Autonomous Operations Require Infrastructure Most Enterprises Don’t Have
Autonomous operations infrastructure is the conversation the industry is having. The infrastructure maturity required to support it safely is not. Microsoft is shipping autonomous remediation. AWS is building self-healing infrastructure into every operations layer. Every major infrastructure vendor is converging on the same vision: AI agents that operate your environment at machine speed, without waiting for a human to open a ticket.
The industry debate centers on whether AI agents are capable enough to run infrastructure. The more important question is whether the infrastructure is capable of supporting autonomous operators.

The Industry Is Solving the Wrong Problem
The current coverage landscape falls cleanly into three buckets.
The first is vendor marketing: AgenticOps, autonomous remediation, self-healing networks, AI-driven operations. The second is capability debate: can agents reason well enough, can they troubleshoot accurately, can they replace operators. The third is governance discussion: human oversight, approval workflows, AI safety, kill switches.
All three are legitimate conversations. None of them addresses the prerequisite.
Autonomous operations fail for the same reason distributed systems fail — not because the executor is incapable, but because the environment lacks the structural properties required for safe action. A distributed system that operates against incomplete state, without defined consistency boundaries, without clear authority models, does not fail gracefully. It fails in ways that are difficult to predict and difficult to contain.
Giving that same environment an AI agent doesn’t remove the prerequisite. It amplifies the consequences of missing it.
What almost no one is discussing: what infrastructure characteristics must exist before autonomous operations are even feasible?
Human Operators Already Struggle With These Prerequisites
Before evaluating whether an AI agent can run your infrastructure, it is worth asking whether your human operators can.
The five prerequisites for safe operational action are not new. They apply to every operator, human or autonomous. And in most enterprise environments, most of them are either partially defined or actively broken.
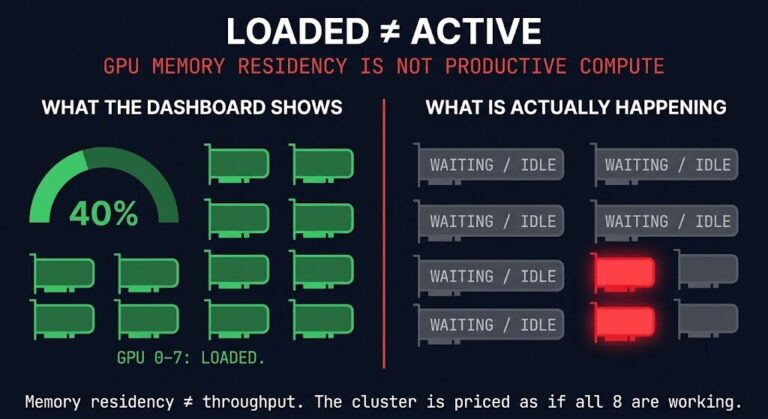
Incomplete or disputed authoritative state. Ask three engineers in the same organization which configuration is correct after a failed change window. You will frequently get three different answers — one from the CMDB, one from what was actually deployed, and one from what someone remembers doing six months ago. Change windows fail not because operators make wrong decisions but because the state they are operating against is unreliable.
Dependency blindness. Undocumented upstream and downstream dependencies are one of the most common causes of cascading failures. The application team doesn’t know about the storage dependency. The network team doesn’t know what the application depends on. The dependency exists. It is just invisible until something breaks it. This is not a rare condition. It is the default state in environments that have grown organically over years.
No recovery sequencing. “We’ll figure it out when we get there” is a recovery strategy in more environments than anyone is comfortable admitting. Recovery sequencing — which systems come back in what order, which dependencies must be satisfied before a service can resume — is frequently undocumented, untested, or both. Even environments with DR plans discover at the moment of failure that the plan doesn’t account for the actual dependency topology.
Undefined authority boundaries. The Console Is the Shadow Control Plane examined this directly. When authority over an infrastructure layer is ambiguous — when it’s unclear whether the platform team, the application team, or the operations team owns a given decision — human operators work around each other. Shadow control planes emerge. Actions happen outside the sanctioned path. The private cloud governance argument rests on the same observation: governance problems are authority problems.
