IaC Drift Detection: Design for Detection, Not Prevention
Drift is not a tooling failure. It is evidence that multiple control planes still exist.
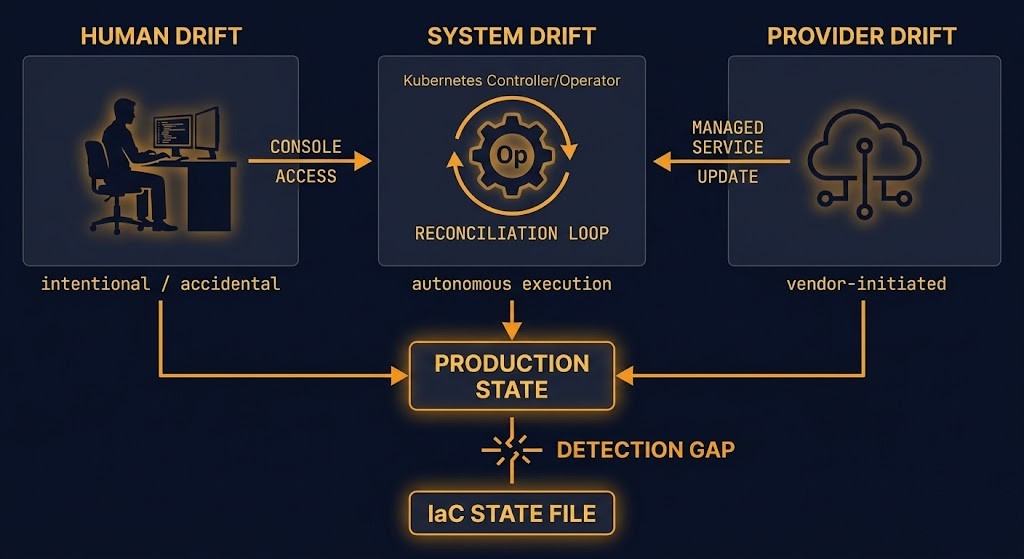
That reframe matters more than any detection tool you deploy. IaC drift detection is typically treated as an operational hygiene problem — a gap in your automation coverage, a sign that engineers are clicking in the console when they shouldn’t be. The real problem is more fundamental. Drift is the observable signal that execution authority over your infrastructure is not fully centralized in your declared control plane. You didn’t lose control of your infrastructure in the moment drift happened. You never had full control. Drift just made that visible.
The Shadow Control Plane argument applies directly here: every environment with console access, autonomous controllers, and managed services has multiple execution authorities operating concurrently. IaC declares one of those authorities. The others don’t disappear because you deployed Terraform.
Why IaC Drift Prevention Fails at Scale
The prevention model assumes that if you build the pipeline correctly, all infrastructure changes route through IaC. This is a reasonable design goal. It is not a reliable operational state.
The console is always accessible. Every cloud provider gives every authorized user direct API access to production infrastructure. IAM policy can restrict this, but it cannot eliminate it — incident response, emergency access, break-glass procedures, and provider support escalations all create legitimate pathways that bypass the pipeline. And that’s before accounting for engineers who use the console for changes that never make it back into source control.
Incidents always produce manual interventions. When your pipeline is down and production is on fire, the engineer with console access makes the change that stops the bleeding. This is correct behavior under pressure. The change is undocumented in your IaC state, and depending on your reconciliation strategy, it may persist undetected for weeks. No operational discipline prevents this pattern — the only architectural response is detection.
Providers mutate state. Managed services evolve their defaults. Kubernetes controllers reconcile toward their desired state on their own schedule. SaaS-managed infrastructure gets updated by the vendor. These are state mutations your IaC never initiated and often has no mechanism to detect. Any architecture that treats prevention as achievable is also treating detection as unnecessary — and those two assumptions together are how drift accumulates silently until it causes an incident.
The Terraform Day 2 operations debt pattern is the long-term consequence: drift that was introduced during incidents, never reconciled, and eventually treated as authoritative production state.
