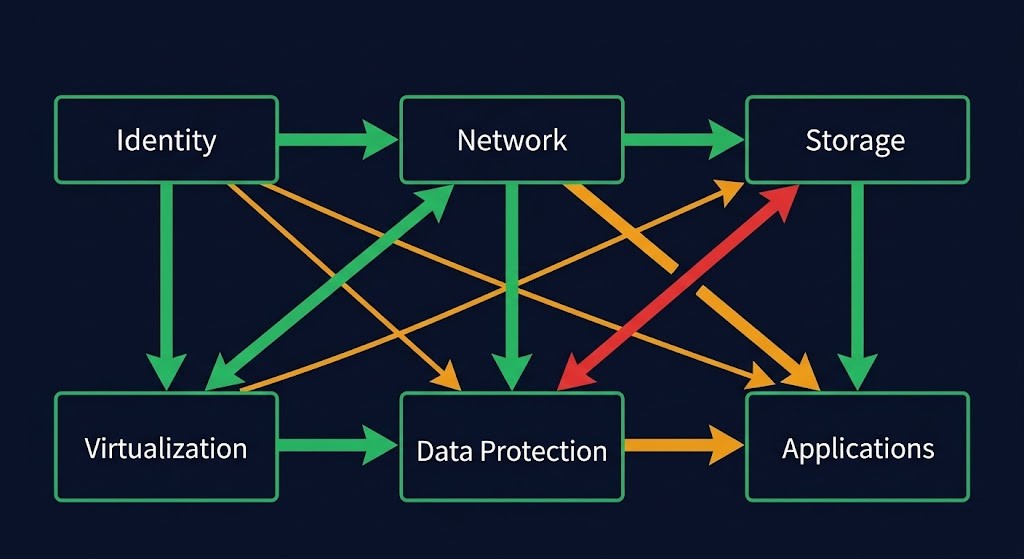
What the Recovery Dependency Mapper Surfaces
01 — Dependency Categories
Six backbone recovery categories — Identity, Network, Storage, Virtualization, Data Protection, Applications — rendered as drag-to-reorder cards. Drag order sets the declared recovery sequence. Configure inter-category dependencies and coupling strength per category. The declared order feeds directly into Recovery Order Confidence scoring.
02 — Critical Dependencies
Add specific systems — Active Directory, DNS, vCenter, Backup Catalog, any recovery-critical service. Select which category nodes and other systems each depends on. Mark recovery authorities explicitly. Block 2 entries become full nodes in the dependency graph alongside the six backbone categories.
03 — Assumption Testing
Three pre-populated baseline assumptions (identity available at recovery start, DNS available at recovery start, management plane available at recovery start) plus free-form user-defined assumptions. Any assumption that conflicts with an edge in the dependency graph surfaces as a named contradiction — plan assertion, graph evidence, and the specific step at which recovery stops.
Output Architecture
All output derives from the dependency graph — no heuristics, no self-reported confidence. Topological sort, DFS cycle detection, dynamic programming longest path, transitive closure, and path enumeration run on submit. The outputs are organized into an executive verdict, a narrative break, and a root cause grid.
Recovery Dependency Risk (RDR)
0–100 composite score weighted across Sequence Viability (25%), Recovery Order Confidence (20%), Dependency Depth (15%), Concentration (15%), Authority score (15%), and Derived Dependencies (10%). Four tiers: Recoverable / Fragile / High Risk / Dependency Spiral.
Recovery Sequence Viability
Four states derived from the graph — Executable, Fragile, Blocked, Unresolvable — based on topological sort success, order confidence, and concentration thresholds. Surfaces alongside RDR as the first question every architect asks: can the sequence actually run?
Chain-Reaction Timeline
Declared recovery sequence rendered as a horizontal node chain. Break points visualized as dashed segments. Nodes colored by state: intact, strained, or broken. Critical recovery path annotated with depth count. On mobile, the timeline stacks vertically.
Recovery Narrative Break
The first sequencing contradiction expressed as two sentences: what the plan assumes, what the graph requires, and at which step recovery stops. “Recovery plan assumes Identity can be restored at Step 1. The dependency map shows Identity requires Network — which is not scheduled to recover until Step 2. Recovery stops at Step 1.” Most DR tools tell you a score. This tells you where the story stops making sense.
Recovery Authorities
Per-node authority score derived from inbound degree, depth from node, and category criticality weight. Four classes: Service / Authority / Critical Authority / Recovery Gatekeeper. The highest-scoring node surfaces as a dedicated Primary Recovery Authority callout — not buried in a table.
Recovery Order Confidence
Kendall Tau inversion distance between your declared category sequence and the graph-required topological order. One transposition scores approximately 93%. Total inversion scores 0%. The declared vs. graph-required sequence is shown side-by-side with mismatches flagged — not just a number.
Derived (Implicit) Dependencies
Transitive edges not explicitly declared, computed via closure over the graph. Severity rated by category boundary crossed — Applications to Identity is HIGH, Data Protection to Identity is CRITICAL. These are the dependencies that appear as recovery blockers because no one mapped them until they became one.
Conditional Overlays
Two overlay states fire above all results when the graph produces a critical failure condition. Both are absent by design when their conditions aren’t met — they are not decoration.