Authority boundaries are also impossible to define for agents the organization hasn’t inventoried. Before autonomous operations can enforce a meaningful authority boundary, there has to be a known set of agents to assign boundaries to. In most environments that prerequisite doesn’t exist — agents arrived through workflow tooling, got classified as automation, and never reached infrastructure awareness. The classification failure that creates this gap is documented in The AI Agent Inventory Gap Nobody Is Measuring.
No escalation threshold. Human operators who encounter uncertainty do something that looks like a failure mode but is actually a safety mechanism: they stop. They open a ticket, escalate to a senior engineer, or defer the action until they have more information. This hesitation is operationally expensive. It is also the primary mechanism that prevents a misdiagnosed condition from becoming a multi-system outage. Most environments have never formally defined at what uncertainty threshold an operator should escalate rather than act.
These aren’t AI problems. They exist in environments run entirely by humans, in organizations with experienced operators who know their systems well. They are infrastructure maturity problems.
Autonomous Operations Infrastructure Readiness — Framework #118
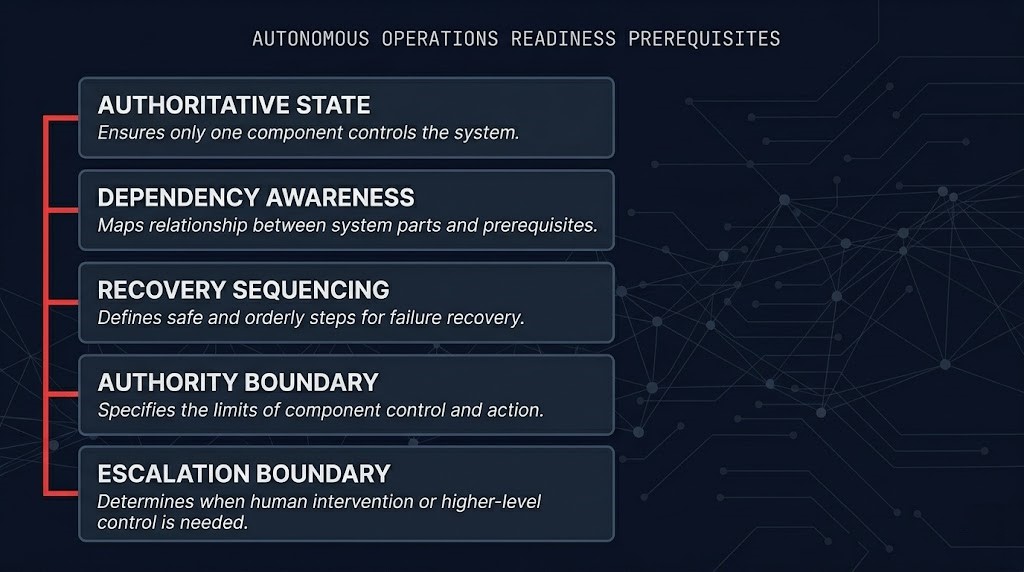
Autonomous Operations Readiness is the degree to which infrastructure state, dependency visibility, recovery sequencing, authority boundaries, and escalation thresholds are sufficiently defined to permit autonomous operational action without creating unacceptable failure propagation risk.
The five requirements that define it:
| Requirement | Human Operator | AI Agent |
|---|---|---|
| Authoritative state | Required | Required |
| Dependency awareness | Required | Required |
| Recovery sequencing | Required | Required |
| Authority boundary | Required | Required |
| Escalation boundary | Required | Required |
The escalation boundary deserves specific attention because it is the requirement that most AgenticOps discussions implicitly discard. Every vendor demo shows an agent that acts until the problem is resolved. Real operations environments require something different: an agent that acts until uncertainty exceeds a defined threshold, then hands off. The escalation boundary is the formal definition of that threshold. It is the point where autonomous operation ends and human judgment re-enters. Without it, “autonomous” means “uncontrolled.”
The Autonomous Operations Readiness Diagnostic surfaces the gaps before deployment:
AUTONOMOUS OPERATIONS READINESS DIAGNOSTIC
- What state is authoritative — and how is conflicts between state sources resolved?
