AI Placement Decisions Are Architecture, Not Optimization

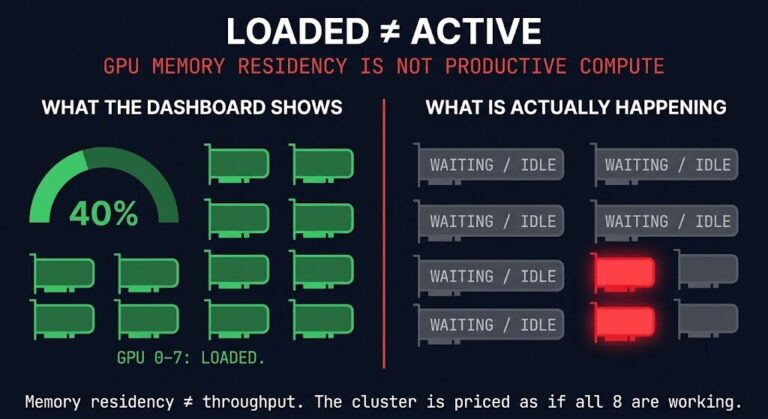
AI placement latency is not the problem most teams think they are managing. The default framing treats it as an optimization variable — pick the cheapest compute that meets the SLA, centralize inference, optimize for utilization, revisit locality later when the architecture matures.
That framing is wrong in a way that compounds over time. AI placement decisions are not continuously reversible optimization choices. They are architectural commitments that harden incrementally — through inference path configuration, data gravity, routing dependencies, and runtime behavior that normalizes around whatever topology you chose first. By the time latency SLAs begin failing, the placement topology is already embedded across routing, observability, and application behavior. The remediation cost is not an optimization exercise. It is a re-architecture.
The First Optimization Becomes the Permanent One
Cost is the default optimization axis for AI placement decisions. Centralized GPU clusters are cheaper to operate per token than distributed inference endpoints. Utilization density justifies centralization on paper. Procurement processes reward it. FinOps tooling measures it.
So teams centralize. They optimize the compute economics. They defer locality decisions to a later phase when requirements are better understood. That later phase rarely arrives before the architecture has already made the locality decision implicitly — through the inference paths that were built against a centralized endpoint, the data gravity that formed around it, and the application behavior that normalized against the latency profile it produced.
The pattern this creates is latency debt: accumulated runtime latency overhead that results from placement decisions that optimized for cost before locality requirements were operationally visible. Latency debt behaves like technical debt — it accrues gradually, stays invisible until something triggers it, and is significantly more expensive to resolve after the fact than it would have been to avoid at design time.
The critical difference from generic technical debt is the trigger. Latency debt in AI systems does not surface as a clean breakage. It surfaces as degraded user experience, SLA misses in specific workload paths, and inference timeout increases that appear in observability without an obvious architectural cause. By the time the signal appears, the placement topology that created it is already deeply embedded.
Inference Latency Is a Topology Property, Not a Model Property
The most common operational misread of AI placement latency problems is attributing them to the model. The model is slow. The model needs more compute. The model needs to be replaced with a faster variant. In practice, the model is rarely the bottleneck.
Inference latency is an architecture property. It is the cumulative result of every hop in the inference path — and inference latency is rarely additive. It compounds.
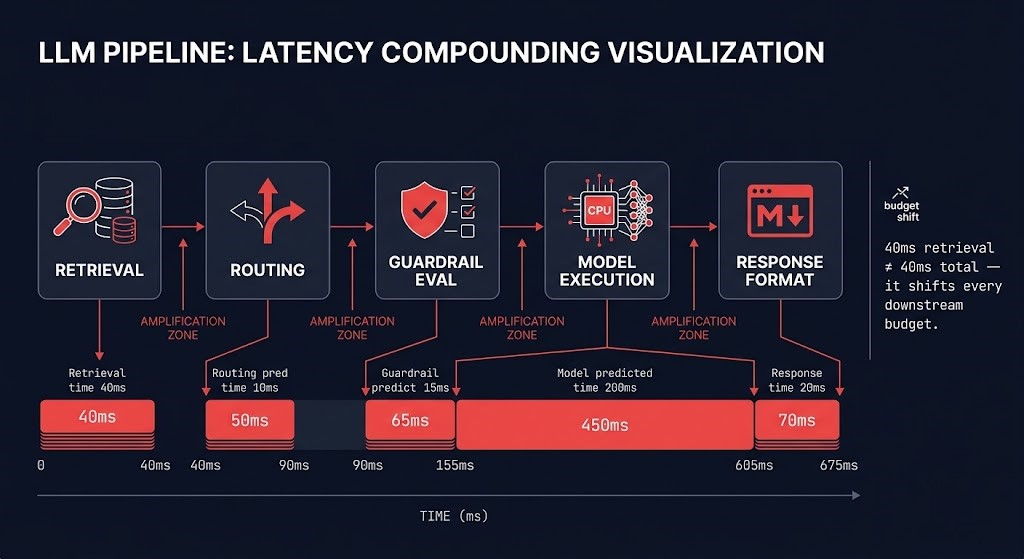
A prompt enters the inference path and traverses: authentication validation, routing layer evaluation, retrieval augmentation (vector search, document fetch, context assembly), guardrail pre-processing, model execution, guardrail post-processing, response formatting, logging pipeline. Each of these steps has a latency budget. Each of those budgets is shaped by placement decisions — where the retrieval system lives relative to the inference endpoint, where the guardrail engine lives relative to the model, where the routing layer lives relative to both.
