Incident Recovery Process: Why the Incident Isn’t Over After Restore

THE RECOVERY ENGINEERING SERIES

The restore job finished. Systems came back online. The team closed the war room bridge. Someone updated the ticket: Resolved.
They were wrong.
Recovery is not the end of an incident. It is the start of a new, less visible phase of risk — one that most organizations are not structured to see, measure, or close. The incident recovery process doesn’t end when systems come back. It ends when you can prove those systems are trusted again.
Most teams never get there. They stop at restore, call it recovery, and move on. This post is about what happens in the gap they leave behind.
The Core Distinction
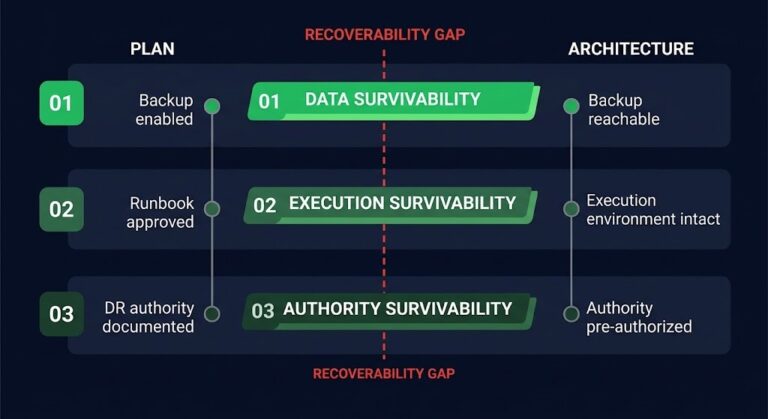
Restore means systems are back online.
Recovery means systems are functioning.
Closure means the environment is trusted, validated, and monitored.
Most organizations stop at Restore. Very few reach Closure.
The Three-Tier Framework: Restore, Recovery, and Closure
Before the mechanics, the language needs to be precise. These three terms are used interchangeably in most organizations. They describe fundamentally different states.
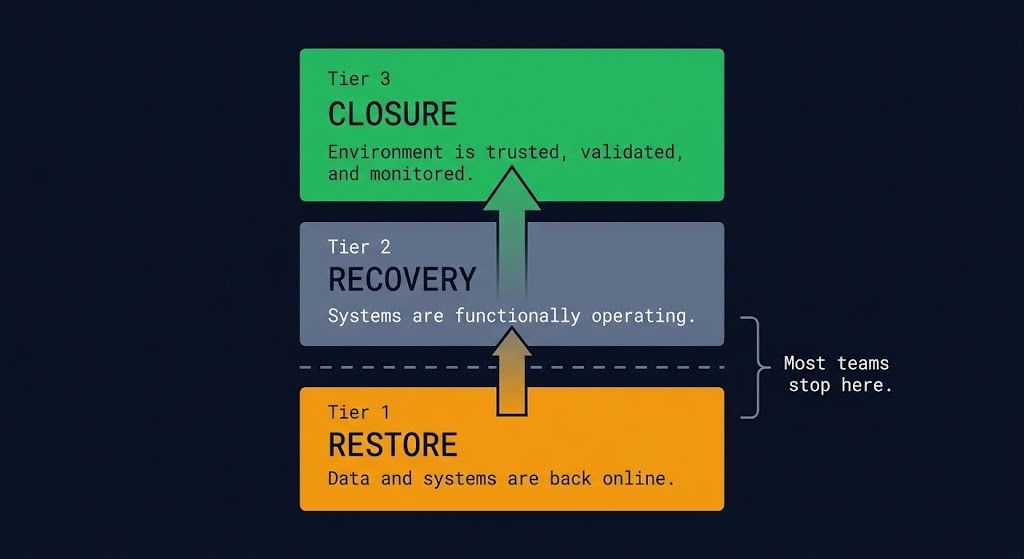
| Tier | State | Definition |
|---|---|---|
| Restore | Operational | Data and systems are back online |
| Recovery | Functional | Systems are operating at expected capacity |
| Closure | Trusted | Environment is validated, trusted, and monitored |
Most organizations stop at Restore and call it Recovery. The systems are running, the monitoring is green, and the pressure to return to normal operations is overwhelming. Very few reach Closure — and the gap between Recovery and Closure is where the next incident is already forming. On the DR side of the pillar, the same gap has its own name and its own dependency map: the Continuity Execution Boundary (#163) treats “the workload came back” and “the business is operating” as the same two-tier split — identity, DNS, certificates, network, control plane, and application continuity are the six places this framework’s Restore-vs-Recovery gap actually gets crossed or missed — the same six domains Cluster 1 of the Disaster Recovery & Failover Architecture stage opens with.