- What dependencies exist — and are they documented well enough to query?
- What actions are reversible — and what is the rollback path for each?
- What blast radius is acceptable — and is it bounded by policy, not assumption?
- At what uncertainty threshold does the system stop acting and escalate?
If an operator cannot answer these questions reliably, an agent cannot answer them either. The agent will make decisions — confidently, at machine speed — using whatever state it can access. The quality of those decisions is bounded by the quality of the infrastructure underneath them.
This pattern has a precedent in the corpus. The same environments that underinvest in governance infrastructure also underinvest in the operational prerequisites that make autonomous action safe — Governance Investment Inversion (#107) describes the same structural failure in a different domain. The investment goes into the visible layer. The prerequisite layer stays underfunded.
The architectural stage where runtime authority boundaries, policy enforcement, and execution governance are modeled as infrastructure requirements — not operational afterthoughts — is Governance & Runtime Control (A6) in the AI Infrastructure Architecture Path.
Why Every Vendor Converges on the Same Architectural Layer
Autonomous systems cannot construct operational state from scratch at runtime. It has to pre-exist.
That one constraint explains why Cisco, AWS, Google, Microsoft, ServiceNow, and every other platform vendor working on autonomous operations are all building toward the same architectural layer: observability, policy, identity, and automation infrastructure. Not because they copied each other’s roadmaps. Because the prerequisite is identical regardless of which agent framework or model runs on top.
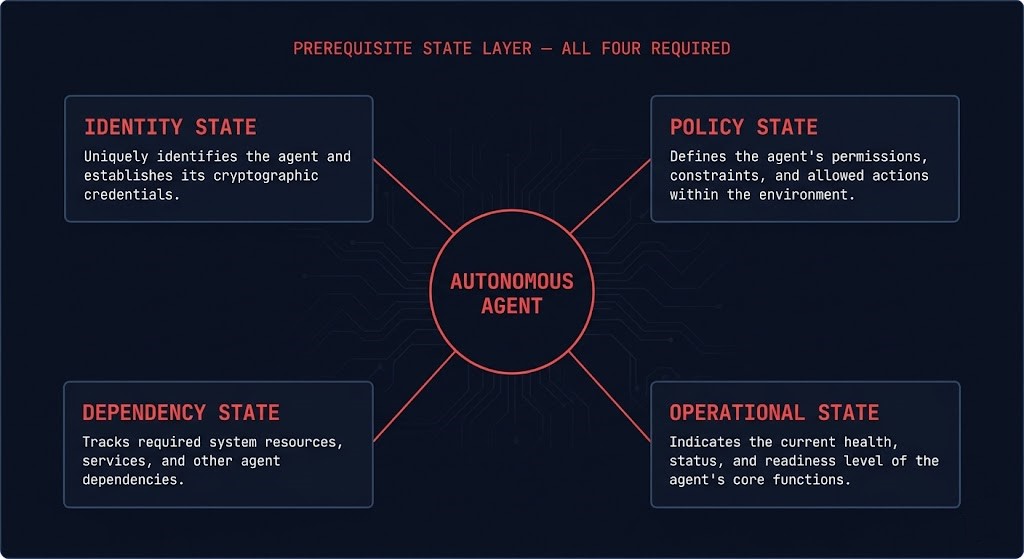
Consider a concrete example. An autonomous remediation workflow receives a signal that a workload is degraded. To decide whether to isolate the workload, the agent needs to know: which team owns this workload (identity state), what policy governs isolation actions in this environment (policy state), which other workloads depend on this one (dependency state), and what the current operational status of the environment is (operational state). Without all four, any action the agent takes is a guess. A high-confidence guess, executed immediately, without hesitation.
That requirement — simultaneous visibility into identity, policy, dependency, and operational state — is why observability platforms are adding automation, automation platforms are adding policy engines, infrastructure vendors are building control-plane overlays above their existing products, and networking vendors are building telemetry-first architectures before they wire in the agent layer. The control plane becomes the substrate.