⚠ COMMON MISTAKE
Treating drift prevention as the primary IaC governance objective. Prevention fails during every incident, every provider update, and against every autonomous system operating in your environment. Detection-first architecture acknowledges the reality of production infrastructure; prevention-first architecture ignores it.
The Drift Origin Model
The standard framing of IaC drift collapses all drift into a single category: someone changed something outside the pipeline. This is imprecise in a way that matters for architecture, because it implies a single remediation — enforce the pipeline harder, add approvals, restrict console access.
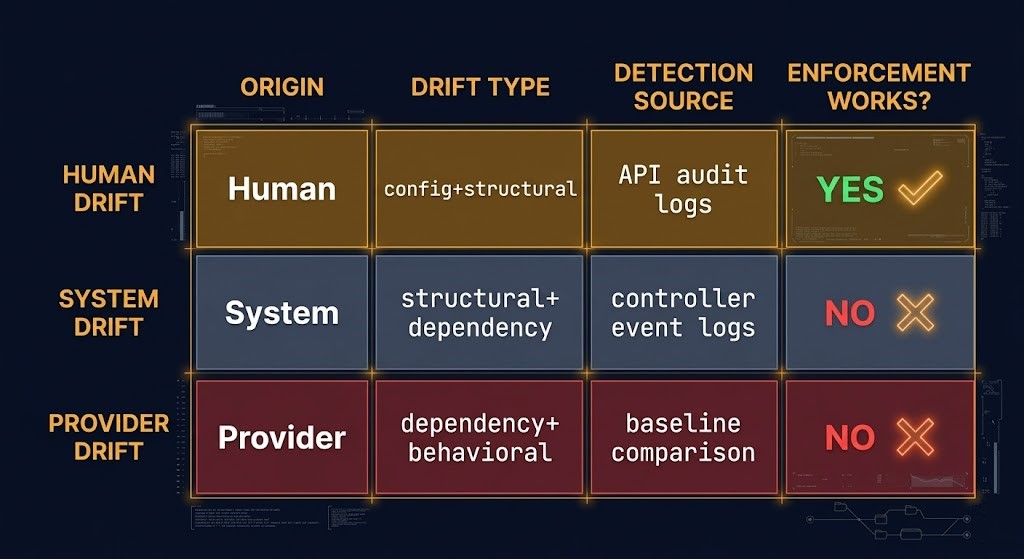
The Drift Origin Model separates drift by its actual source, which is the prerequisite for designing effective detection and response:
01 — HUMAN DRIFT
An engineer runs a local apply against production without going through CI. Someone adjusts a security group in the console during an incident and forgets to update the module. A new team member creates a resource manually while learning the environment. Human drift is caused by people bypassing the declared control plane — intentionally or accidentally. This is the category most IaC governance programs are designed around, and the one that pipeline enforcement, access restrictions, and culture change can actually address.
02 — SYSTEM DRIFT
Kubernetes operators reconcile resource state on their own schedule, sometimes conflicting with your Terraform module definitions. Autoscaling systems modify configuration in response to load. AI-assisted operations and autonomous remediation tooling make changes based on observed system state. Observability agents and service meshes modify network configuration at runtime. System drift is not caused by a person making a decision — it is caused by systems that have their own execution authority operating concurrently with yours. Pipeline enforcement cannot address it. Only detection architecture can.
03 — PROVIDER DRIFT
Cloud provider defaults change. Managed Kubernetes versions upgrade and bring new controller behavior. SaaS vendor updates modify the configuration surface of resources you thought were stable. Regional infrastructure changes affect routing and latency in ways your IaC models as static. Provider drift doesn’t require anyone in your organization to take an action — the infrastructure changes because the provider changed something. It is invisible to detection tools that only compare resource configuration; it requires behavioral baseline tracking.
Mapping your drift incidents to these three origins changes the remediation conversation. If your drift is predominantly Human, enforcement and culture are the right lever. If it is predominantly System or Provider drift, enforcement cannot address it — only detection architecture can. Most environments have all three operating simultaneously, which is why detection must be designed independently of prevention.
IaC Drift Detection Architecture
IaC drift detection requires a detection-first design. The distinction from prevention-hardened architecture is operational: prevention tries to make drift not happen. Detection-first assumes drift will happen and builds the systems that find it quickly and attribute it correctly.