Multi-stage AI pipelines compound latency across retrieval, routing, guardrail evaluation, model execution, and response formatting such that small placement decisions create disproportionately large runtime effects. A 40ms retrieval latency in a RAG pipeline is not simply 40ms added to total inference time. It shifts the guardrail evaluation window. It changes the timeout behavior of downstream orchestration. In a multi-model chain where one model’s output is the next model’s input, that 40ms propagates and amplifies at each stage. The latency profile of the full pipeline is not the sum of its parts. It is the product of its topology — and the ceiling on what that topology can deliver is set at the accelerated compute layer, before any pipeline hop is added.
The fabric constraints that determine that ceiling — east-west bandwidth, oversubscription, congestion domains, and the Execution Locality Boundary — are the subject of the Fabric Architecture stage of the AI Architecture Learning Path.
This is what makes AI placement decisions architecturally consequential rather than operationally tunable. You cannot fix compounding latency by optimizing a single hop. The topology itself has to change.
Some Workloads Tolerate Distance. Others Collapse Under It.
Not all AI workloads have the same placement sensitivity. The classification that matters for placement decisions is not by model size or compute requirements. It is by runtime latency tolerance.
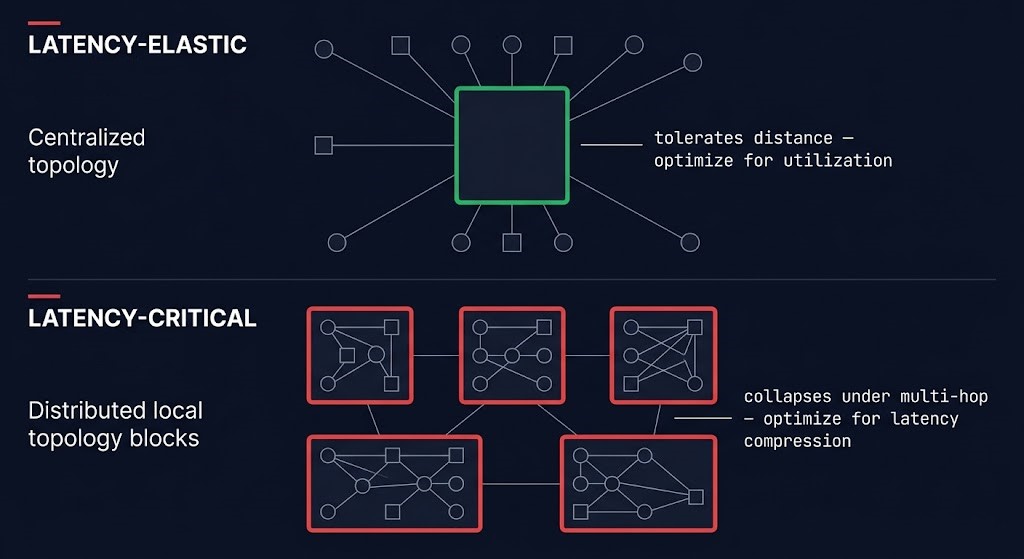
Latency-elastic workloads tolerate placement distance without operational degradation. Batch inference jobs, asynchronous enrichment pipelines, offline document processing, scheduled analysis runs — these workloads have no real-time user at the end of the inference path. Centralized compute with optimized utilization is the correct architecture. There is no latency debt risk because there is no latency SLA that distance can violate.
Latency-critical workloads collapse under multi-hop inference topology. Real-time conversational interfaces, live decision systems, agentic workflows with synchronous tool calls, low-latency retrieval-augmented generation serving user-facing applications — these workloads have a latency cliff. Below it, the application functions as expected. Above it, user experience degrades faster than the underlying metrics suggest.
| Workload Type | Placement Tolerance | Architecture Target |
|---|---|---|
| Latency-elastic | Tolerates distance | Centralized compute — optimize for utilization |
| Latency-critical | Collapses under multi-hop | Local or distributed — optimize for latency compression |
The placement failure pattern is systematic: latency-critical workloads get assigned to centralized infrastructure because that is what procurement and capacity planning optimize for, and the latency sensitivity is not visible until the workload is under production load. By that point, the path dependencies that make the topology expensive to change are already in place.