AgenticOps is not a new category. It is a new consumer of the infrastructure layer that control plane consolidation (#115) and network-as-AI-control-plane (#103) described. Every vendor landing in the same place is not convergence on a product strategy. It is convergence on an architectural prerequisite.
The Real Risk Isn’t Agent Failure
The current risk framing in most enterprise AI discussions focuses on three things: hallucination, bad reasoning, and wrong recommendations. Those risks are real. Infrastructure operators already understand them. They are also largely visible — a wrong recommendation can be reviewed, a hallucinated configuration can be caught before deployment, bad reasoning can be audited.
The risk that gets less attention is high-confidence execution against incomplete state.
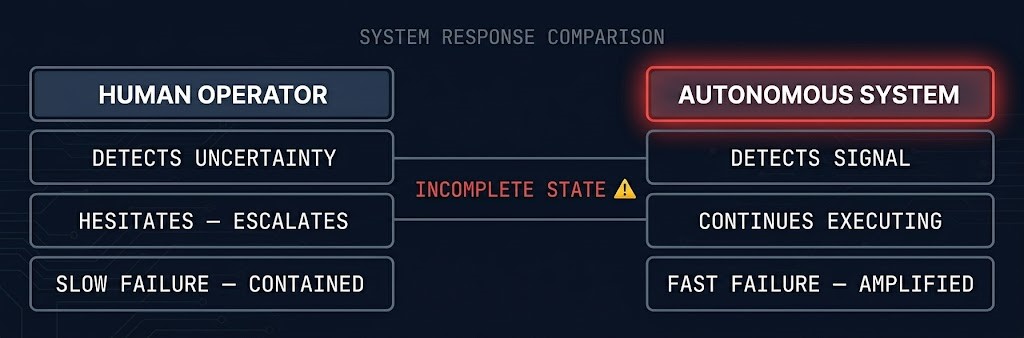
Human operators compensate for uncertainty with hesitation. They ask questions, escalate to a senior engineer, seek additional context, delay action until the picture is clearer. That hesitation is operationally expensive. Change windows run long, incident resolution slows, tickets accumulate. But hesitation is also the mechanism that prevents a misdiagnosed condition from propagating across a production environment. The operator who stops and says “I’m not sure this is right” is, in most cases, preventing a much larger problem.
Autonomous systems compensate for uncertainty differently: they continue executing against the state they have. When that state is incomplete — when the dependency map has gaps, when the authoritative state source is contested, when the observability signals from different planes disagree — the failure is not merely wrong. It is wrong at machine speed and across a wider blast radius than any individual human operator could produce.
⚠ THE RISK MOST EVALUATIONS MISS
The industry worry is: what if the AI makes a bad decision? The more operationally significant risk is: what if the infrastructure doesn’t know enough for any decision to be safe? Bad decisions made by human operators are slow, visible, and reversible. Bad decisions made by autonomous systems are fast, compounding, and executed before the oversight layer has time to engage.
The fear is: what if the AI makes a bad decision?
The bigger risk: what if the infrastructure doesn’t know enough for any decision to be safe?
Fragmented observability compounds this directly. In environments where the monitoring stack says healthy, the application layer says degraded, and the network says normal, human operators at least have the option of recognizing that the signals conflict and escalating for resolution. An autonomous system operating without a defined escalation boundary will continue acting against whichever signal its policy treats as authoritative. The disagreement between signals is not resolved by giving one of them to an agent. It is amplified.
Architect’s Verdict
Most organizations evaluating autonomous operations are asking whether their AI agents are ready for their infrastructure. The more operationally significant question is whether their infrastructure is ready for their AI agents.
Autonomous Operations Readiness requires five things: authoritative state, dependency awareness, recovery sequencing, clearly defined authority boundaries, and a formal escalation threshold. These requirements are not novel. They existed before the first agent framework shipped. They are prerequisites for safe operational action regardless of whether the operator is human or autonomous. What changes when you introduce autonomous systems is not the requirement. It is the consequence of the gap.
AgenticOps doesn’t remove infrastructure complexity. It exposes it — at machine speed, across a wider blast radius, and with a confidence level that doesn’t slow down for the signal conflicts your monitoring stack has been papering over for years.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session