The distinction matters because the risks at each tier are different. At Restore, the risk is data loss. At Recovery, the risk is functional instability. At Closure, the risk is something more dangerous: operating in an environment you haven’t actually validated.
Teams that skip Closure don’t avoid the risk. They defer it — into a future incident that arrives with less warning and more damage than the first. The NIST incident response lifecycle defines post-incident activity as a required phase — not an optional one — yet most recovery runbooks treat it as exactly that.
The Four Phases of the Incident Recovery Process After Restore
Once restore completes, four parallel workstreams need to execute. The critical word is parallel. Under incident pressure, teams run these sequentially because it feels more controlled. It isn’t. Sequential execution extends the window of exposure. These phases fail independently — and they need to be tracked independently.
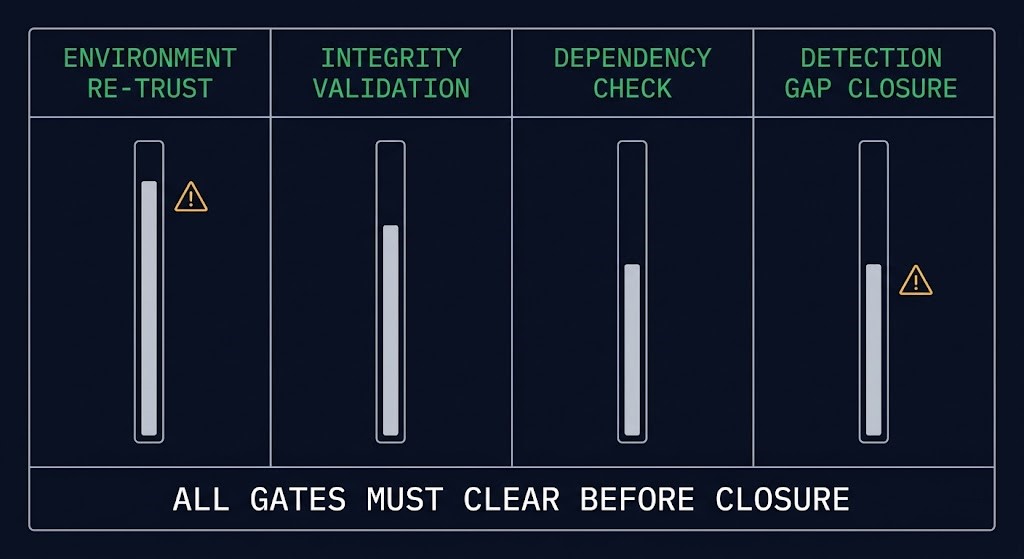
Post-Restore Phases
These phases don’t run in sequence under pressure. They run in parallel — and fail independently.
Environment Re-Trust
Confirm the platform the restore landed on is actually clean — not just assumed clean.
Integrity Validation
Verify restored data is consistent, complete, and application-coherent across dependent systems.
Downstream Dependency Check
Map and reconcile what broke while the restored system was offline — queued jobs, diverged pipelines, accumulated state inconsistency.
Detection Gap Closure
Identify and close the specific detection gap the incident exposed before declaring it closed.
Phase 1 — Environment Re-Trust
This phase comes first not because it is easiest, but because everything else depends on it. If the environment the restore landed in is not clean, validated data on a compromised platform is still a compromised environment.
Environment re-trust means answering a specific set of questions before declaring the platform safe: Are hypervisor and infrastructure layers confirmed clean — not just assumed clean? Has credential rotation completed across all service accounts, admin accounts, and automation tokens that had access during the incident window? Is lateral movement contained and confirmed, not just assumed contained? Has the identity layer been validated independently of the workloads it governs?
Re-trust isn’t just a technical verification — it’s a declaration. Someone has to own the call that the environment is clean enough to proceed. That’s a disaster recovery authority question, not a monitoring question. When authority over that declaration is unclear, re-trust gets assumed by default — which is exactly how reinfection happens.
Most teams treat environment re-trust as implicit. If the restore succeeded, the environment must be fine. This assumption is how reinfection happens — not because backup was compromised, but because the environment it restored into never stopped being compromised.
Phase 2 — Integrity Validation
Data is back. The question is whether the data that came back is the data that should have come back — and whether it’s intact.
Integrity validation is not a hash check on the backup set. It is end-to-end verification that restored data is consistent, complete, and application-coherent across the systems that depend on it. Immutability protects data from modification during storage — it does not validate that the data restored correctly or that application-layer consistency was preserved across dependent systems.
Database restores require transaction log consistency checks. File system restores require structure verification. Application restores require functional smoke testing at the data layer, not just the service layer. Object lock ensures the backup wasn’t tampered with — integrity validation ensures the restore was actually successful.