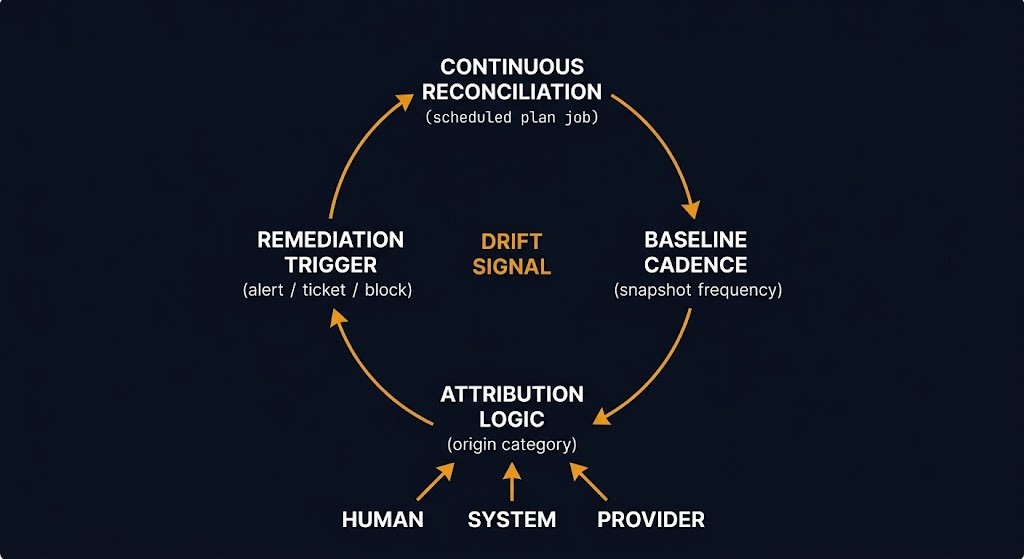
A production-grade iac drift detection architecture has four components:
Continuous reconciliation runs plan operations against live infrastructure on a scheduled cadence — not just as part of a deployment pipeline, but as a standalone detection job independent of any release activity. The output is a delta: what IaC believes the state should be versus what the provider API reports. The delta is the drift signal.
Baseline cadence determines how frequently you snapshot expected state and how long drift can persist before detection. Daily reconciliation catches drift within 24 hours. Hourly catches it within an hour. The right cadence depends on how quickly undetected drift can cause compliance violations, security exposure, or operational failure in your environment. This is an architecture decision, not a default setting to accept.
Attribution logic determines whether you can answer: what changed, when, and from which origin category. Human drift surfaces in API audit logs. System drift surfaces in controller event logs. Provider drift requires cross-referencing your baseline snapshot against provider change logs. Without attribution, you know drift exists but cannot route remediation to the team or system responsible.
Remediation triggers determine what happens after detection: alert only, create a ticket, block deployments, or auto-remediate. Auto-remediation is dangerous when drift was introduced intentionally during an incident — automatically reverting it creates a conflict between your reconciliation system and your operational reality. The right default is alert and attribute. Remediation authority should be explicit and human.
DIAGNOSTIC QUESTION
“When drift is detected in your environment, can you determine within one hour whether it originated from a human action, an autonomous system, or a provider-side change — and route remediation accordingly?”
Drift Without Human Action
Most engineers carry a mental model where drift means someone clicked in the console. Modern infrastructure environments generate significant drift with no human involvement at all, and this category is growing faster than Human drift as autonomous systems become standard infrastructure components.
Kubernetes reconciliation is the most common source. Controllers continuously drive cluster state toward their desired configuration. When a controller’s desired state diverges from what your Terraform module specifies, that is drift — but no person initiated it. Managing this class of drift requires either accepting controller authority over those resources and removing them from IaC scope, or building detection logic that flags controller-initiated changes as reconciliation events requiring review. The agentic AI control plane problem extends this further: autonomous remediation systems that modify infrastructure to resolve anomalies are a new System Drift origin category that most IaC architectures have not accounted for.