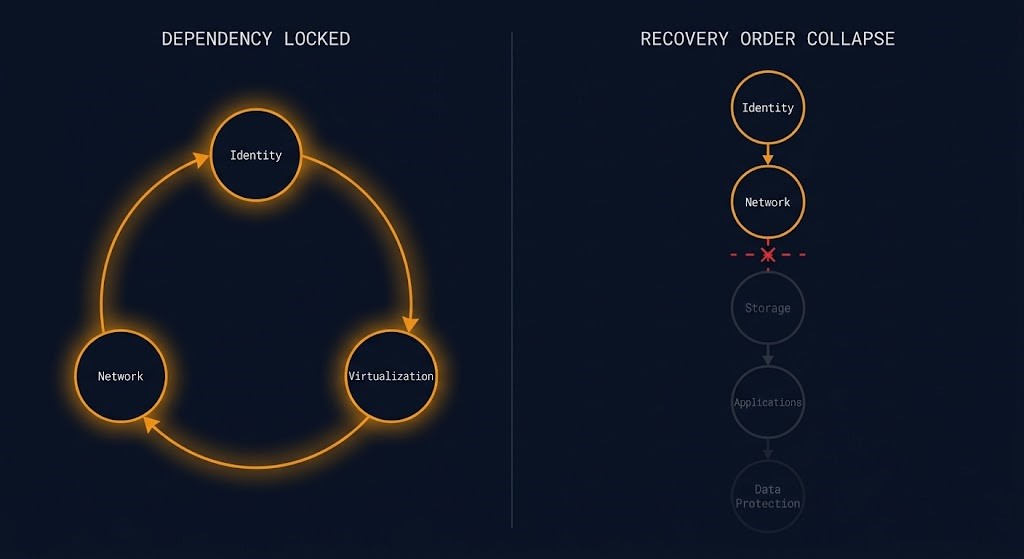
⚠ DEPENDENCY LOCKED
Fires on cycle detection — when a DFS back-edge confirms a circular dependency in the graph. Circular recovery dependencies mean the sequence cannot execute as modeled: Node A requires Node B, which requires Node A. Recovery cannot start.
⚠ RECOVERY ORDER COLLAPSE
Fires when Recovery Order Confidence falls below 25% and Sequence Viability is Blocked or Unresolvable — without a cycle present. The plan is sequentially impossible without containing an explicit circular dependency. This is the more common condition in practice: a coherent-looking plan that cannot execute in the declared order because the dependency structure makes that order impossible.
Recovery Dependency Mapper: Key Features
- Graph-theoretic cycle detection: DFS back-edge detection finds circular dependencies that make recovery sequencing impossible — surfaces the specific cycle path, not just a flag that one exists.
- Kendall Tau Recovery Order Confidence: Inversion distance scoring compares your declared recovery sequence against the graph-required topological order. One transposition ≈ 93%. Not positional matching — pairwise ordering conflict counting across all pairs in the sequence.
- Path participation concentration: Dependency Concentration measures what percentage of all modeled recovery paths route through a single node. Not in-degree ratio — path enumeration across the full graph. “82% of modeled recovery paths require Active Directory” is a finding. “AD has 12 inbound edges” is not.
- Recovery Authority classification: Per-node authority scoring with four named classes (Service / Authority / Critical Authority / Recovery Gatekeeper) and a dedicated Primary Recovery Authority callout card showing path concentration, system dependency count, and failure impact classification.
- Client-Side Only: No data leaves the browser. No telemetry, no server-side logging, no account required. The entire graph engine — topological sort, cycle detection, transitive closure, path enumeration — runs locally in your browser session.
THE MAPPER SURFACES THE DEPENDENCIES.
A REVIEW RESOLVES THEM.
Mapping dependencies identifies where the plan breaks. Closing the gaps requires sequencing recovery authorities, eliminating circular paths, and building a recovery architecture that survives the scenario — not just the drill.
|
>_ Architectural Guidance
Infrastructure Architecture ReviewA structured review against your dependency map findings — identifying the specific sequencing, authority, and isolation gaps the architecture must close.
|
>_ The Dispatch
Architecture Playbooks. Field-Tested Blueprints.Weekly breakdowns of recovery architecture, dependency mapping failure patterns, and the sequencing decisions that determine whether a recovery plan survives first contact.
Zero spam. Unsubscribe anytime. |
Frequently Asked Questions
Q: What does the Recovery Dependency Mapper actually measure?
A: It measures whether your declared recovery sequence is dependency-safe — whether the order systems are planned to recover in is compatible with the dependency relationships between those systems. It also identifies which nodes are recovery authorities, how concentrated recovery paths are through single nodes, and which assumptions the plan relies on that the dependency graph contradicts.
Q: How is this different from a CMDB or dependency documentation tool?
A: A CMDB records dependencies. This tool analyzes them. The mapper runs topological sort to derive the graph-required recovery order, detects circular dependencies that make sequencing impossible, and computes path participation to identify concentration risk. The output is not a dependency list — it is a scored verdict on whether a recovery sequence is executable, and a specific statement about where it breaks.
Q: What recovery environments does the mapper cover?
A: The mapper is architecture-agnostic. It models any environment where systems have dependencies — on-premises, cloud, hybrid, virtualized. The six backbone categories (Identity, Network, Storage, Virtualization, Data Protection, Applications) cover the structural dependency layers present in every enterprise environment. Specific systems are added in Block 2 and modeled as full nodes in the graph alongside the backbone categories.
Q: Is any data sent to a server or stored?
A: No. All graph computation — topological sort, cycle detection, path enumeration, transitive closure — runs locally in your browser. Nothing you enter is transmitted, logged, or stored anywhere. The tool produces no network requests after the initial page load.
🔒 Privacy Architecture: No cookies. No tracking pixels. No server-side database.
This logic runs entirely in your local browser session.