Phase 3 — Downstream Dependency Check
No system restores in isolation. Every production workload has upstream and downstream dependencies — APIs that consumed its data, services that relied on its availability, pipelines that expected its output during the window it was offline.
The dependency check is the phase most runbooks skip entirely. It requires mapping what broke because the restored system was unavailable — not just what broke as a direct result of the incident, but what accumulated silently in the downstream gap. If you don’t check it, you will find it later — at the worst possible time, in the form of a second incident that traces back to an unresolved dependency from the first. The propagation mechanics of that downstream cascade — how dependency failures chain through systems after the primary restores — is what The Continuity Cascade models.
Phase 4 — Detection Gap Closure
The incident happened. That means your detection capability either missed it, caught it late, or caught it only after damage was done. Most monitoring stacks weren’t designed to see the failure modes that matter — they confirm systems are running, not that systems are behaving correctly.
Detection gap closure means identifying and closing the specific gap the incident exposed before declaring the incident closed. This is the phase that prevents the incident from repeating. It is also the phase most teams defer indefinitely because it requires work that isn’t directly tied to system availability.
The Metrics Your Incident Recovery Process Is Missing
MTTR — Mean Time to Restore — is the metric most organizations track. It measures one thing: how fast systems come back online. It stops measuring the moment the restore job completes.
The problem is that restore completion is not incident closure. The gap between the two has real duration — hours, sometimes days — and most organizations have no instrumentation for it at all. They cannot tell you how long they spent in an untrusted state after restore. They don’t have a metric for it. Which means they can’t improve it.
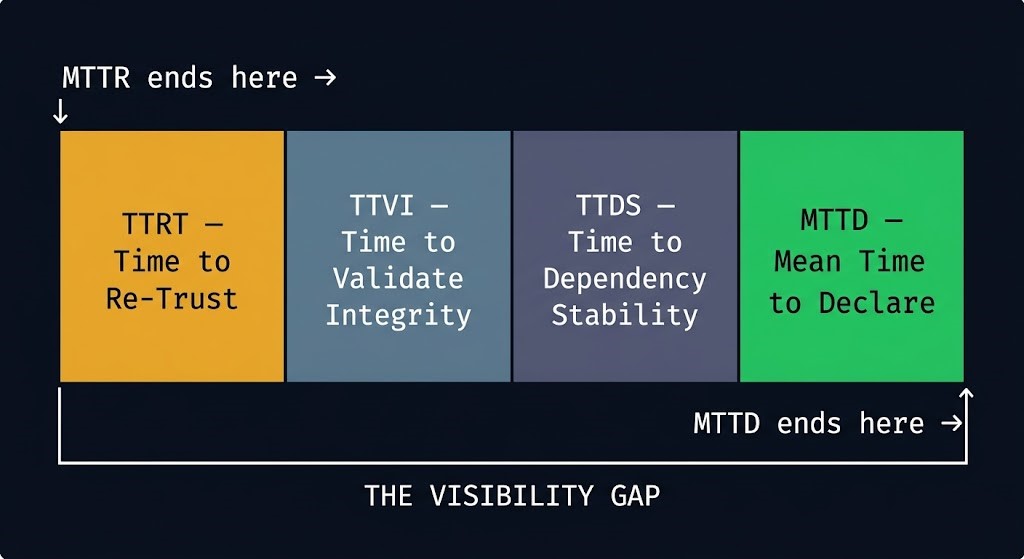
The Post-Restore Metrics Stack
MTTR ends at restore. These metrics cover what comes next — the window most teams leave unmeasured.
TTRT
Time to Re-Trust
Restore completion → confirmed environment trust
TTVI
Time to Validate Integrity
Restore completion → confirmed data integrity across all dependent systems
TTDS
Time to Dependency Stability
Restore completion → confirmed downstream dependency reconciliation
MTTD
Mean Time to Declare
Total elapsed time from restore completion to formal incident closure — the sum of all three
A note on naming: Mean Time to Declare (MTTD) should not be confused with Mean Time to Detect, which measures the time to identify an incident before response begins. MTTD here measures the time between restore completion and formal incident closure — the phase that comes after detection and response are complete.
You don’t have a recovery metric problem. You have a visibility gap between restore and closure. MTTD makes that gap measurable. The rehydration bottleneck affects RTO — the time to get data back. The metrics above affect something different: the time to know that what came back is trustworthy. Both matter. Only one gets tracked.
Runbook vs. Reality
Every mature organization has a recovery runbook. Most recovery runbooks end at the same place: Restore confirmed. Service restored. Incident closed.
The problem is that runbooks are written for expected failures. Incidents are defined by unexpected ones. The gap between where the runbook ends and where the incident actually ends is not a documentation failure — it is a reflection of what organizations have decided to make visible and what they have chosen not to see.
