The Restore Path Is the Most Neglected Part of Backup Design
The restore path is where backup architectures fail — not the backup job, not the retention policy, not the storage tier. The path from a completed backup to a verified, production-usable state is the part of data protection design that most teams never model, never test, and discover only under incident conditions.
This is not an operations failure. It is a design omission.
Most architectures are designed to write data — not to get it back.
The Backup Job Is Not the Goal
Most backup architectures are designed around the protection plane — backup jobs complete, retention windows are enforced, replication targets are confirmed. Dashboards go green. SLA reports are generated. The architecture is declared healthy.
None of that measures whether recovery actually works.
A backup job confirms that data was written to a target at a point in time. It tells you nothing about whether that data can be read back under load, whether the application stack can be reconstructed in the correct sequence, whether identity dependencies survive the restore, or whether the recovered state is consistent at the application layer rather than just bootable at the VM layer.
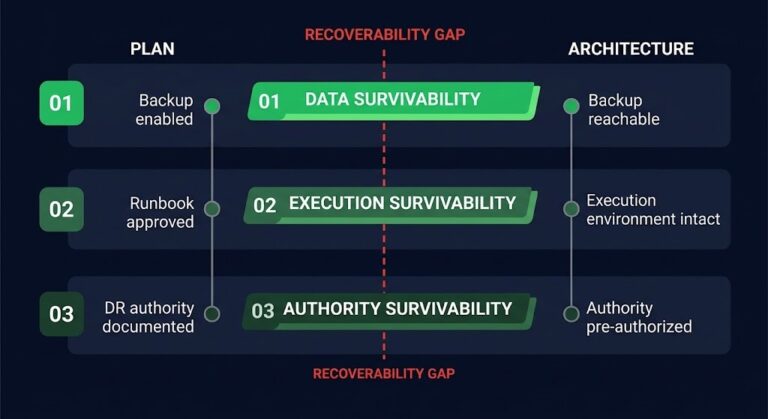
The restore path is the sequence of operations, dependencies, and decision points between a backup completion event and a verified, production-usable recovered state. It is not a single operation. It is an architecture — and most teams have never designed it.
A successful backup proves nothing about your ability to recover.
What the Restore Path Actually Contains
Recovery doesn’t fail in one place. It fails across layers that were never designed together.
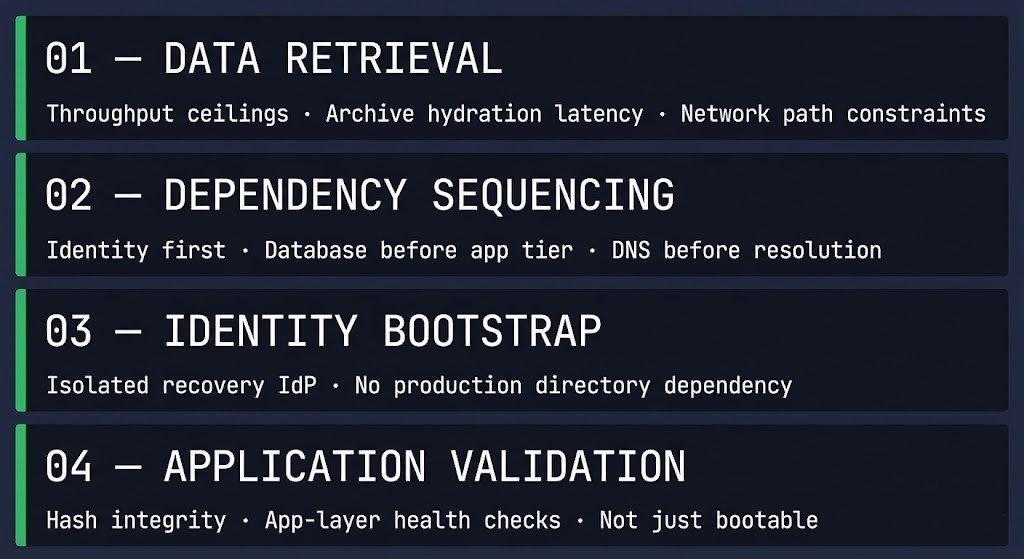
A functional restore path has four layers that must be explicitly designed, not assumed:
Data retrieval. Where does the backup live, how long does retrieval take, and what are the network and hydration constraints at scale? Object storage restore speeds differ from on-premises targets by orders of magnitude. Cloud archive tiers introduce retrieval latency that can turn a four-hour RTO into a 48-hour one. The rehydration bottleneck is real — and it belongs in the design, not the postmortem.
