The Manual Nvidia Forgot: A Seasoned Architect’s Guide to AI Training Clusters
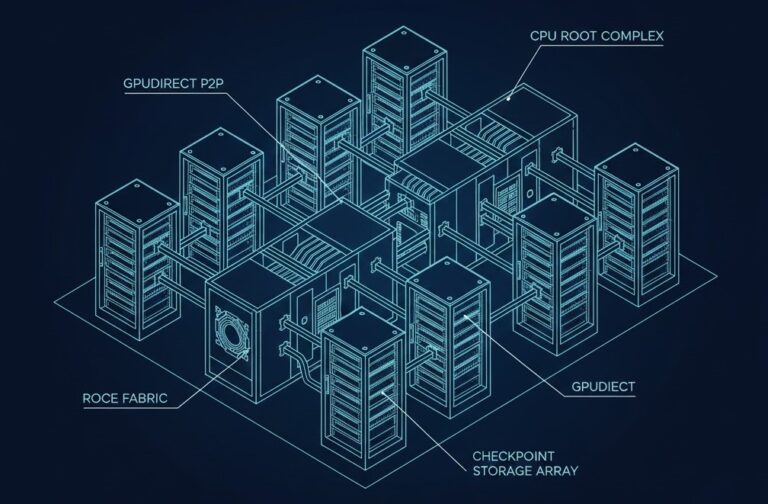
Building a cluster for inference is a weekend project. Building one for distributed training is a war of attrition against physics and “standard” enterprise defaults. After architecting several H100/H200 deployments for private LLM training, the bottlenecks are rarely the GPUs themselves. It’s the infrastructure tax paid for choosing the wrong networking stack, the wrong storage…