A runbook that ends at “restore successful” documents the easiest part of the incident. The hard part — the validation, the re-trust, the dependency reconciliation, the detection gap closure — happens in the space after the runbook ends, under time pressure, with no defined process and no assigned owner.
That is not a recovery process. That is hope dressed as procedure.
The fix is not to write a longer runbook. It is to define what incident closure actually requires — and make the post-restore phases as procedurally explicit as the restore itself. Designing for an adversary that knows your playbook means extending the playbook past the point where most teams stop reading it. CISA’s incident response guidance explicitly frames post-incident activity as a structured phase with defined outputs — not a wind-down period.
The Six Gates of Incident Closure
Incident closure is not a feeling. It is not the absence of alerts. It is not the ops team declaring victory because the monitoring dashboard is green. It is a set of specific, verifiable conditions — all of which must be true before the incident is formally closed.

The Six Gates of Incident Closure
All six gates must clear before the incident is formally closed. One open gate means the incident is still active.
Environment Trust Established
Infrastructure layer confirmed clean; lateral movement contained and verified.
Identity Integrity Verified
Credential rotation complete; no orphaned tokens or service accounts from the incident window.
Data Integrity Confirmed
Application-layer consistency verified across all dependent systems.
Dependencies Stabilized
Downstream systems reconciled; no accumulated state divergence from the outage window.
Monitoring Revalidated
Observability stack confirmed operational and scoped correctly post-restore.
Detection Gap Closed
Root cause identified; specific detection gap from this incident addressed before closure is declared.
Each gate is a standalone condition — verifiable, assignable, and binary. Either the gate clears or it doesn’t. The incident closure decision is not a judgment call. It is the output of six gates, all of which must clear. CIS Controls for incident response management align closure verification to specific control outputs — not to system availability signals.
If your organization cannot answer the verification question for each gate, you are not ready to close the incident. You are ready to resume operations in uncertainty — which is a different thing entirely.
Recovery Readiness Assessment
The Recovery Readiness Assessment evaluates your organization’s posture across these six dimensions before an incident forces the question.
Run the Assessment →Where Incidents Re-Open
The most expensive incidents are not the ones that are never resolved. They are the ones that are declared resolved — and then re-open.
Re-opening happens in specific patterns, and they are almost always traceable to one of the six gates failing silently.
Reinfection after restore. The most common pattern. The restore was clean. The environment it restored into was not. Ransomware recovery time is an architecture problem — and the architecture problem is usually that re-trust was assumed, not verified. The threat actor was still present. The restore gave them fresh data to encrypt.
Latent persistence. Not every compromise announces itself at restore time. Some persistence mechanisms survive the restore window entirely — living in layers the restore process doesn’t touch: firmware, hypervisor configuration, identity provider state, network device configuration. Systems look clean at restore. They aren’t.
Missed indicators. The incident was declared closed before the detection gap was addressed. A new indicator of compromise arrived two weeks later — one that the gap would have caught if it had been closed. Backups are compromised first precisely because attackers know the recovery path. Leaving the detection gap open gives them a second window.
Partial validation. Integrity validation passed on the primary systems. It didn’t run on the secondary systems, the development environment that shares credentials, or the backup catalog itself. The partial validation created a false sense of closure. The unvalidated systems were the re-entry point.
Most “resolved” incidents fail quietly before they fail visibly again. The pattern is consistent enough that it should be treated as a design constraint: if you cannot verify all six gates, the incident is not closed — it is on pause. How far a system degrades across those unvalidated layers before recovery becomes structurally impossible is what The Degradation Ladder models.
Architect’s Verdict
A successful restore is not a success condition. It is a transition point.
The restore got your systems back. It did not get your environment back. It did not close the detection gap. It did not validate integrity across your dependency graph. It did not verify that the platform the restore landed on is actually trustworthy. Those things require a separate, explicit process — one that most organizations have not built and most runbooks have not defined.
If you cannot prove the environment is clean, you have not recovered. You have resumed operations in uncertainty.
The incident isn’t over when systems come back. It’s over when you trust them again — and can prove why.
- ✓ Define explicit closure criteria before an incident happens
- ✓ Track MTTD alongside MTTR as a formal recovery metric
- ✓ Run all four post-restore phases in parallel — they fail independently
- ✓ Verify environment trust independently before validating restored data
- ✓ Treat all six closure gates as binary — cleared or not cleared
- ✓ Extend your runbook past “restore confirmed” into explicit post-restore procedures
- ✗ Declare closure when monitoring turns green
- ✗ Stop measuring when the restore job completes — MTTR ending is not incident closure
- ✗ Execute post-restore phases sequentially because it feels more controlled
- ✗ Assume the restore environment is clean because the backup was clean
- ✗ Use judgment calls to declare closure under pressure
- ✗ Let the hard part of the incident happen in the space after the runbook ends
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session