The workload classification should happen before placement decisions are made — not after performance problems surface. The question is not “can this workload tolerate this latency profile?” It is “what happens to this workload’s runtime behavior when latency compounds across five hops instead of one?”
The Placement Decision You Can’t Retrofit
Mature AI platforms increasingly optimize for latency compression rather than raw compute efficiency — reducing cumulative runtime distance across the entire inference path, not just accelerating model execution. This is the architectural answer to AI placement latency debt: co-locating retrieval systems with inference endpoints, placing guardrail evaluation in the inference serving layer rather than as a remote call, and building routing logic that understands placement topology as a variable in model selection.
The reason latency compression is hard to retrofit is not technical. The underlying changes are architecturally tractable. The reason is that every system built against the original centralized topology has normalized its behavior around that topology. Application timeout budgets were set against it. Retry logic was calibrated to it. SLAs were established with it as the baseline. Observability dashboards were built to measure it.
Retrofitting placement means changing the topology and then reconciling every downstream dependency that formed against the original one. The inference paths themselves are not the hard part. The accumulated runtime expectations are. The cluster orchestration layer is where placement authority becomes structurally enforceable — where scheduler configuration, admission policy, and resource governance translate placement decisions into runtime constraints before those dependencies harden. That layer is covered in the Runtime & Cluster Orchestration stage of the AI Architecture Learning Path.
The storage and pipeline layer where that retrofit cost concentrates — checkpoint architecture, retrieval locality, and data delivery constraints — is covered in the Storage & Data Pipeline Architecture stage of the AI Architecture Learning Path.
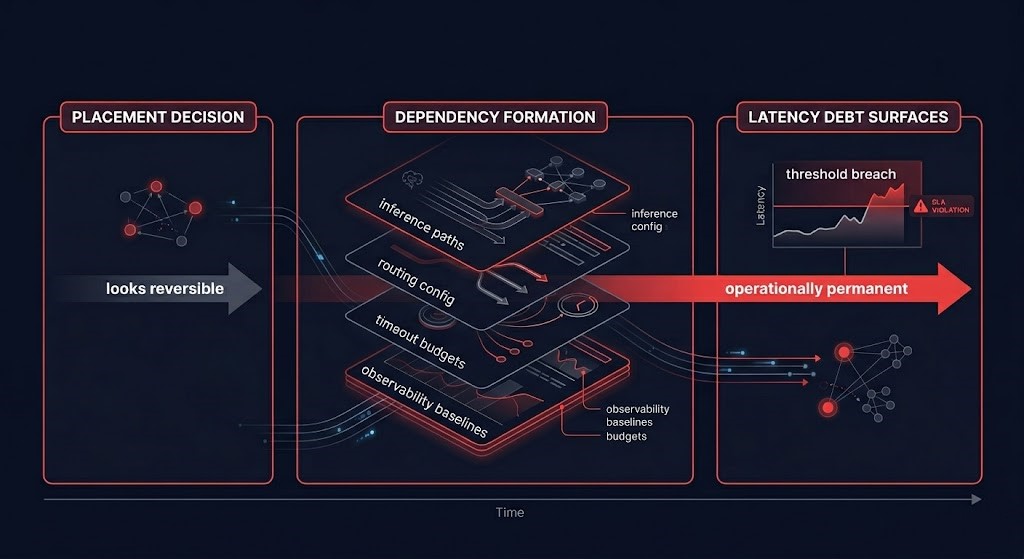
This is the irreversibility that makes AI placement a first-class architecture concern rather than an operational tuning parameter. The decision looks reversible during design because the dependencies have not yet formed. It becomes operationally permanent once runtime behavior hardens around it — not through any single locked-in component, but through the aggregate of normalized behavior that rebuilding the topology would require unwinding.
Architect’s Verdict
Inference latency is not a model property. It is a topology property — the cumulative result of every placement decision made across retrieval, routing, guardrail evaluation, model execution, and response handling. Those decisions compound nonlinearly. A 40ms retrieval latency is not 40ms added to total inference time in a multi-stage pipeline. It shifts downstream budgets, amplifies through chained model calls, and surfaces as SLA misses that appear unrelated to their architectural cause.
Latency debt is what accumulates when cost-first placement decisions defer locality requirements to a later phase that arrives after the topology is already embedded. It is invisible during the deferral period, expensive to diagnose once it surfaces, and significantly more expensive to remediate than it would have been to avoid. The organizations that end up with latency debt are not the ones that made a bad optimization decision. They are the ones that did not recognize placement as an architectural commitment at the time they made it.
AI placement decisions look reversible during design. They become operationally permanent once runtime behavior hardens around them.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session