Cloud provider managed services evolve continuously. A managed database’s parameter group can change behavior between minor version upgrades. A managed Kubernetes cluster’s admission controller behavior can shift between releases. Your IaC defined the resource. The provider changed how the resource behaves. This is Provider Drift, and it is invisible to detection tools that only compare resource configuration state — it requires behavioral baseline tracking against a reference snapshot.
The implication for detection architecture: your tooling scope must cover all three origin categories, not just Human Drift. A detection system that only catches console changes is solving for one origin while two others accumulate silently.
Where Terraform State Lies to You
Terraform state describes what Terraform believes it owns — not necessarily what production has become.
State file accuracy rests on assumptions that break in real environments. The most significant: every resource Terraform manages was created, modified, and exists exclusively through Terraform operations. In practice, resources are imported incompletely, leaving unmanaged attributes. State files lag behind provider behavior changes. Remote state can become stale between the last successful plan and the current apply. Resources created outside Terraform that depend on Terraform-managed resources create shadow ownership chains that terraform plan doesn’t model.
The terraform plan command is a drift detection tool, but only for resources within Terraform’s declared scope and only as accurate as the state file. Anything outside that scope — manually created resources, provider-managed attributes, system-generated configuration — is invisible. A clean plan result tells you there is no drift within Terraform’s declared perimeter at the moment of the plan. It says nothing about the infrastructure those resources interact with.
⚠ STATE ASSUMPTION
Terraform state describes what Terraform believes it owns — not necessarily what production has become. Plan-in-pipeline detects drift within Terraform’s declared scope. It has no visibility into the infrastructure those resources interact with, the resources created outside its scope, or the provider-side behavioral changes that don’t modify state attributes.
The import blindness problem compounds this. A firewall rule created manually to resolve an incident, pointing at a Terraform-managed security group, never imported into state — is invisible to every plan operation, visible to a full infrastructure audit, and a live security posture gap in the meantime. Teams that rely on plan-in-pipeline as their drift detection architecture are detecting one category of drift while the others accumulate.
Stale reconciliation assumptions are the final layer. Teams that run terraform plan in CI/CD on every merge believe they have continuous drift detection. What they have is drift detection at the moment of each merge, within Terraform’s scope, against a state file that may itself be stale. All three can be independently out of date. Plan-in-pipeline is the correct first layer. It is not the complete architecture.
Detection Tooling Without the Sales Pitch
What plan covers: changes to resources within Terraform’s declared scope, against the current state file, at the moment of the plan. That is a well-defined scope and genuinely useful — if your drift is predominantly Human Drift inside Terraform’s managed perimeter, plan-in-pipeline is a reasonable first layer.
What plan does not cover: resources outside Terraform’s scope, provider-managed attributes not tracked in state, system-generated configuration, behavioral changes in managed services, and anything in your infrastructure that was never imported into state.
For environments running OpenTofu or evaluating the transition from Terraform, state management compatibility directly affects drift detection architecture — the OpenTofu Readiness Bridge covers the migration path and state portability considerations.
The governance principle for tooling decisions: detection tooling earns its place when it extends visibility into drift origins you cannot see with existing tools. Adding a tool that detects the same Human Drift plan already catches is cost, not coverage.
Architect’s Verdict
Drift detection is governance telemetry. Not a config mismatch to clean up. Not an operational nuisance to suppress. Evidence that execution authority bypassed the declared control plane — and that your infrastructure exists in a state your IaC doesn’t describe, your team doesn’t fully know, and your next deployment may override without warning.
The CI/CD pipeline as control plane architecture is only as strong as the detection layer that tells you when something else is also acting as a control plane. Without drift detection that covers all three origin categories, you have a governance model that defends one execution path while blind to two others.
Mature infrastructure teams stop asking whether drift exists. They ask whether uncontrolled authority can persist undetected. That question has a second dimension beyond state: whether the policies being enforced by a fully reconciled control plane still reflect a valid architectural decision — or whether the justification behind them expired silently while the enforcement continued. That gap is what Framework #133 — Policy Intent Drift names.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session