Dependency sequencing. What order do workloads need to come back online? Databases before application tiers. Identity before anything that authenticates. DNS before anything that resolves. Most organizations have never documented this sequence. The engineers who know it are the ones who happen to be on call during an incident — and that is not an architecture. That is institutional knowledge waiting to walk out the door.
Identity bootstrap. If the production identity plane is compromised or unavailable, what does the recovery environment authenticate against? This is the question that stops most recoveries cold. Ransomware operators understand this — they target the identity plane specifically because a workload that cannot authenticate is not a recovered workload. It is a running VM with no access path. The adjacent problem is disaster recovery authority — even with a functioning identity bootstrap, someone has to hold the explicit right to operate the recovery environment, approve the restore sequence, and declare completion. When that authority chain isn’t documented separately from the production identity plane, it often goes down with it.
Application-layer validation. A restored VM that boots is not a recovered application. Application-consistent recovery requires more than a successful backup job — it requires that the restored state is usable at the application layer, not just reachable over the network. Hash validation, restore pipelines, and application-layer health checks must be defined before an incident, not improvised during one.
Why Teams Skip It
The restore path is ignored because it doesn’t produce visible success.
There is no dashboard for “can we actually recover.”
Backup vendors measure protection-plane health because that is what they can instrument. Job completion rates, storage utilization, replication lag — these are real signals about a system that is working as designed. Recovery-plane health requires the organization to design and test it independently. No vendor ships a product that validates your dependency sequencing documentation or your identity bootstrap runbook. That work belongs to the architect.
The result is a discipline where the visible work gets done and the invisible work gets skipped. Recovery drills exist precisely to surface this gap — but most teams treat them as a compliance exercise rather than an architectural stress test. A drill that confirms the backup is readable is not a recovery test. A recovery test proves the entire restore path — retrieval, sequencing, identity, application validation — executes within the declared RTO under realistic conditions.
Backup success is easy to measure. Recovery success requires you to prove your assumptions wrong.

The Restore Path as a Design Constraint
Recovery is not a procedure problem. It is a constraint problem.
Your RTO is not a target. It is the output of constraints you probably haven’t modeled.
Those constraints include retrieval throughput ceilings at your backup target tier, hydration time at scale, network path availability between the recovery environment and the backup source, identity availability in an isolated recovery context, and application dependency ordering that cannot be parallelized. Each constraint has a measurable impact on recovery time. Most organizations have modeled none of them.
The RTO in most DR documentation is not derived from constraint analysis. It is a number someone wrote down during a compliance exercise — unchallenged, untested, and disconnected from the actual physics of the restore path. When the incident arrives, the gap between the documented RTO and the real recovery time is not a surprise. It is the predictable output of skipping the constraint modeling.
The Three-Layer Resilience Model treats recovery as a distinct architectural layer — Layer 3, with its own design requirements and failure modes, separate from backup and DR. The restore path is the operational expression of that layer. If it has not been designed, Layer 3 does not exist regardless of how many backup jobs are completing successfully.
Architect’s Verdict
If your organization has a documented backup architecture and no documented restore path, you have half a data protection design. The backup plane tells you that data exists somewhere. The restore path determines whether you can use it when it matters. Teams that invest in protection-plane completeness without modeling restore-path constraints are not protected — they are insured against a risk they have not actually priced.
The Recovery Readiness Assessment is a starting point for identifying where your restore path has gaps before an incident surfaces them.
Design the restore path with the same rigor you applied to the backup architecture. If you haven’t tested your restore path against real constraints, your RTO isn’t a commitment. It’s a guess.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session